

- 시간 경과에 따른 변경 사항을 추적하기 위한 데이터셋 버전 관리.
- 평가를 위한 데이터셋 필터링 및 분할.
- 데이터셋 공개 공유.
- 다양한 형식으로 데이터셋 내보내기.
Version a dataset
LangSmith에서 데이터셋은 버전 관리됩니다. 즉, 데이터셋에서 예제를 추가, 업데이트 또는 삭제할 때마다 데이터셋의 새 버전이 생성됩니다.Create a new version of a dataset
데이터셋에서 예제를 추가, 업데이트 또는 삭제할 때마다 데이터셋의 새 버전이 생성됩니다. 이를 통해 시간 경과에 따른 데이터셋의 변경 사항을 추적하고 데이터셋이 어떻게 발전했는지 이해할 수 있습니다. 기본적으로 버전은 변경 시점의 timestamp로 정의됩니다. Examples 탭에서 데이터셋의 특정 버전(timestamp 기준)을 클릭하면 해당 시점의 데이터셋 상태를 확인할 수 있습니다.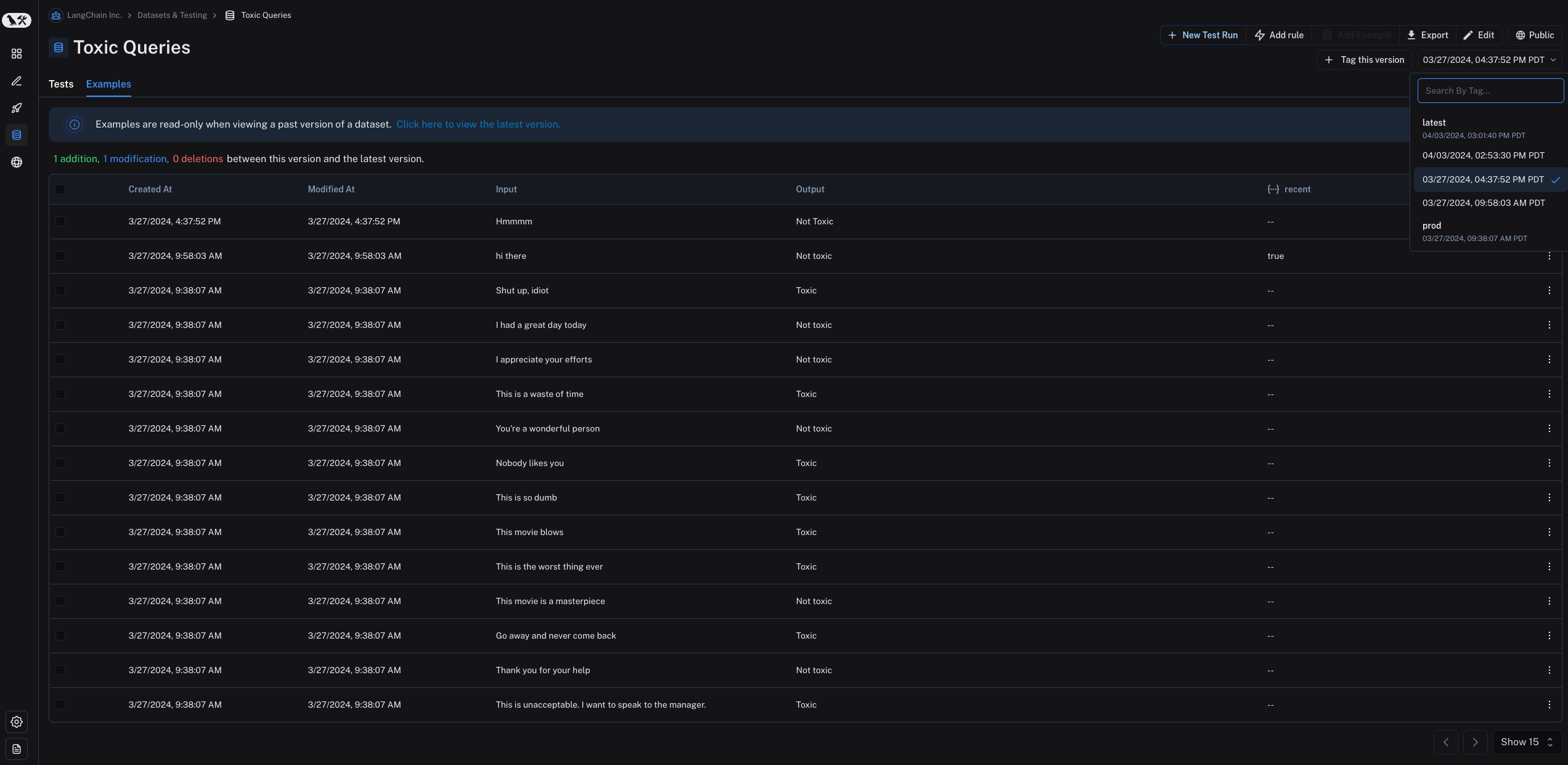 과거 버전의 데이터셋을 볼 때 예제는 읽기 전용입니다. 또한 이 버전의 데이터셋과 최신 버전의 데이터셋 사이에 수행된 작업도 확인할 수 있습니다.
과거 버전의 데이터셋을 볼 때 예제는 읽기 전용입니다. 또한 이 버전의 데이터셋과 최신 버전의 데이터셋 사이에 수행된 작업도 확인할 수 있습니다.
기본적으로 Examples 탭에는 데이터셋의 최신 버전이 표시되고 Tests 탭에는 모든 버전의 실험이 표시됩니다.
