

requests 라이브러리를 예시로 사용하여 REST API를 통해 평가를 업로드하는 방법을 보여줍니다. 그러나 동일한 원칙이 모든 언어에 적용됩니다.
Request body schema
실험을 업로드하려면 실험 및 데이터셋에 대한 관련 상위 수준 정보와 함께 실험 내 예제 및 실행에 대한 개별 데이터를 지정해야 합니다.results의 각 객체는 실험의 “행”을 나타냅니다 - 단일 데이터셋 예제와 관련 실행입니다. dataset_id와 dataset_name은 외부 시스템의 데이터셋 식별자를 참조하며 외부 실험을 단일 데이터셋으로 그룹화하는 데 사용됩니다. 이들은 LangSmith의 기존 데이터셋을 참조해서는 안 됩니다(해당 데이터셋이 이 엔드포인트를 통해 생성된 경우가 아니라면).
다음 schema를 사용하여 /datasets/upload-experiment 엔드포인트에 실험을 업로드할 수 있습니다:
experiment와 dataset 키를 가진 dict이며, 각각은 생성된 실험 및 데이터셋에 대한 관련 정보를 포함하는 객체입니다.
고려사항
여러 호출 간에 동일한 dataset_id 또는 dataset_name을 제공하여 동일한 데이터셋에 여러 실험을 업로드할 수 있습니다. 실험은 단일 데이터셋 아래에 함께 그룹화되며, 비교 뷰를 사용하여 실험 간 결과를 비교할 수 있습니다. 개별 행의 시작 및 종료 시간이 모두 실험의 시작 및 종료 시간 사이에 있는지 확인하세요. dataset_id 또는 dataset_name 중 하나를 반드시 제공해야 합니다. ID만 제공하고 데이터셋이 아직 존재하지 않는 경우 이름을 생성해 드리며, 이름만 제공하는 경우도 마찬가지입니다. 이 엔드포인트를 통해 생성되지 않은 데이터셋에는 실험을 업로드할 수 없습니다. 실험 업로드는 외부에서 관리되는 데이터셋에만 지원됩니다.예제 요청
다음은/datasets/upload-experiment에 대한 간단한 호출 예제입니다. 이는 설명을 위해 가장 중요한 필드만 사용하는 기본 예제입니다.
