

Agents
LLM 기반 자율 에이전트는 세 가지 구성 요소 (1) Tool calling, (2) Memory, (3) Planning을 결합합니다. 에이전트는 tool calling을 planning(예: 프롬프트를 통한) 및 memory(예: 단기 메시지 히스토리)와 함께 사용하여 응답을 생성합니다. Tool calling은 모델이 주어진 프롬프트에 대해 두 가지를 생성할 수 있게 합니다: (1) 호출할 도구와 (2) 필요한 입력 인자.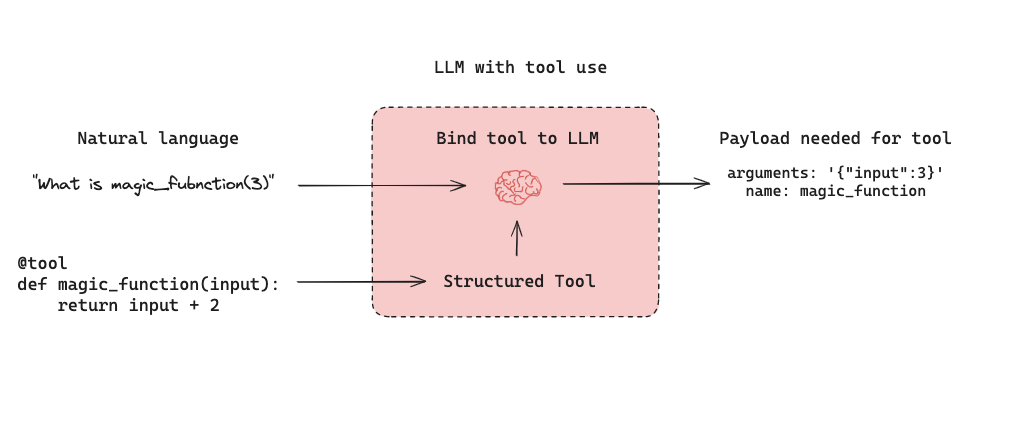 아래는 LangGraph에서의 tool-calling agent 예시입니다.
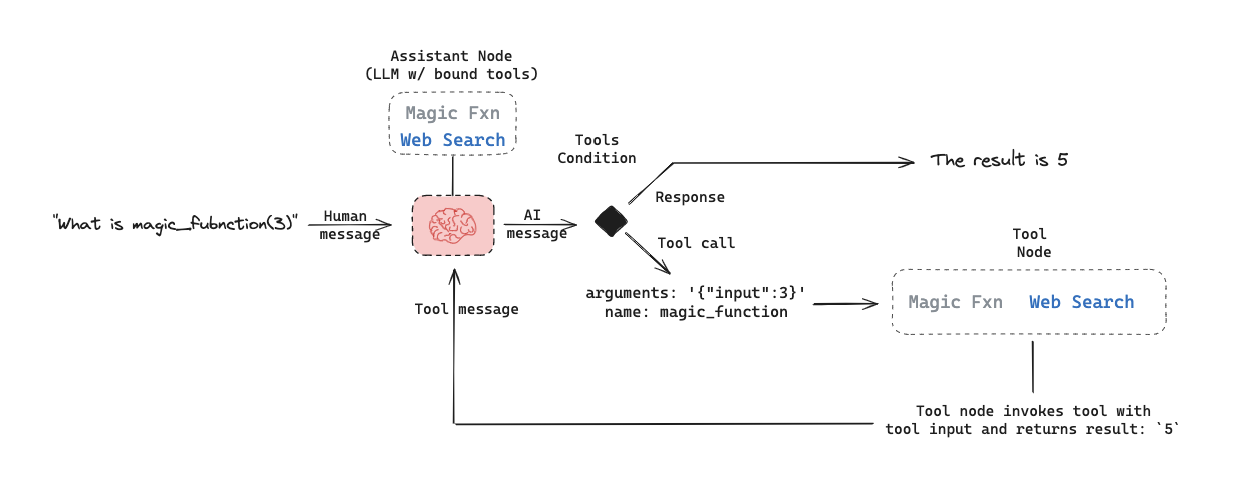
아래는 LangGraph에서의 tool-calling agent 예시입니다. assistant node는 입력에 따라 도구를 호출할지 결정하는 LLM입니다. tool condition은 assistant node가 도구를 선택했는지 확인하고, 선택했다면 tool node로 라우팅합니다. tool node는 도구를 실행하고 결과를 tool message로 assistant node에 반환합니다. 이 루프는 assistant node가 도구를 선택하는 동안 계속됩니다. 도구가 선택되지 않으면 에이전트는 LLM 응답을 직접 반환합니다.