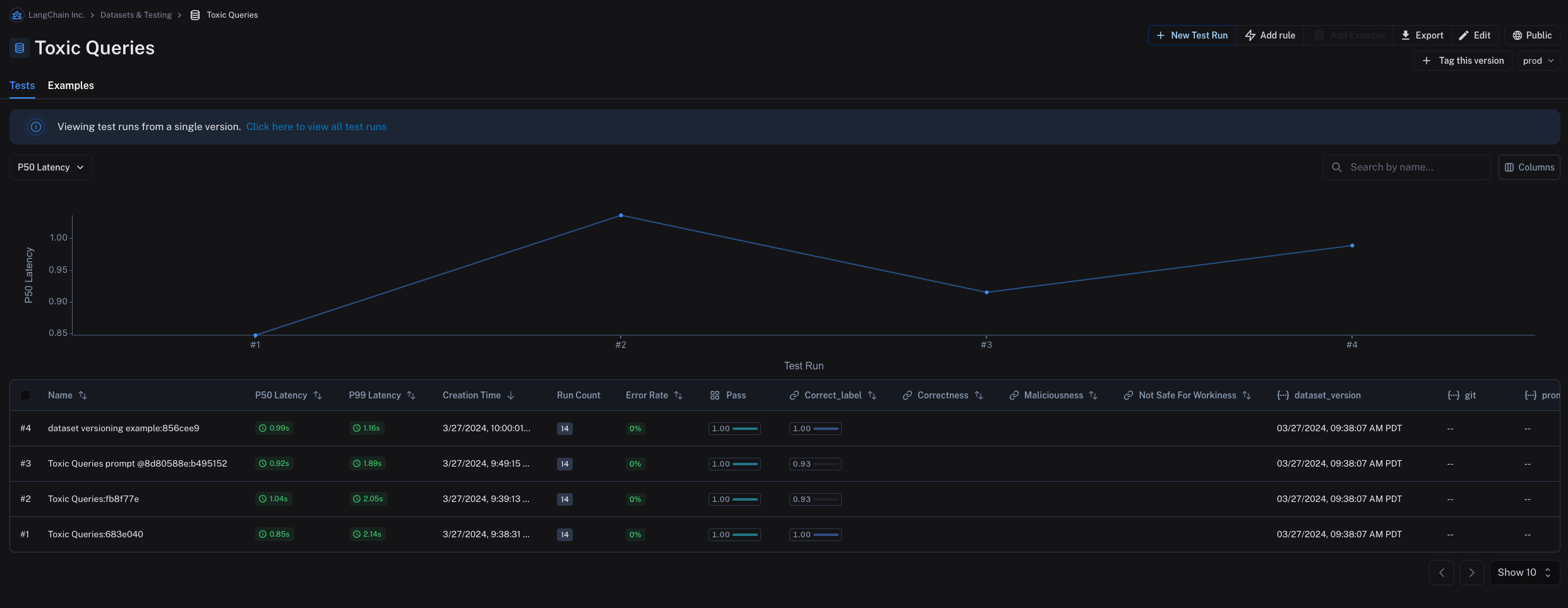
Tag a version
데이터셋의 버전에 태그를 지정하여 더 읽기 쉬운 이름을 부여할 수도 있습니다. 이는 데이터셋 히스토리에서 중요한 이정표를 표시하는 데 유용할 수 있습니다. 예를 들어, 데이터셋의 버전을 “prod”로 태그하고 이를 사용하여 LLM 파이프라인에 대한 테스트를 실행할 수 있습니다. UI에서 Examples 탭의 + Tag this version을 클릭하여 데이터셋의 버전에 태그를 지정할 수 있습니다. SDK를 사용하여 데이터셋의 버전에 태그를 지정할 수도 있습니다. 다음은 Python SDK를 사용하여 데이터셋의 버전에 태그를 지정하는 예제입니다:
SDK를 사용하여 데이터셋의 버전에 태그를 지정할 수도 있습니다. 다음은 Python SDK를 사용하여 데이터셋의 버전에 태그를 지정하는 예제입니다:
Evaluate on a specific dataset version
이 섹션을 읽기 전에 다음 내용을 참조하는 것이 도움이 될 수 있습니다:
Use list_examples
evaluate / aevaluate를 사용하여 데이터셋의 특정 버전에서 평가할 예제의 iterable을 전달할 수 있습니다. list_examples / listExamples를 사용하여 as_of / asOf를 통해 특정 버전 태그에서 예제를 가져오고 이를 data 인수에 전달합니다.
Evaluate on a split / filtered view of a dataset
이 섹션을 읽기 전에 다음 내용을 참조하는 것이 도움이 될 수 있습니다:
