

- 기존 궤적의 전체 데이터셋에 대한 평가보다 시작하기 쉬움
- 초기 쿼리부터 성공 또는 실패 해결까지의 엔드투엔드 커버리지
- 앱의 여러 반복에 걸쳐 반복적인 동작이나 컨텍스트 손실을 감지할 수 있는 능력
 이 가이드는 오픈소스
이 가이드는 오픈소스 openevals 패키지를 사용하여 다중 턴 상호작용을 시뮬레이션하고 평가하는 방법을 보여줍니다. 이 패키지에는 AI 앱을 평가하기 위한 사전 구축된 evaluators 및 기타 편리한 리소스가 포함되어 있습니다. 또한 OpenAI 모델을 사용하지만 다른 제공업체도 사용할 수 있습니다.
Setup
먼저 필요한 종속성이 설치되어 있는지 확인하세요:패키지 매니저로
yarn을 사용하는 경우, openevals의 peer dependency로 @langchain/core를 수동으로 설치해야 합니다. 이는 일반적인 LangSmith evals에는 필요하지 않습니다.시뮬레이션 실행
시작하는 데 필요한 두 가지 주요 구성 요소가 있습니다:app: 애플리케이션 또는 이를 래핑하는 함수. 단일 채팅 메시지(role과 content 키가 있는 dict)를 입력 인자로 받고thread_id를 kwarg로 받아야 합니다. 향후 릴리스에서 더 많은 것이 추가될 수 있으므로 다른 kwargs도 받아야 합니다. 최소한 role과 content 키가 있는 채팅 메시지를 출력으로 반환합니다.user: 시뮬레이션된 사용자. 이 가이드에서는 LLM을 사용하여 사용자 응답을 생성하는create_llm_simulated_user라는 사전 구축된 함수를 사용하지만, 직접 만들 수도 있습니다.
openevals의 simulator는 각 턴마다 user로부터 app에 단일 채팅 메시지를 전달합니다. 따라서 필요한 경우 thread_id를 기반으로 현재 히스토리를 내부적으로 상태적으로 추적해야 합니다.
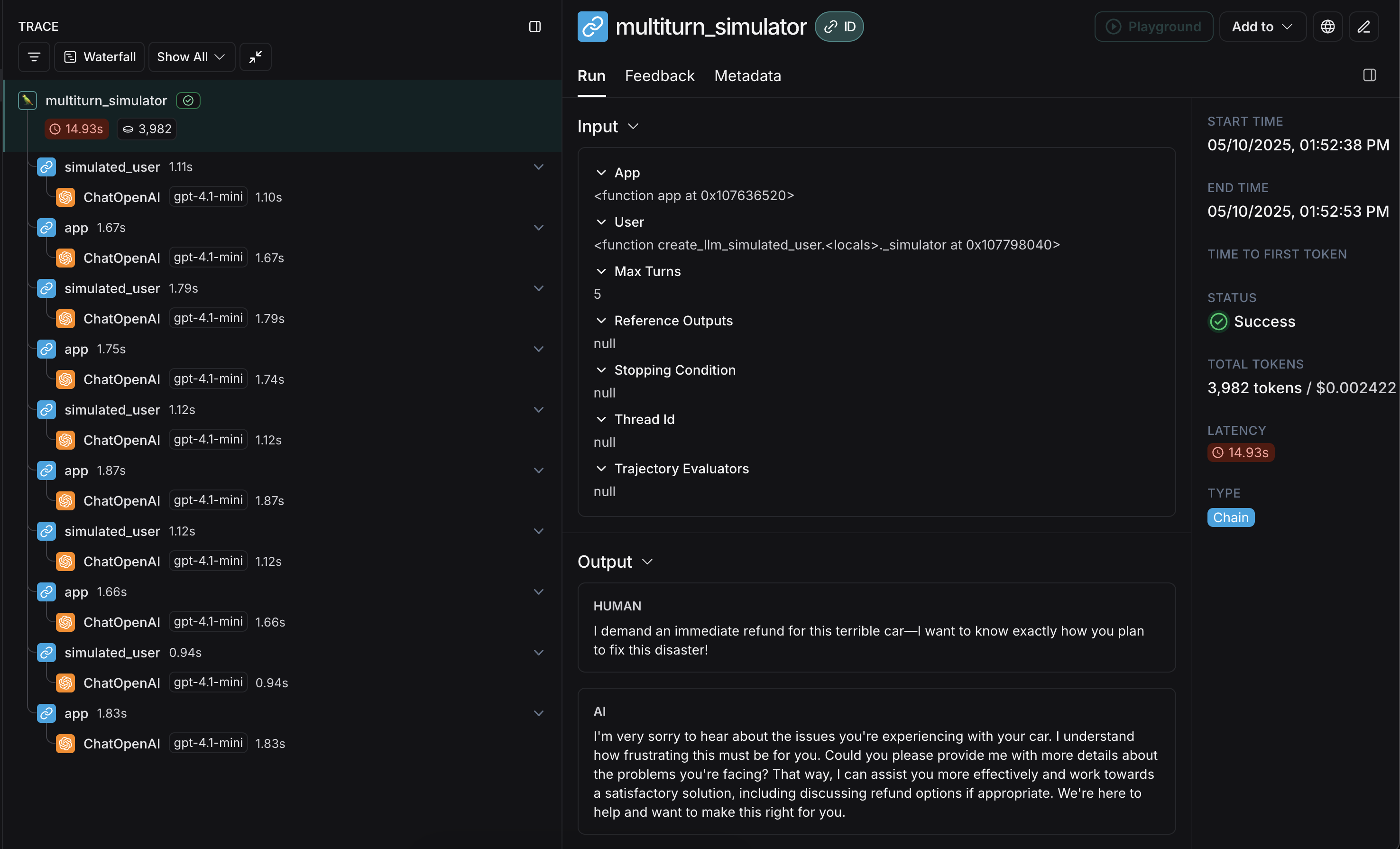