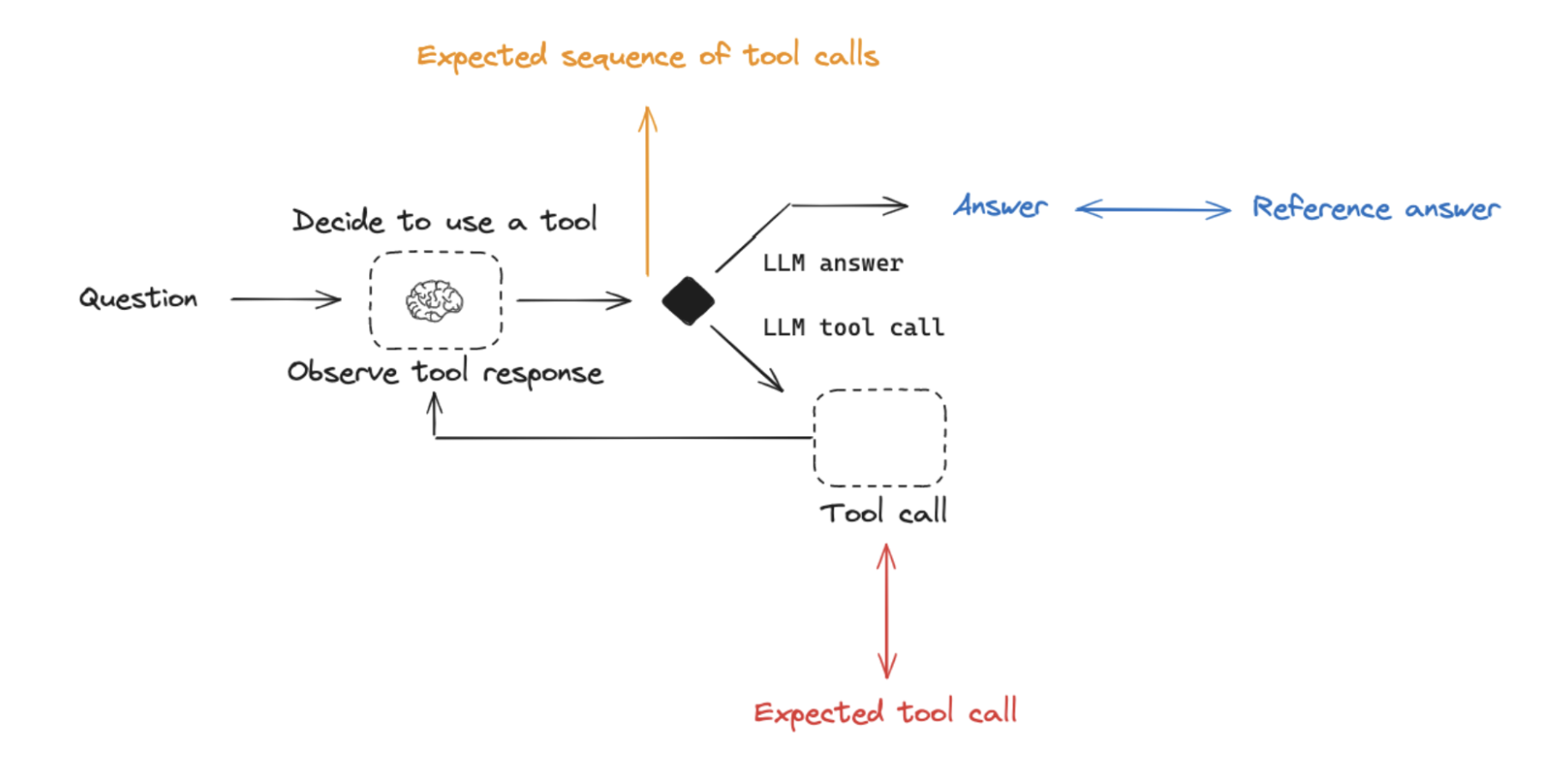
 이 구조는 사용자가 자주 관심을 가지는 세 가지 일반적인 에이전트 평가 유형을 만듭니다:
이 구조는 사용자가 자주 관심을 가지는 세 가지 일반적인 에이전트 평가 유형을 만듭니다:
Final Response: 에이전트의 최종 응답을 평가합니다.Single step: 에이전트의 개별 단계를 독립적으로 평가합니다 (예: 적절한 도구를 선택했는지).Trajectory: 에이전트가 최종 답변에 도달하기 위해 예상 경로(예: 도구 호출 경로)를 따랐는지 평가합니다.