Evaluate on a filtered view of a dataset
list_examples / listExamples 메서드를 사용하여 데이터셋에서 평가할 예제의 하위 집합을 가져올 수 있습니다.
일반적인 워크플로우 중 하나는 특정 metadata key-value 쌍을 가진 예제를 가져오는 것입니다.
Evaluate on a dataset split
list_examples / listExamples 메서드를 사용하여 데이터셋의 하나 또는 여러 분할에서 평가할 수 있습니다. splits 매개변수는 평가하려는 분할 목록을 받습니다.
Share a dataset
Share a dataset publicly
데이터셋을 공개적으로 공유하면 데이터셋 예제, 실험 및 관련 run, 그리고 이 데이터셋에 대한 피드백이 LangSmith 계정이 없는 사람을 포함하여 링크를 가진 모든 사람이 액세스할 수 있게 됩니다. 민감한 정보를 공유하지 않도록 주의하세요.이 기능은 클라우드 호스팅 버전의 LangSmith에서만 사용할 수 있습니다.
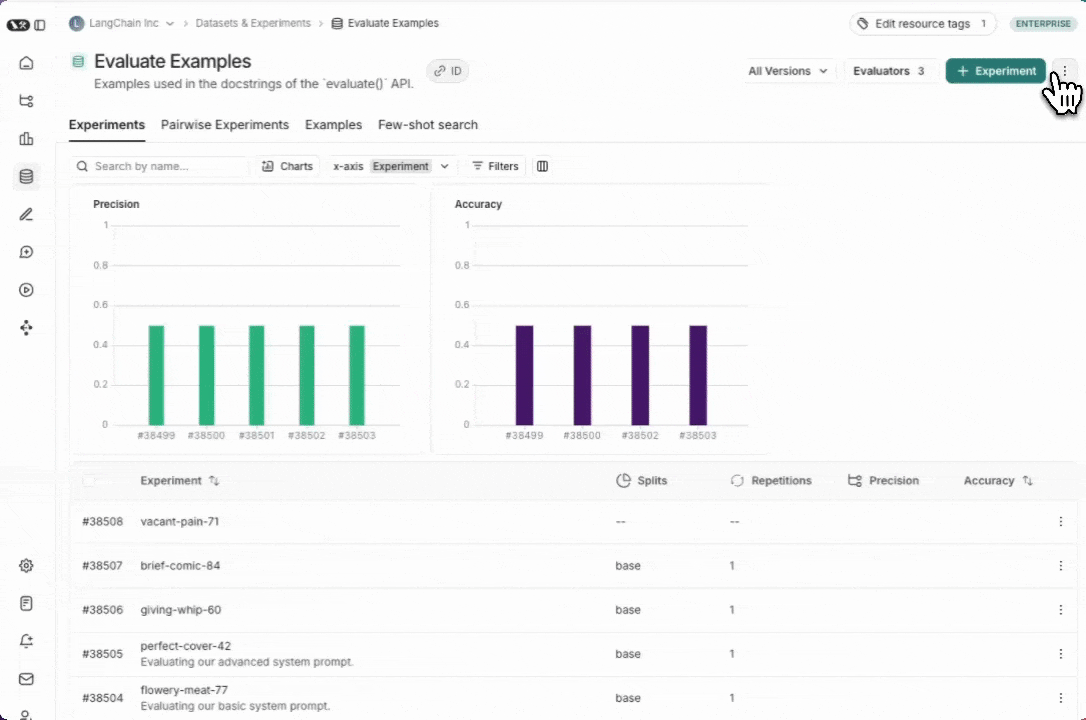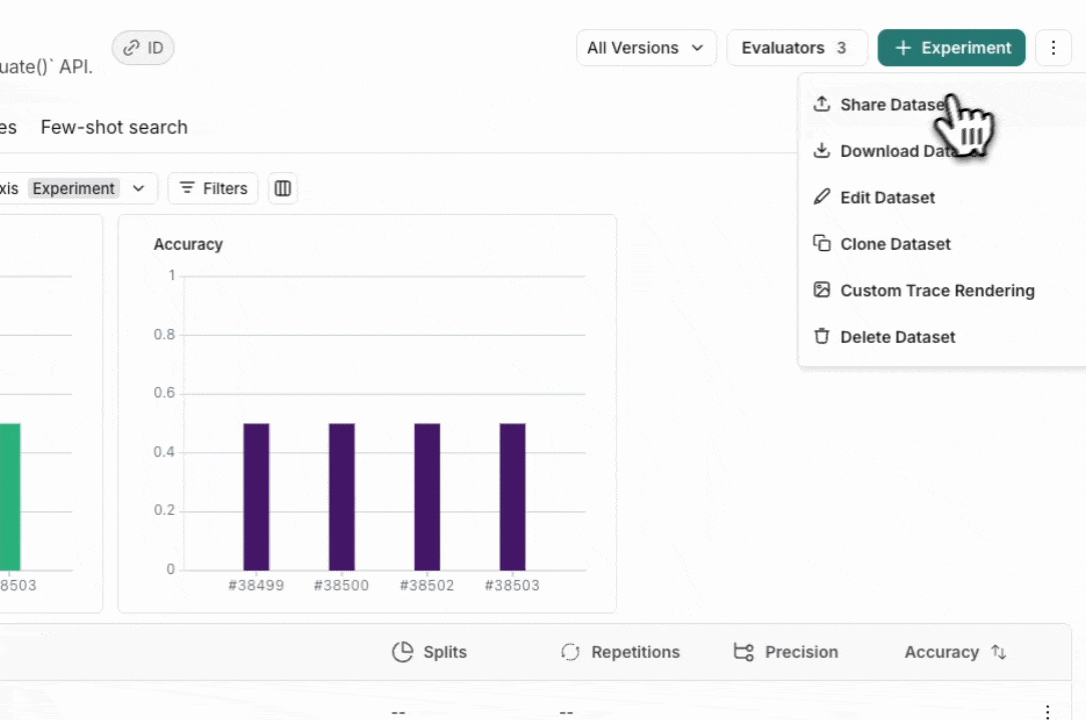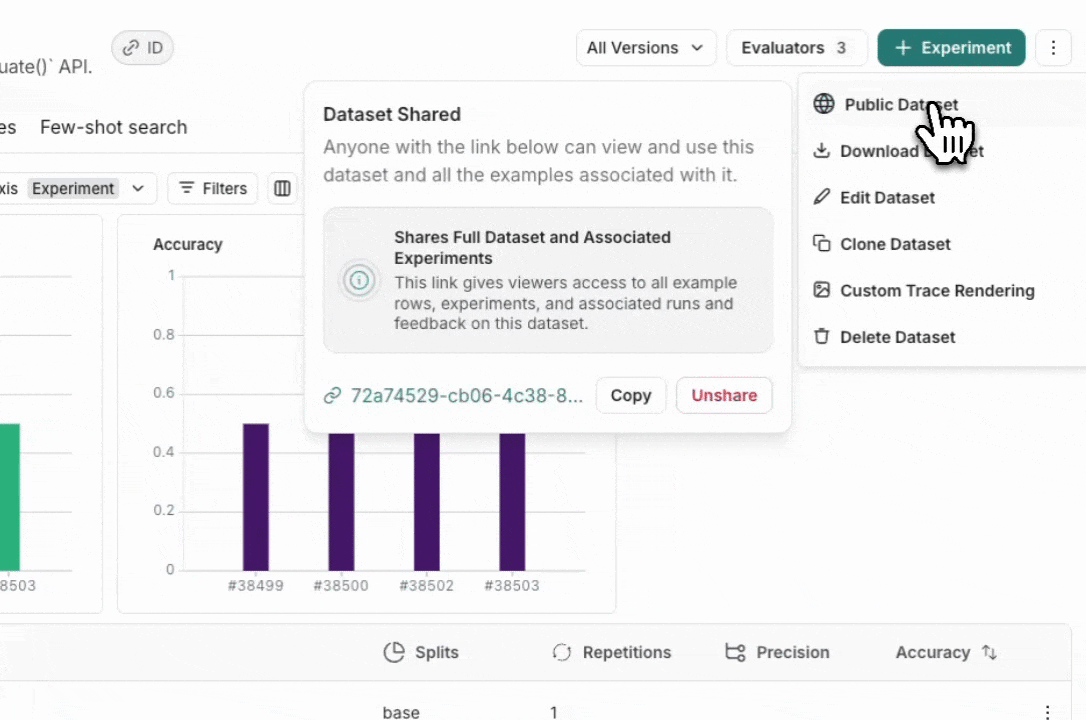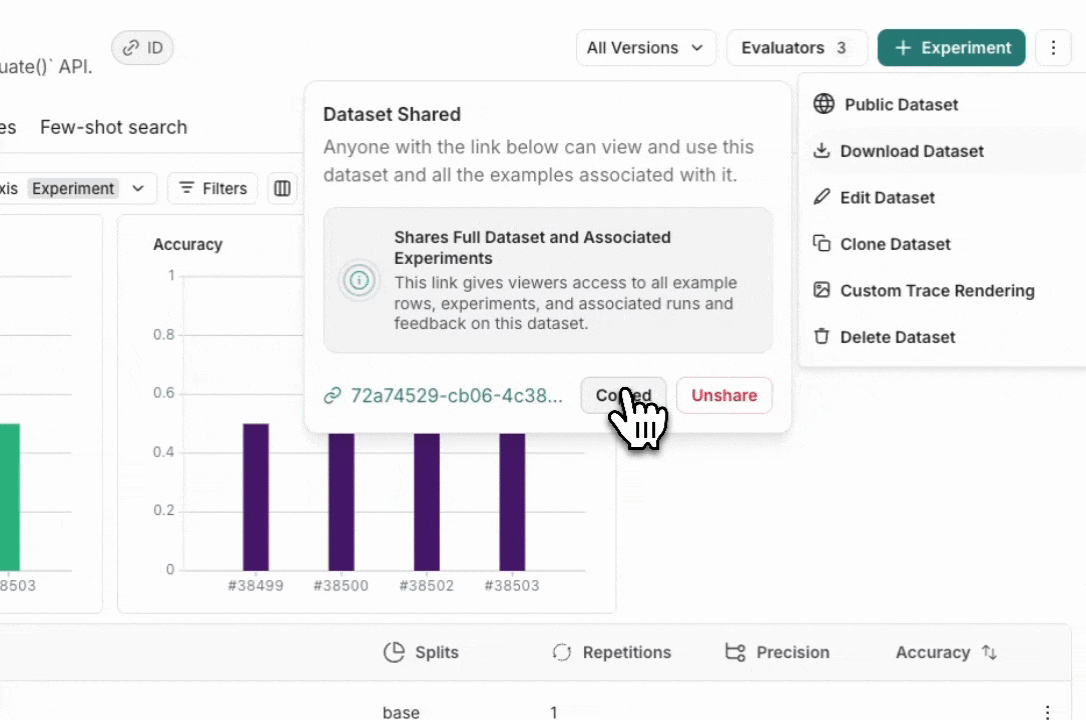
Unshare a dataset
-
공개적으로 공유된 데이터셋의 오른쪽 상단에 있는 Public을 클릭한 다음 대화 상자에서 Unshare를 클릭하여 Unshare합니다.