다음은 다중 턴 고객 지원 상호작용을 시뮬레이션하는 예제입니다. 이 가이드는 OpenAI chat completions API에 대한 단일 호출을 래핑하는 간단한 채팅 앱을 사용하지만, 여기에서 애플리케이션이나 에이전트를 호출할 수 있습니다. 이 예제에서 시뮬레이션된 사용자는 특히 공격적인 고객의 역할을 합니다:
user로부터 초기 쿼리를 생성한 다음, max_turns에 도달할 때까지 응답 채팅 메시지를 주고받습니다(또는 현재 궤적을 받아 True 또는 False를 반환하는 stopping_condition을 전달할 수 있습니다 - 자세한 내용은 OpenEvals README를 참조하세요). 반환 값은 대화의 궤적을 구성하는 최종 채팅 메시지 목록입니다.
시뮬레이션의 첫 번째 턴에 대해 고정된 응답을 반환하도록 하는 것과 같이 시뮬레이션된 사용자를 구성하는 여러 가지 방법이 있습니다. 자세한 내용은 OpenEvals README를 확인하세요.
app과 user의 응답이 교차되어 이와 같이 보일 것입니다:
축하합니다! 첫 번째 다중 턴 시뮬레이션을 실행했습니다. 다음으로 LangSmith experiment에서 실행하는 방법을 다루겠습니다.
LangSmith experiments에서 실행
다중 턴 시뮬레이션의 결과를 LangSmith experiment의 일부로 사용하여 시간 경과에 따른 성능과 진행 상황을 추적할 수 있습니다. 이 섹션에서는 LangSmith의pytest (Python 전용), Vitest/Jest (JS 전용) 또는 evaluate 러너 중 하나 이상에 익숙한 것이 도움이 됩니다.
pytest 또는 Vitest/Jest 사용
테스트 프레임워크와의 LangSmith 통합을 사용하여 evals를 설정하는 방법을 알아보려면 다음 가이드를 참조하세요:
trajectory_evaluators 매개변수로 전달할 수 있습니다. 이러한 evaluators는 시뮬레이션이 끝날 때 실행되며, 최종 채팅 메시지 목록을 outputs kwarg로 받습니다. 따라서 전달된 trajectory_evaluator는 이 kwarg를 받아야 합니다.