 아래에서는 각 평가가 무엇인지, 필요한 구성 요소(입력, 출력, 평가자), 그리고 언제 고려해야 하는지 다룹니다. 이 평가 유형들은 상호 배타적이지 않으므로 여러 가지(혹은 모두)를 수행하는 것이 일반적입니다!
아래에서는 각 평가가 무엇인지, 필요한 구성 요소(입력, 출력, 평가자), 그리고 언제 고려해야 하는지 다룹니다. 이 평가 유형들은 상호 배타적이지 않으므로 여러 가지(혹은 모두)를 수행하는 것이 일반적입니다!
에이전트의 최종 응답 평가
에이전트를 평가하는 한 가지 방법은 작업에 대한 전체적인 성능을 평가하는 것입니다. 이는 기본적으로 에이전트를 블랙박스로 취급하고, 작업을 제대로 수행했는지만 평가하는 방식입니다. 입력은 사용자 입력과 (선택적으로) 도구 목록이어야 합니다. 어떤 경우에는 도구가 에이전트에 하드코딩되어 있어 별도로 전달할 필요가 없습니다. 다른 경우에는 에이전트가 더 일반적이어서 고정된 도구 세트가 없고, 실행 시 도구를 전달해야 합니다. 출력은 에이전트의 최종 응답이어야 합니다. 평가자는 에이전트에게 요구하는 작업에 따라 달라집니다. 많은 에이전트는 비교적 복잡한 단계를 수행하고, 최종 텍스트 응답을 출력합니다. RAG와 유사하게, LLM-as-judge 평가자는 이러한 경우에 효과적입니다. 텍스트 응답만으로 에이전트가 작업을 제대로 수행했는지 평가할 수 있기 때문입니다. 하지만 이 평가 방식에는 몇 가지 단점이 있습니다. 첫째, 실행 시간이 오래 걸릴 수 있습니다. 둘째, 에이전트 내부에서 일어나는 과정을 평가하지 않으므로 실패 시 디버깅이 어렵습니다. 셋째, 적절한 평가 지표를 정의하기 어려울 수 있습니다.에이전트의 단일 단계 평가
에이전트는 일반적으로 여러 동작을 수행합니다. 전체 프로세스를 평가하는 것도 유용하지만, 개별 동작을 평가하는 것도 중요합니다. 이는 일반적으로 에이전트의 단일 단계, 즉 LLM이 다음 동작을 결정하는 호출을 평가하는 것입니다. 입력은 단일 단계에 대한 입력이어야 합니다. 테스트하는 내용에 따라, 단순히 사용자 입력(예: 프롬프트 및/또는 도구 세트)일 수도 있고, 이전에 완료된 단계가 포함될 수도 있습니다. 출력은 해당 단계의 출력, 즉 일반적으로 LLM 응답입니다. LLM 응답에는 종종 tool call이 포함되어, 에이전트가 다음에 어떤 동작을 해야 하는지 나타냅니다. 이 평가의 경우, 올바른 tool call이 선택되었는지에 대한 이진 점수와, 도구에 전달된 입력이 올바른지에 대한 휴리스틱이 사용됩니다. 참조 도구는 문자열로 간단히 지정할 수 있습니다. 이 평가 방식의 장점은 개별 동작을 평가할 수 있어, 애플리케이션의 실패 지점을 정확히 파악할 수 있다는 점입니다. 또한 단일 LLM 호출만 포함하므로 실행 속도가 빠르고, 선택된 도구와 참조 도구를 비교하는 간단한 휴리스틱 평가를 사용할 수 있습니다. 단점은 전체 에이전트가 아닌 특정 단계만 평가한다는 점입니다. 또 다른 단점은 데이터셋 생성이 어려울 수 있다는 점인데, 특히 에이전트 입력에 과거 히스토리를 포함하려는 경우 그렇습니다. 에이전트 경로 초반 단계(예: 입력 프롬프트만 포함) 데이터셋은 쉽게 생성할 수 있지만, 경로 후반 단계(예: 여러 이전 에이전트 동작 및 응답 포함) 데이터셋은 생성이 어렵습니다.에이전트의 경로 평가