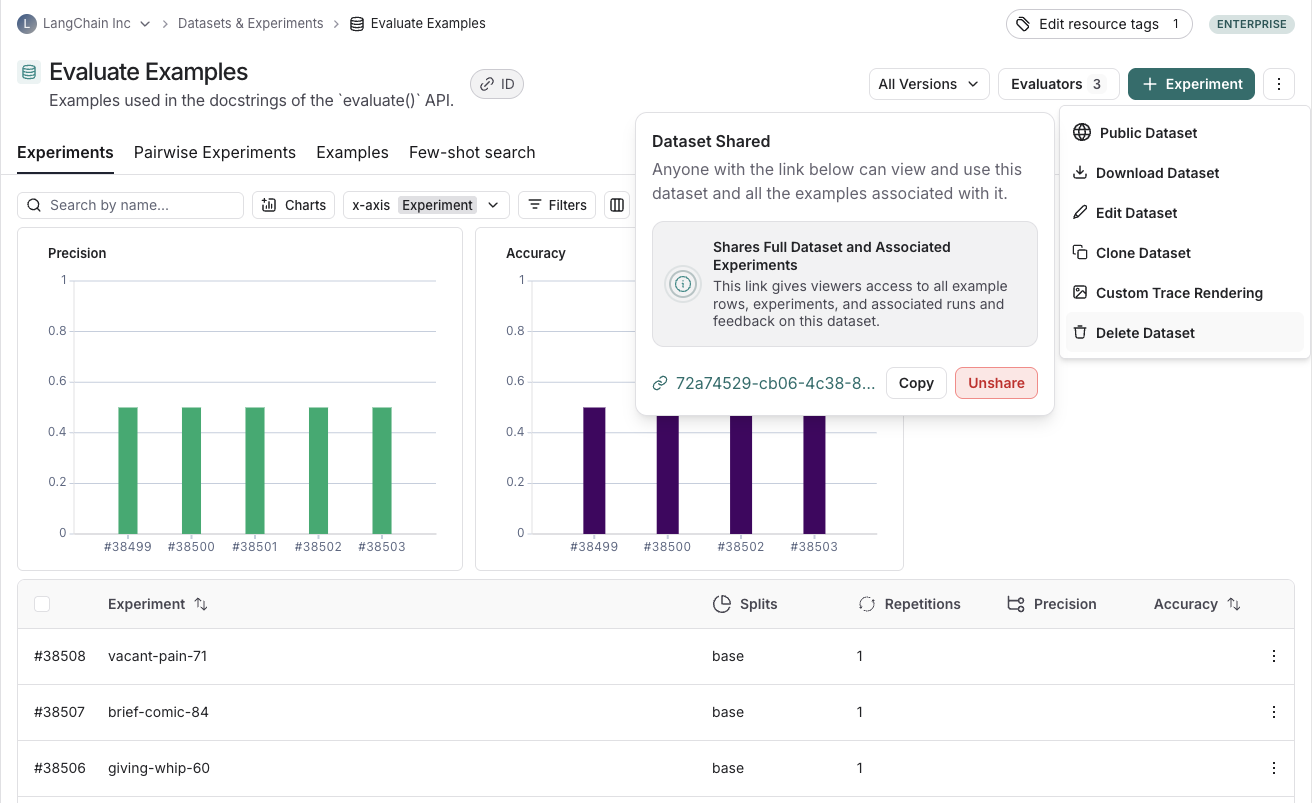
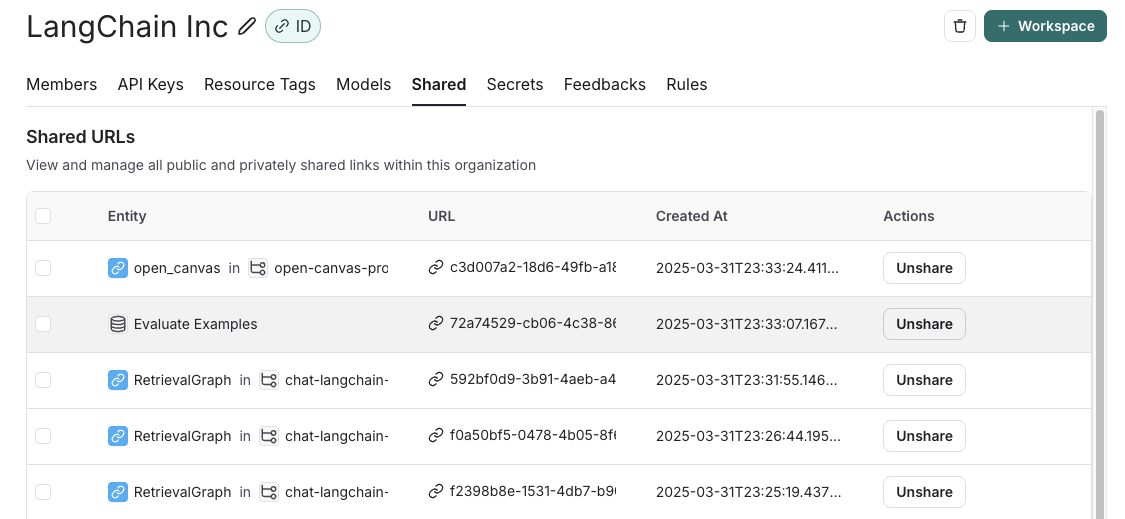
- Settings -> Shared URLs 또는 이 링크를 클릭하여 조직의 공개 공유 데이터셋 목록으로 이동한 다음 공유를 해제하려는 데이터셋 옆의 Unshare를 클릭합니다.