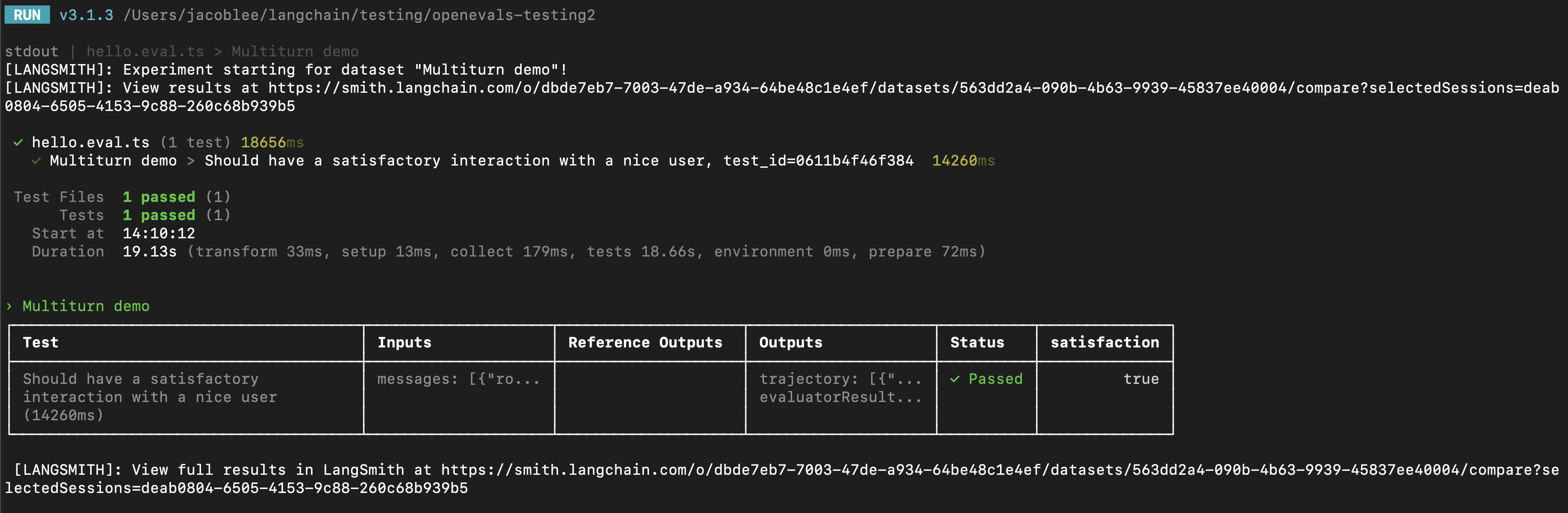 다음은 예제입니다:
다음은 예제입니다:
trajectory_evaluators에서 반환된 피드백을 자동으로 감지하고 로깅하여 experiment에 추가합니다. 또한 테스트 케이스는 시뮬레이션된 사용자의 fixed_responses 매개변수를 사용하여 특정 입력으로 대화를 시작하며, 이를 로깅하고 저장된 데이터셋의 일부로 만들 수 있습니다.
시뮬레이션된 사용자의 system prompt도 로깅된 데이터셋의 일부로 포함하는 것이 편리할 수 있습니다.
evaluate 사용
evaluate 러너를 사용하여 시뮬레이션된 다중 턴 상호작용을 평가할 수도 있습니다. 이는 pytest/Vitest/Jest 예제와 다음과 같은 점에서 약간 다릅니다:
- 시뮬레이션은
target함수의 일부여야 하며, target 함수는 최종 궤적을 반환해야 합니다.- 이렇게 하면 궤적이 LangSmith가 evaluators에 전달할
outputs가 됩니다.
- 이렇게 하면 궤적이 LangSmith가 evaluators에 전달할
trajectory_evaluators매개변수를 사용하는 대신, evaluators를evaluate()메서드의 매개변수로 전달해야 합니다.- 입력과 (선택적으로) 참조 궤적의 기존 데이터셋이 필요합니다.
시뮬레이션된 사용자 페르소나 수정
위의 예제는create_llm_simulated_user에 전달된 system 매개변수로 정의된 모든 입력 예제에 대해 동일한 시뮬레이션된 사용자 페르소나를 사용하여 실행됩니다. 데이터셋의 특정 항목에 대해 다른 페르소나를 사용하려면 데이터셋 예제를 업데이트하여 원하는 system prompt가 포함된 추가 필드를 포함한 다음, 다음과 같이 시뮬레이션된 사용자를 생성할 때 해당 필드를 전달할 수 있습니다:
다음 단계
다중 턴 상호작용을 시뮬레이션하고 LangSmith evals에서 실행하는 몇 가지 기술을 살펴보았습니다. 다음으로 탐색할 수 있는 몇 가지 주제는 다음과 같습니다: 또한 사전 구축된 evaluators에 대한 자세한 내용은 OpenEvals readme를 탐색할 수 있습니다.Connect these docs programmatically to Claude, VSCode, and more via MCP for real-time answers.