에이전트의 경로 평가란 에이전트가 수행한 모든 단계를 평가하는 것입니다. 입력은 전체 에이전트에 대한 입력(사용자 입력, 선택적으로 도구 목록)입니다. 출력은 tool call 목록이며, “정확한” 경로(예: 예상되는 tool call 시퀀스)로 표현하거나, 단순히 예상되는 tool call 집합(순서 무관)으로 표현할 수 있습니다. 여기서 평가자는 수행된 단계에 대한 함수입니다. “정확한” 경로를 평가할 때는 시퀀스 내 각 도구 이름이 정확히 일치하는지 확인하는 이진 점수를 사용할 수 있습니다. 이는 간단하지만 몇 가지 단점이 있습니다. 경우에 따라 여러 개의 올바른 경로가 있을 수 있습니다. 또한, 이 평가는 경로가 한 단계만 어긋난 것과 완전히 틀린 것의 차이를 구분하지 못합니다. 이러한 단점을 보완하기 위해, “잘못된” 단계 수에 초점을 맞춘 평가 지표를 사용할 수 있습니다. 이는 경로가 거의 맞는 경우와 크게 벗어난 경우를 더 잘 구분합니다. 또한, 모든 예상 도구가 어떤 순서로든 호출되었는지에 초점을 맞출 수도 있습니다. 하지만 이러한 접근 방식은 도구에 전달된 입력을 평가하지 않고, 선택된 도구에만 집중합니다. 이를 보완하기 위해, 전체 에이전트 경로(참조 경로와 함께)를 메시지 집합(예: 모든 LLM 응답 및 tool call)으로 LLM-as-judge에 전달하는 평가 기법이 있습니다. 이는 에이전트의 전체 동작을 평가할 수 있지만, 참조를 준비하는 것이 가장 어렵습니다(다행히 LangGraph와 같은 프레임워크를 사용하면 도움이 됩니다!). 또 다른 단점은 평가 지표를 정의하기가 다소 까다로울 수 있다는 점입니다.Retrieval augmented generation (RAG)
Retrieval Augmented Generation(RAG)은 사용자의 입력에 따라 관련 문서를 검색하고, 이를 언어 모델에 전달하여 처리하는 강력한 기법입니다. RAG는 외부 지식을 활용하여 AI 애플리케이션이 더 정보에 기반하고, 문맥을 고려한 응답을 생성할 수 있게 해줍니다.RAG 개념에 대한 종합적인 리뷰는
RAG From Scratch 시리즈를 참고하세요.데이터셋
RAG 애플리케이션을 평가할 때, 각 입력 질문에 대한 참조 답변을 보유하고 있거나 쉽게 얻을 수 있는지가 핵심 고려사항입니다. 참조 답변은 생성된 응답의 정확성을 평가하는 기준 역할을 합니다. 하지만 참조 답변이 없어도, 다양한 평가를 참조 없는 RAG 평가 프롬프트(아래 예시 참고)를 통해 수행할 수 있습니다.평가자
LLM-as-judge는 RAG에서 자주 사용되는 평가자입니다. 이는 사실적 정확성이나 텍스트 간 일관성을 평가하는 효과적인 방법입니다.