Export a dataset
LangSmith UI에서 LangSmith 데이터셋을 CSV, JSONL 또는 OpenAI의 fine tuning 형식으로 내보낼 수 있습니다. Dataset & Experiments 탭에서 데이터셋을 선택하고 ⋮(페이지 오른쪽 상단)를 클릭한 다음 Download Dataset을 클릭합니다.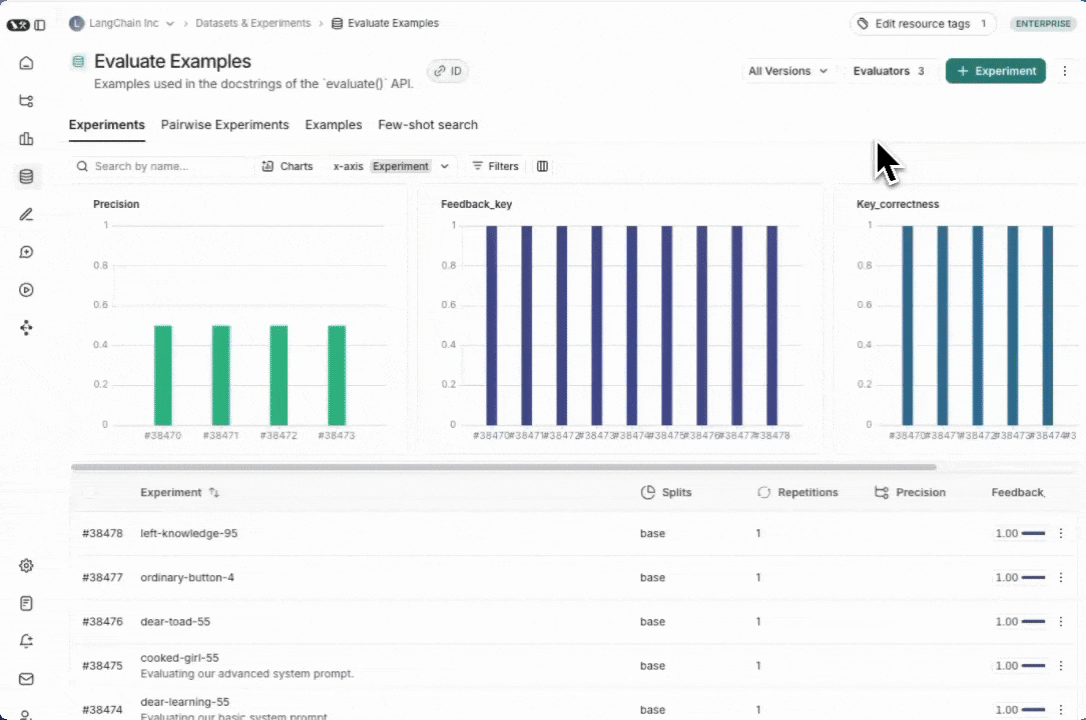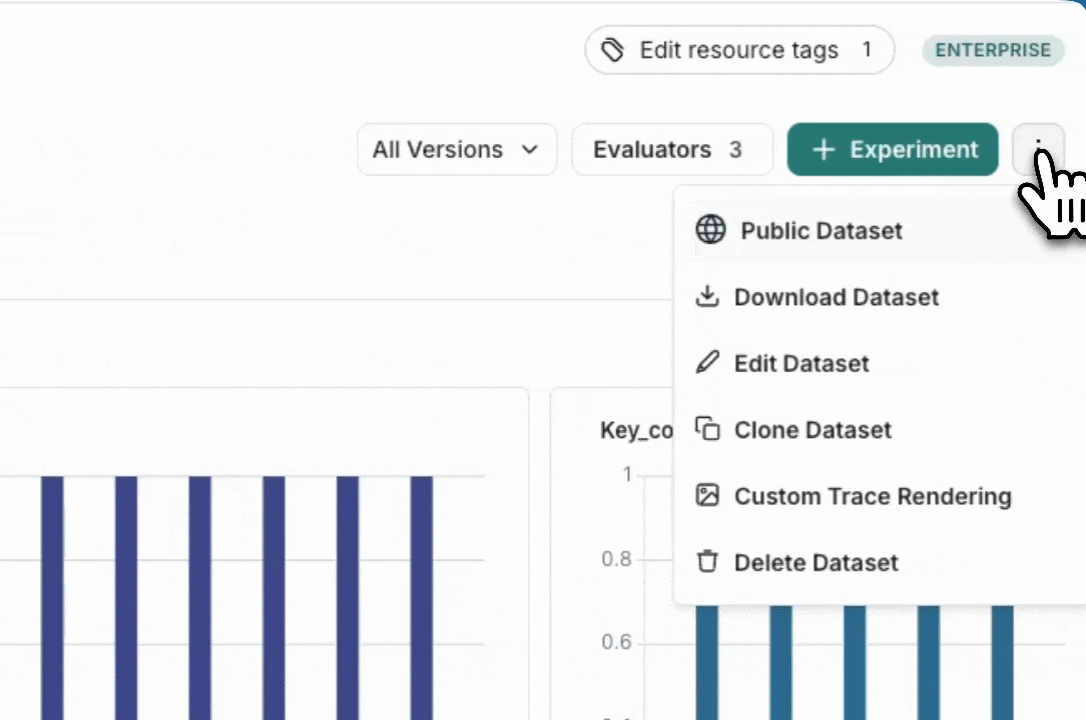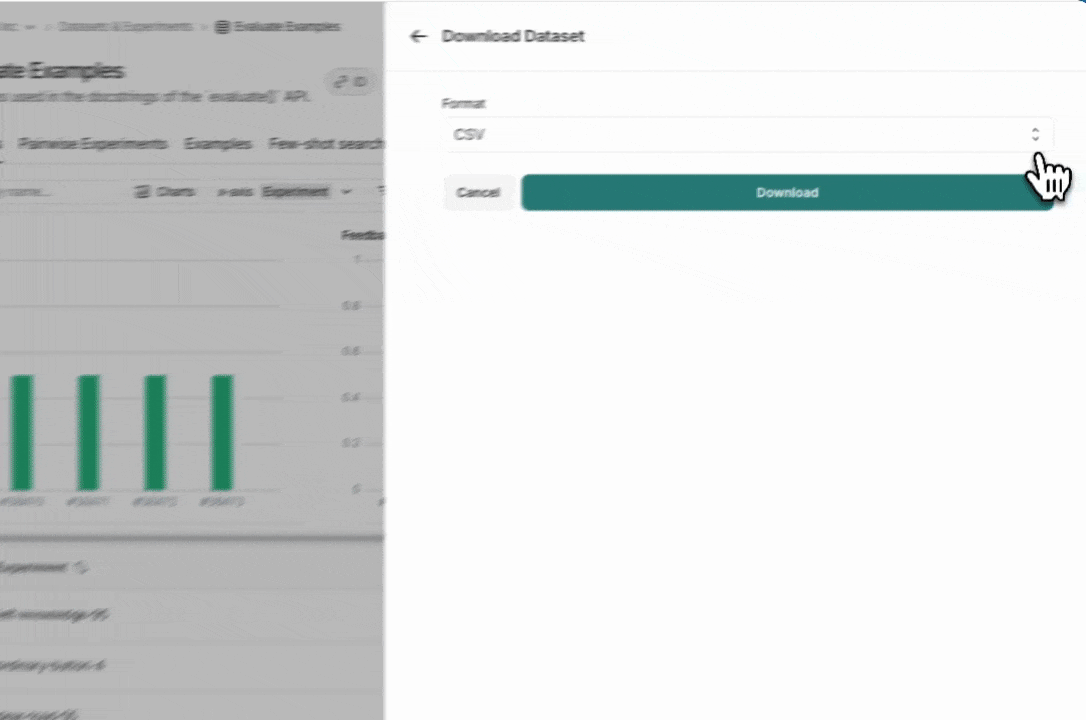