UI에서 실험 보기
이제 UI에 로그인하고 새로 생성된 데이터셋을 클릭하세요! 단일 실험이 표시됩니다: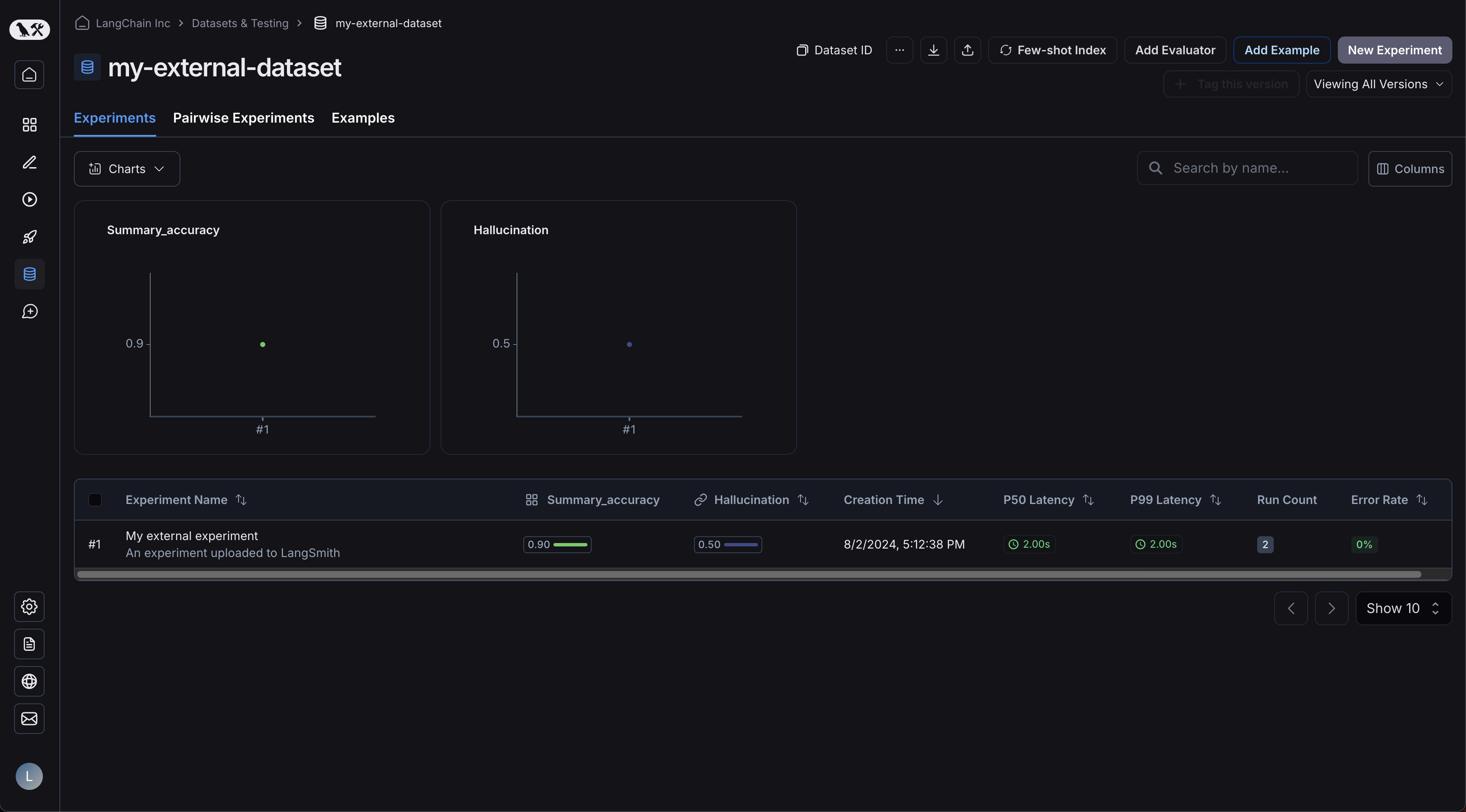 예제가 업로드되었습니다:
예제가 업로드되었습니다: 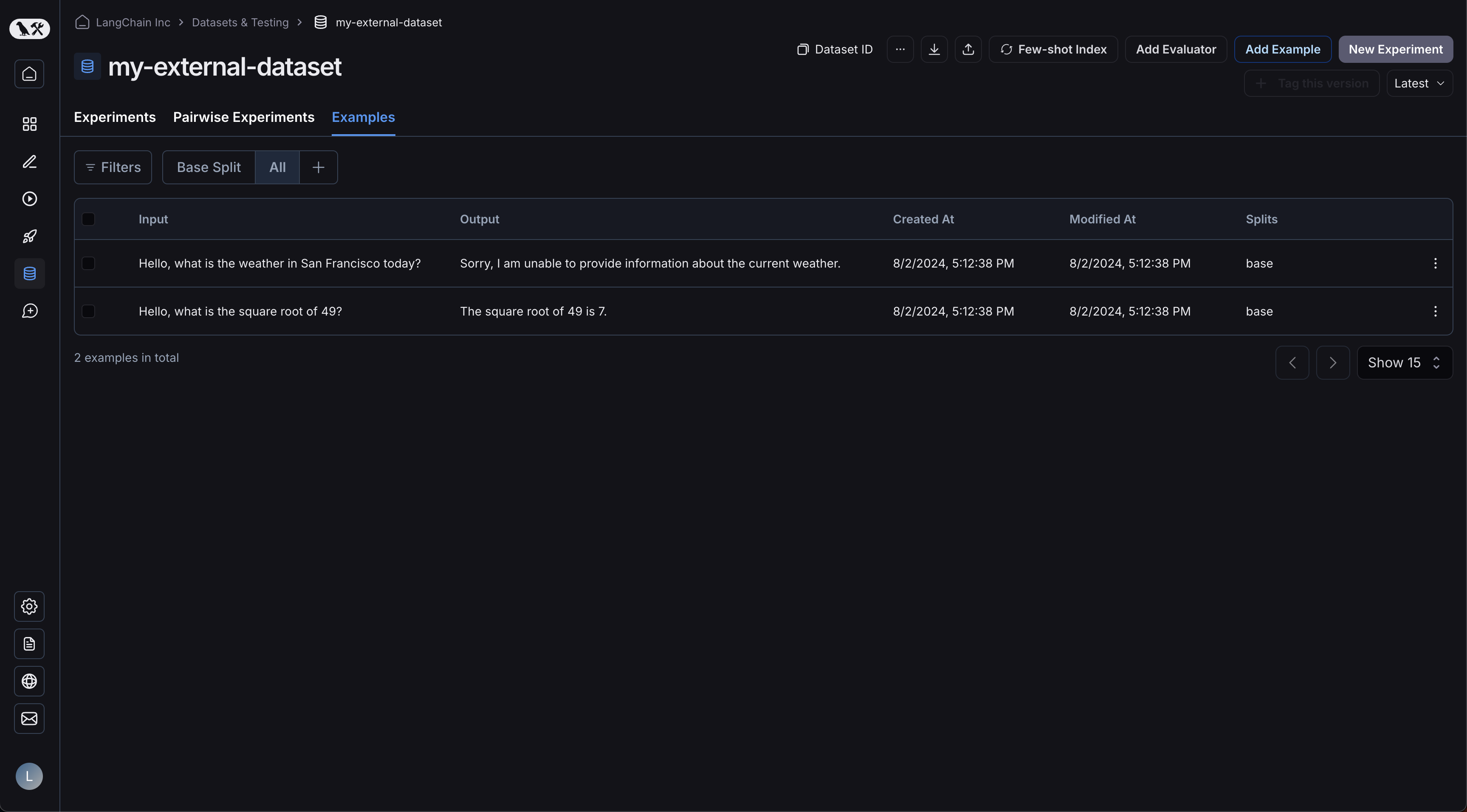 실험을 클릭하면 비교 뷰로 이동합니다:
실험을 클릭하면 비교 뷰로 이동합니다: 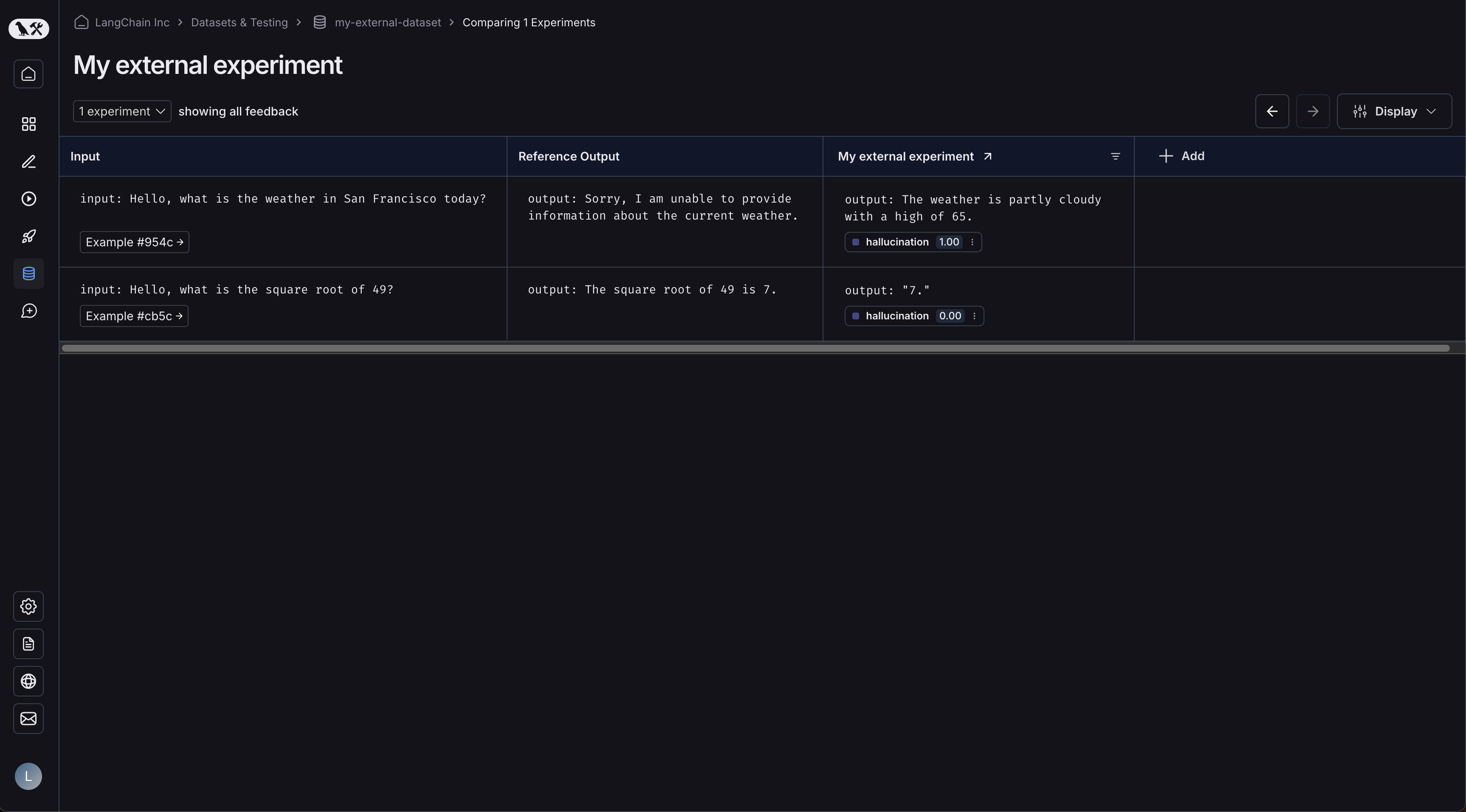 데이터셋에 더 많은 실험을 업로드하면 결과를 비교하고 비교 뷰에서 회귀를 쉽게 식별할 수 있습니다.
데이터셋에 더 많은 실험을 업로드하면 결과를 비교하고 비교 뷰에서 회귀를 쉽게 식별할 수 있습니다.
Connect these docs programmatically to Claude, VSCode, and more via MCP for real-time answers.