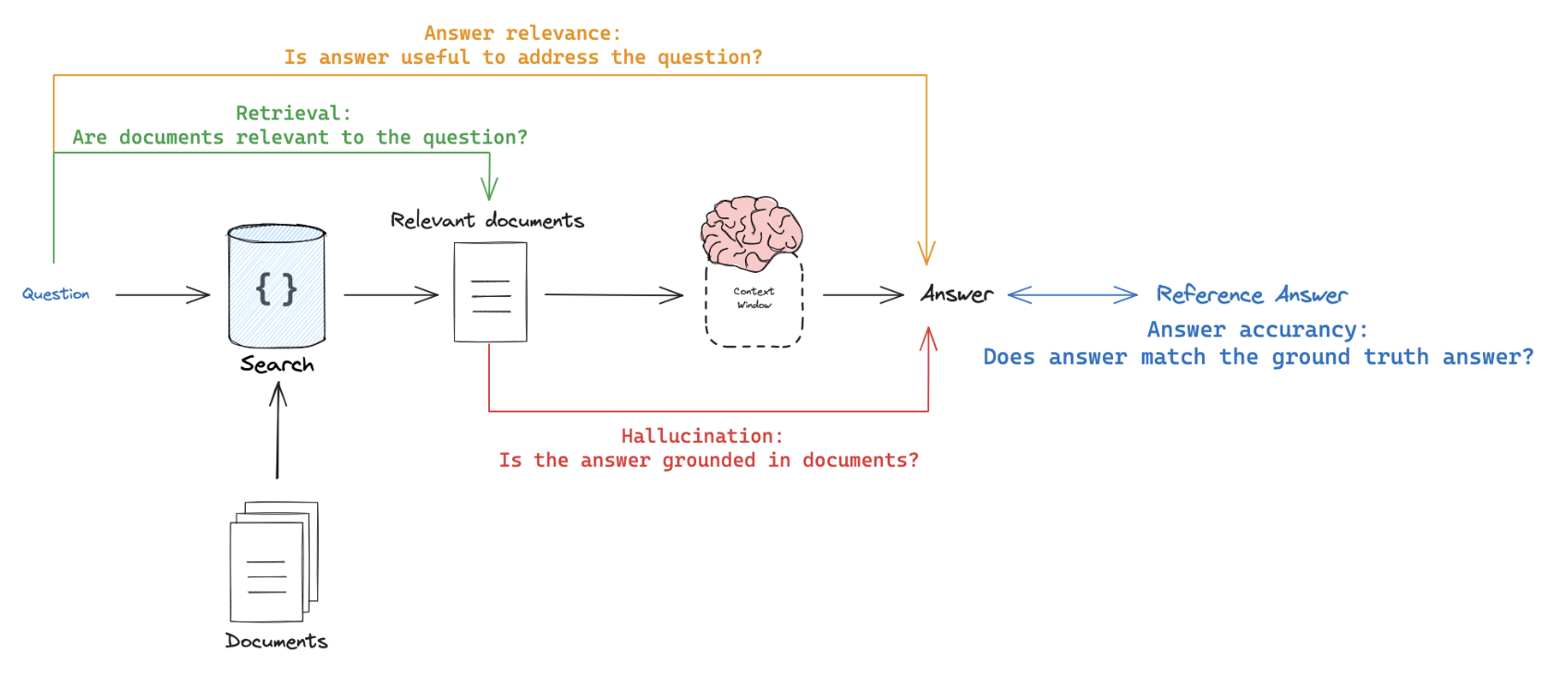 RAG 애플리케이션을 평가할 때, 참조 출력이 필요한 평가자와 필요하지 않은 평가자가 있습니다:
RAG 애플리케이션을 평가할 때, 참조 출력이 필요한 평가자와 필요하지 않은 평가자가 있습니다:
- 참조 출력 필요: RAG 체인이 생성한 답변이나 검색 결과를 참조 답변(또는 검색 결과)과 비교하여 정확성을 평가합니다.
- 참조 출력 불필요: 참조 답변이 필요 없는 프롬프트를 사용하여 자기 일관성 검사를 수행합니다(위 그림의 주황색, 녹색, 빨간색으로 표시됨).
RAG 평가 적용
RAG 평가를 적용할 때 다음 접근 방식을 고려하세요:-
Offline evaluation: 참조 답변에 의존하는 프롬프트에는 오프라인 평가를 사용합니다. 이는 RAG 답변 정확성 평가에 가장 일반적으로 사용되며, 참조가 정답(ground truth) 답변입니다. -
Online evaluation: 참조 없는 프롬프트에는 온라인 평가를 사용합니다. 이를 통해 RAG 애플리케이션의 성능을 실시간 시나리오에서 평가할 수 있습니다. -
Pairwise evaluation: 서로 다른 RAG 체인이 생성한 답변을 비교할 때 페어와이즈 평가를 활용합니다. 이 평가는 정확성보다는 사용자 지정 기준(예: 답변 형식, 스타일)에 초점을 맞추며, 자기 일관성 또는 정답 참조를 통해 평가할 수 있습니다.