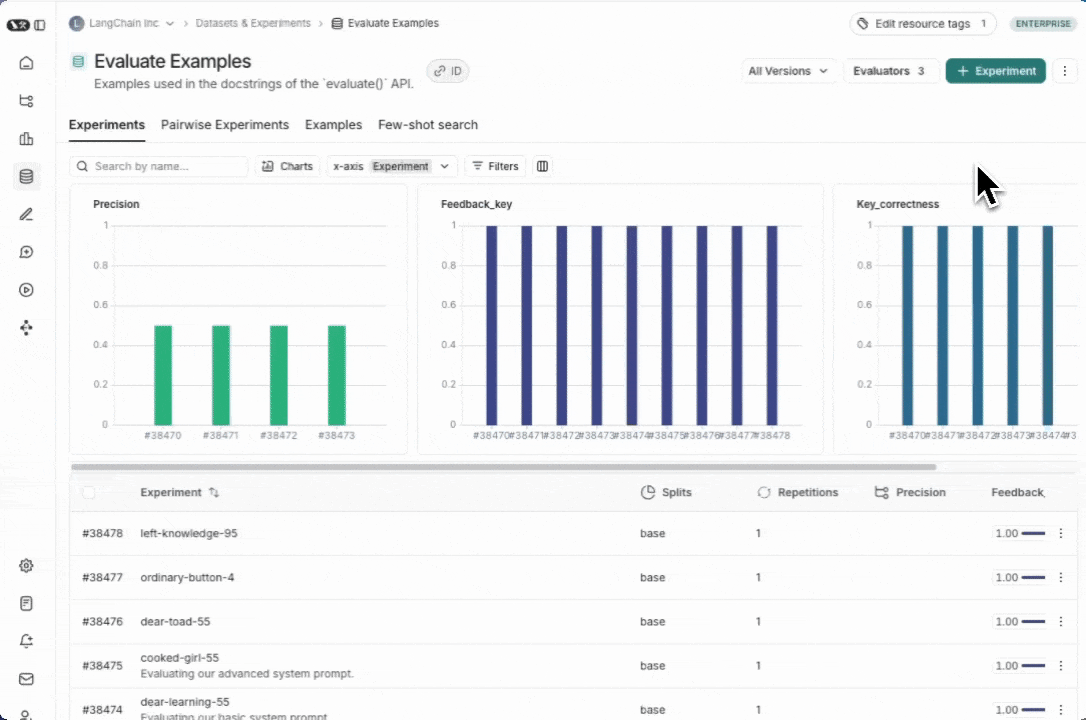
Export filtered traces from experiment to dataset
LangSmith에서 오프라인 평가를 실행한 후 일부 평가 기준을 충족하는 trace를 데이터셋으로 내보낼 수 있습니다.View experiment traces
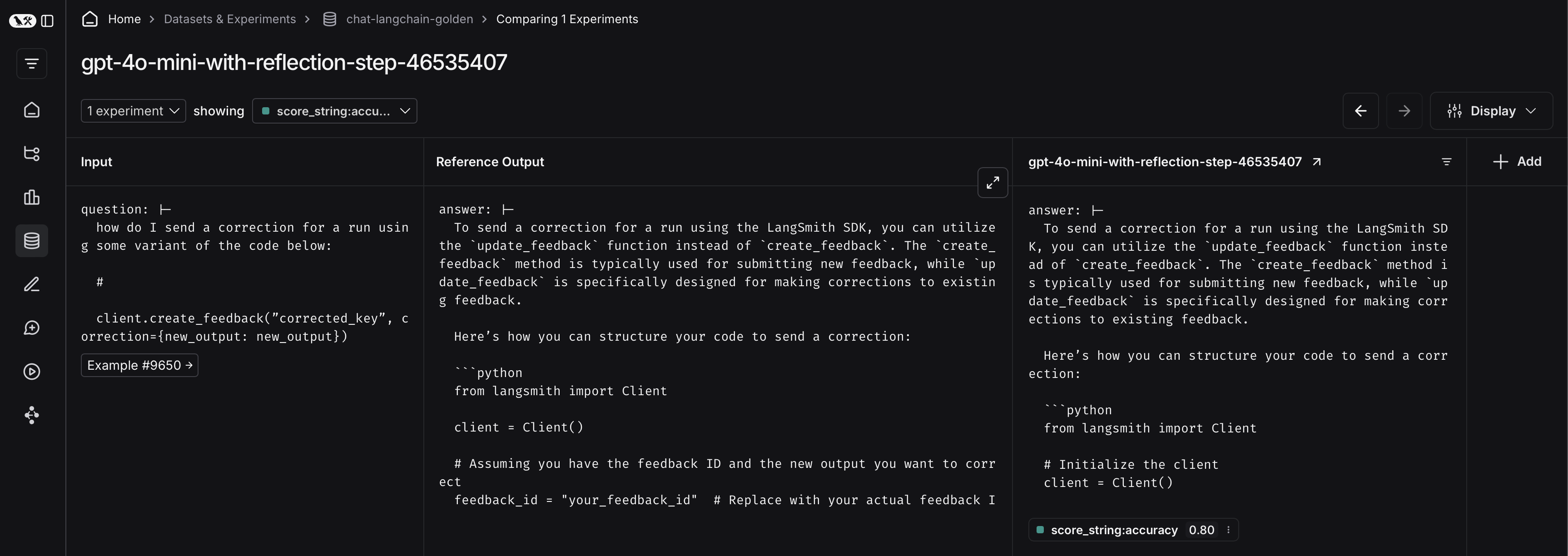 이렇게 하려면 먼저 실험 이름 옆의 화살표를 클릭합니다. 그러면 실험에서 생성된 trace가 포함된 프로젝트로 이동합니다.