RAG 평가 요약
| 평가자 | 세부 내용 | 참조 출력 필요 여부 | LLM-as-judge? | 페어와이즈 관련성 |
|---|---|---|---|---|
| Document relevance | 문서가 질문과 관련이 있는가? | 아니오 | 예 - 프롬프트 | 아니오 |
| Answer faithfulness | 답변이 문서에 근거하고 있는가? | 아니오 | 예 - 프롬프트 | 아니오 |
| Answer helpfulness | 답변이 질문 해결에 도움이 되는가? | 아니오 | 예 - 프롬프트 | 아니오 |
| Answer correctness | 답변이 참조 답변과 일치하는가? | 예 | 예 - 프롬프트 | 아니오 |
| Pairwise comparison | 여러 답변 버전이 어떻게 비교되는가? | 아니오 | 예 - 프롬프트 | 예 |
Summarization
Summarization(요약)은 자유 형식 글쓰기의 한 유형입니다. 평가는 일반적으로 요약문이 특정 기준에 부합하는지 확인하는 데 목적이 있습니다.Developer curated examples(개발자가 선별한 요약 대상 텍스트)는 평가에 자주 사용됩니다(데이터셋 예시 참고). 하지만, 프로덕션(요약) 앱의 user logs(사용자 로그)는 아래의 Reference-free 평가 프롬프트와 함께 온라인 평가에 사용할 수 있습니다.
LLM-as-judge는 요약(및 기타 글쓰기 유형) 평가에 일반적으로 사용되며, 제공된 기준에 따라 요약을 채점하는 Reference-free 프롬프트를 활용합니다. 요약은 창의적인 작업이므로, 특정 Reference 요약을 제공하는 경우는 드뭅니다. 올바른 답변이 여러 개 존재할 수 있기 때문입니다.
Online 또는 Offline 평가가 Reference-free 프롬프트 덕분에 모두 가능합니다. 또한, 서로 다른 요약 체인(예: 서로 다른 요약 프롬프트나 LLM) 간 비교를 위한 Pairwise 평가도 강력한 방법입니다:
| 사용 사례 | 세부 내용 | 참조 출력 필요 여부 | LLM-as-judge? | 페어와이즈 관련성 |
|---|---|---|---|---|
| Factual accuracy | 요약이 원본 문서에 대해 사실적으로 정확한가? | 아니오 | 예 - 프롬프트 | 예 |
| Faithfulness | 요약이 원본 문서에 근거하고 있는가(예: 환각 없음)? | 아니오 | 예 - 프롬프트 | 예 |
| Helpfulness | 요약이 사용자 요구에 도움이 되는가? | 아니오 | 예 - 프롬프트 | 예 |
Classification and tagging
Classification(분류)과 tagging(태깅)은 주어진 입력(예: 독성 탐지, 감정 분석 등)에 라벨을 적용하는 작업입니다. 분류/태깅 평가에는 일반적으로 다음과 같은 구성 요소가 사용되며, 아래에서 자세히 살펴봅니다: 분류/태깅 평가에서 중심이 되는 고려사항은reference 라벨이 포함된 데이터셋을 보유하고 있는지 여부입니다. 없다면, 사용자는 입력(예: 텍스트, 사용자 질문 등)에 대해 기준에 따라 라벨(예: 독성 등)을 적용하는 평가자를 정의하고자 하는 경우가 많습니다. 반면, 정답 클래스 라벨이 제공된다면, 평가 목적은 분류/태깅 체인 결과를 정답 클래스 라벨과 비교하여 점수를 매기는 데 집중합니다(예: precision, recall 등 지표 사용).
정답 참조 라벨이 제공된다면, 사용자 정의 휴리스틱 평가자를 정의하여 정답 라벨과 체인 출력을 비교하는 것이 일반적입니다. 하지만 LLM의 등장으로, 단순히 LLM-as-judge를 사용하여 기준에 따라 입력을 분류/태깅하는 경우(정답 참조 없이)도 점점 많아지고 있습니다.
Online 또는 Offline 평가가 LLM-as-judge와 Reference-free 프롬프트를 사용할 때 모두 가능합니다. 특히, 사용자가 애플리케이션 입력(예: 독성 등)을 태깅/분류하고자 할 때 Online 평가에 적합합니다.
| 사용 사례 | 세부 내용 | 참조 출력 필요 여부 | LLM-as-judge? | 페어와이즈 관련성 |
|---|---|---|---|---|
| Accuracy | 표준 정의 | 예 | 아니오 | 아니오 |
| Precision | 표준 정의 | 예 | 아니오 | 아니오 |
| Recall | 표준 정의 | 예 | 아니오 | 아니오 |
Connect these docs programmatically to Claude, VSCode, and more via MCP for real-time answers.