이렇게 하려면 먼저 실험 이름 옆의 화살표를 클릭합니다. 그러면 실험에서 생성된 trace가 포함된 프로젝트로 이동합니다.
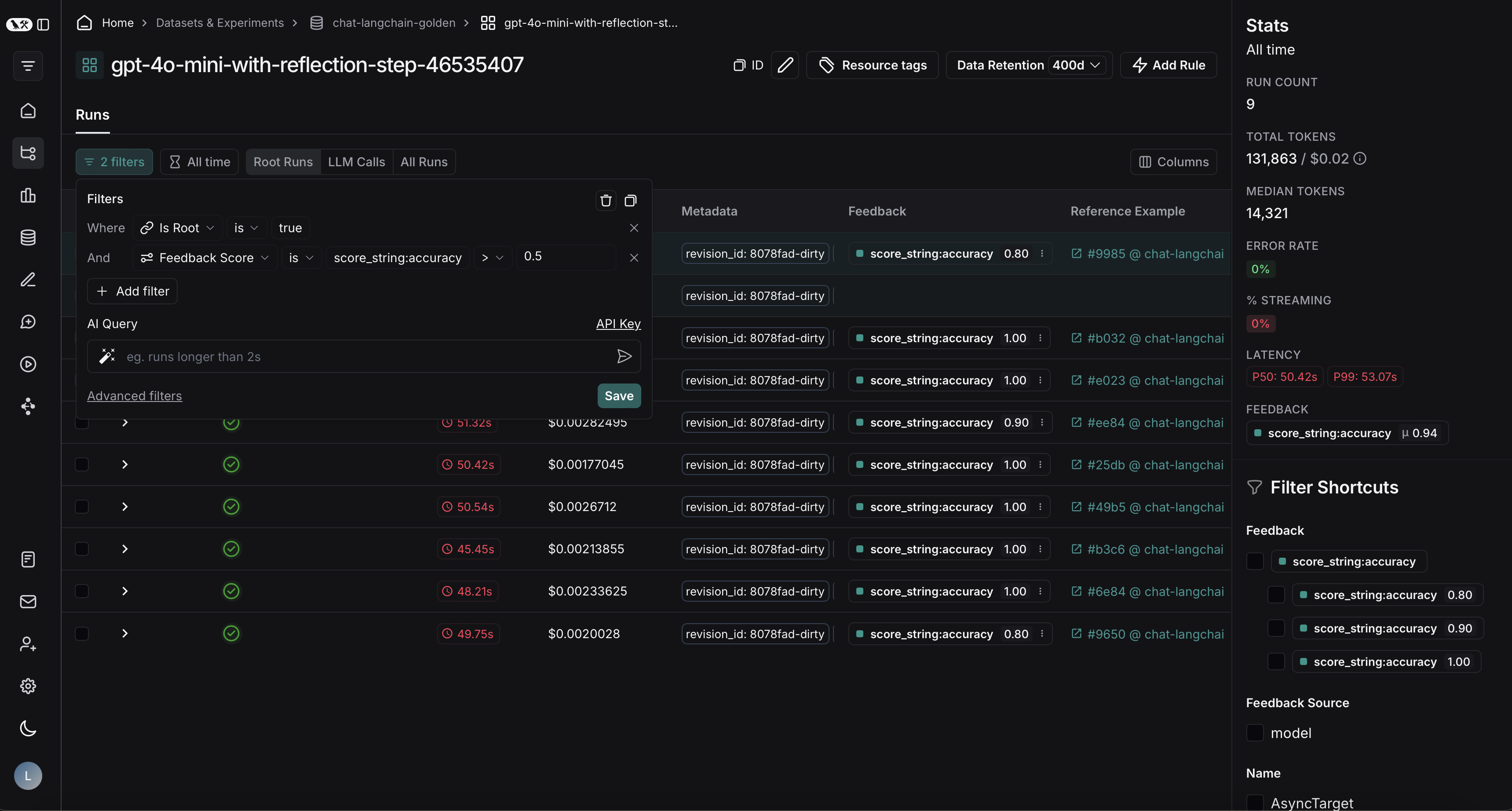
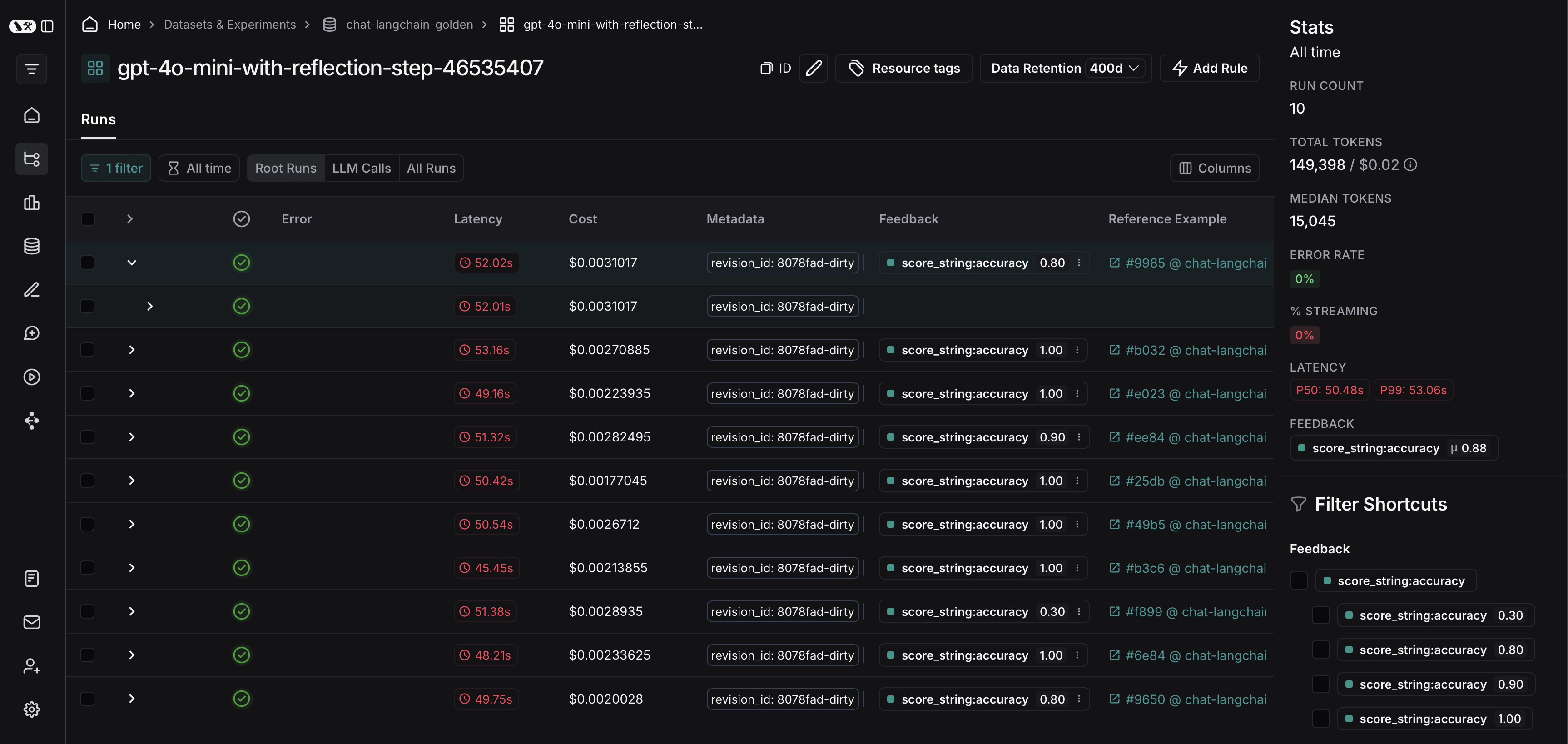 여기에서 평가 기준에 따라 trace를 필터링할 수 있습니다. 이 예제에서는 0.5보다 큰 accuracy 점수를 받은 모든 trace를 필터링합니다.
여기에서 평가 기준에 따라 trace를 필터링할 수 있습니다. 이 예제에서는 0.5보다 큰 accuracy 점수를 받은 모든 trace를 필터링합니다.
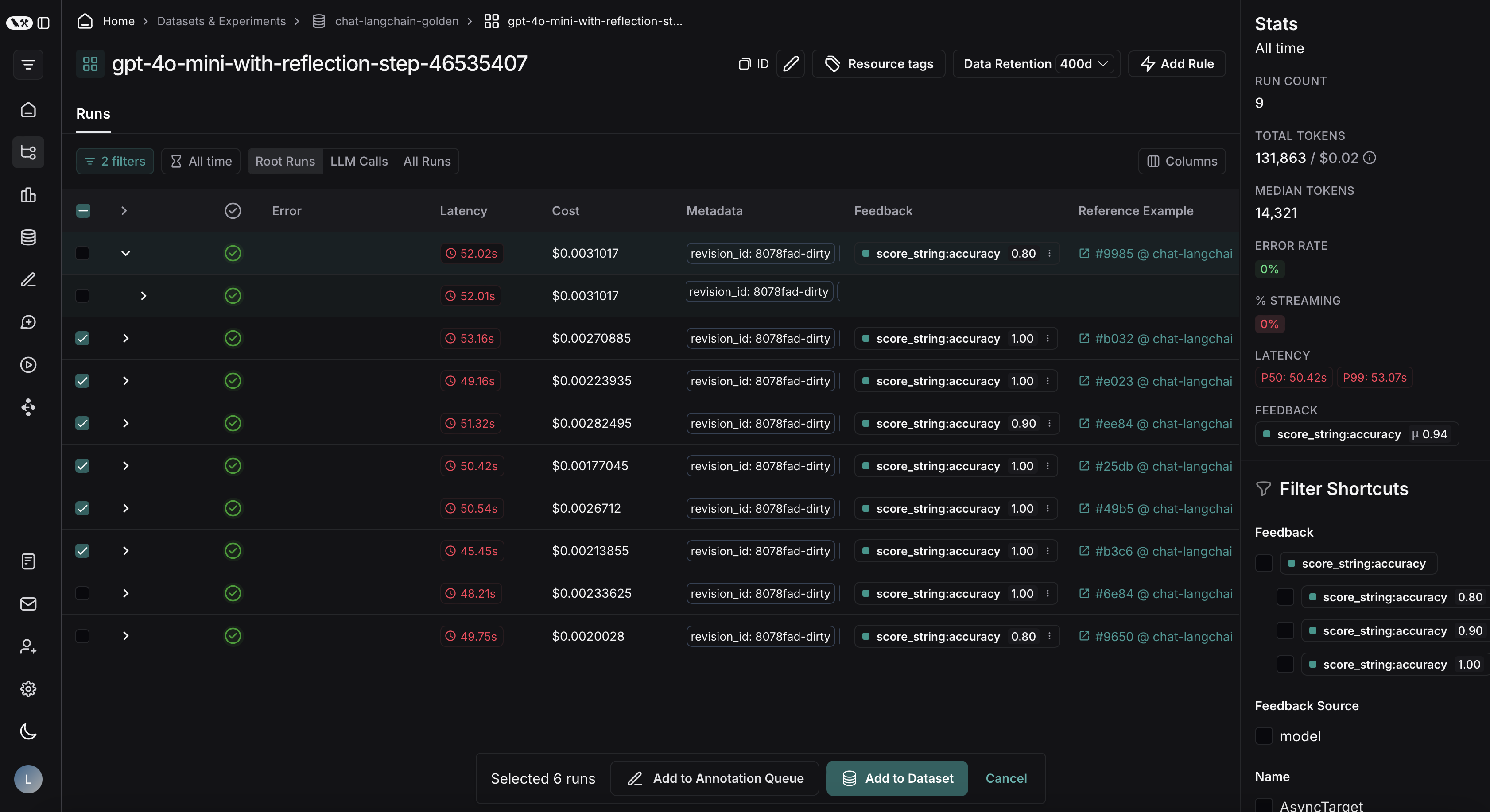
 프로젝트에 필터를 적용한 후 데이터셋에 추가할 run을 다중 선택하고 Add to Dataset을 클릭할 수 있습니다.
프로젝트에 필터를 적용한 후 데이터셋에 추가할 run을 다중 선택하고 Add to Dataset을 클릭할 수 있습니다.
Connect these docs programmatically to Claude, VSCode, and more via MCP for real-time answers.