

- 단일 실험 분석하기: 실험 결과를 보고 해석하며, 열을 사용자 정의하고, 데이터를 필터링하고, 실행을 비교합니다.
- 실험 결과를 CSV로 다운로드하기: 외부 분석 및 공유를 위해 실험 데이터를 내보냅니다.
- 실험 이름 변경하기: Playground와 Experiments 뷰 모두에서 실험 이름을 업데이트합니다.
단일 실험 분석하기
실험을 실행한 후, LangSmith의 experiment 뷰를 사용하여 결과를 분석하고 실험 성능에 대한 인사이트를 도출할 수 있습니다.experiment 뷰 열기
experiment 뷰를 열려면, Dataset & Experiments 페이지에서 관련 dataset을 선택한 다음 보려는 실험을 선택합니다.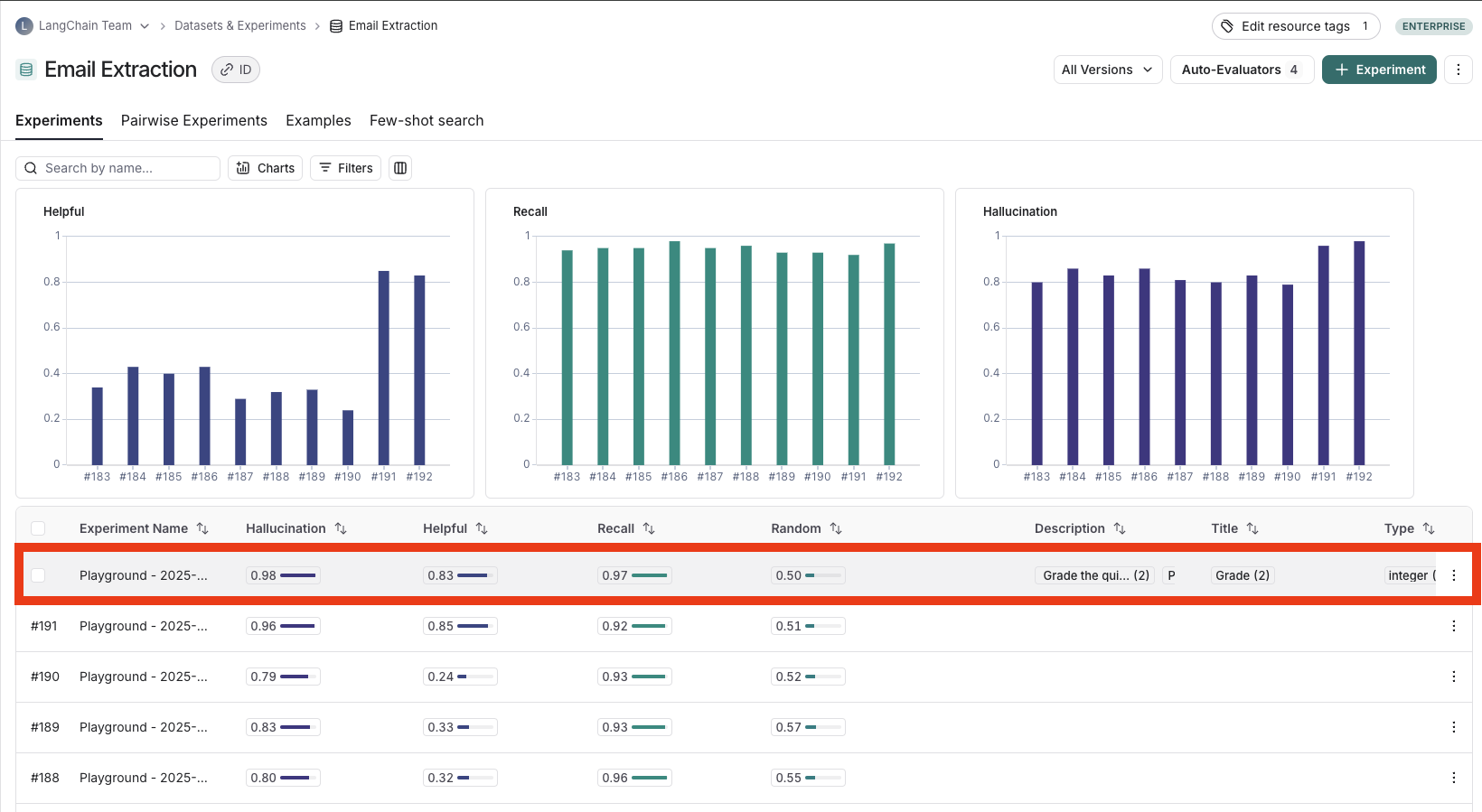
실험 결과 보기
열 사용자 정의하기
기본적으로 experiment 뷰는 dataset의 각 example에 대한 input, output, reference output과 평가의 feedback score, 그리고 비용, token 수, 지연 시간, 상태와 같은 실험 메트릭을 보여줍니다. Display 버튼을 사용하여 열을 사용자 정의하면 실험 결과를 더 쉽게 해석할 수 있습니다:- input, output, reference output의 필드를 분리하여 각각의 열로 만들 수 있습니다. 이는 특히 긴 input/output/reference output이 있고 중요한 필드를 표시하고 싶을 때 유용합니다.
- 열을 숨기고 재정렬하여 분석을 위한 집중된 뷰를 만들 수 있습니다.
- feedback score의 소수점 정밀도를 제어할 수 있습니다. 기본적으로 LangSmith는 숫자 feedback score를 소수점 2자리로 표시하지만, 이 설정을 최대 6자리까지 사용자 정의할 수 있습니다.
- Heat Map 임계값을 설정하여 실험의 숫자 feedback score에 대해 높음, 중간, 낮음으로 구분할 수 있으며, 이는 score chip이 빨간색 또는 녹색으로 렌더링되는 임계값에 영향을 줍니다:
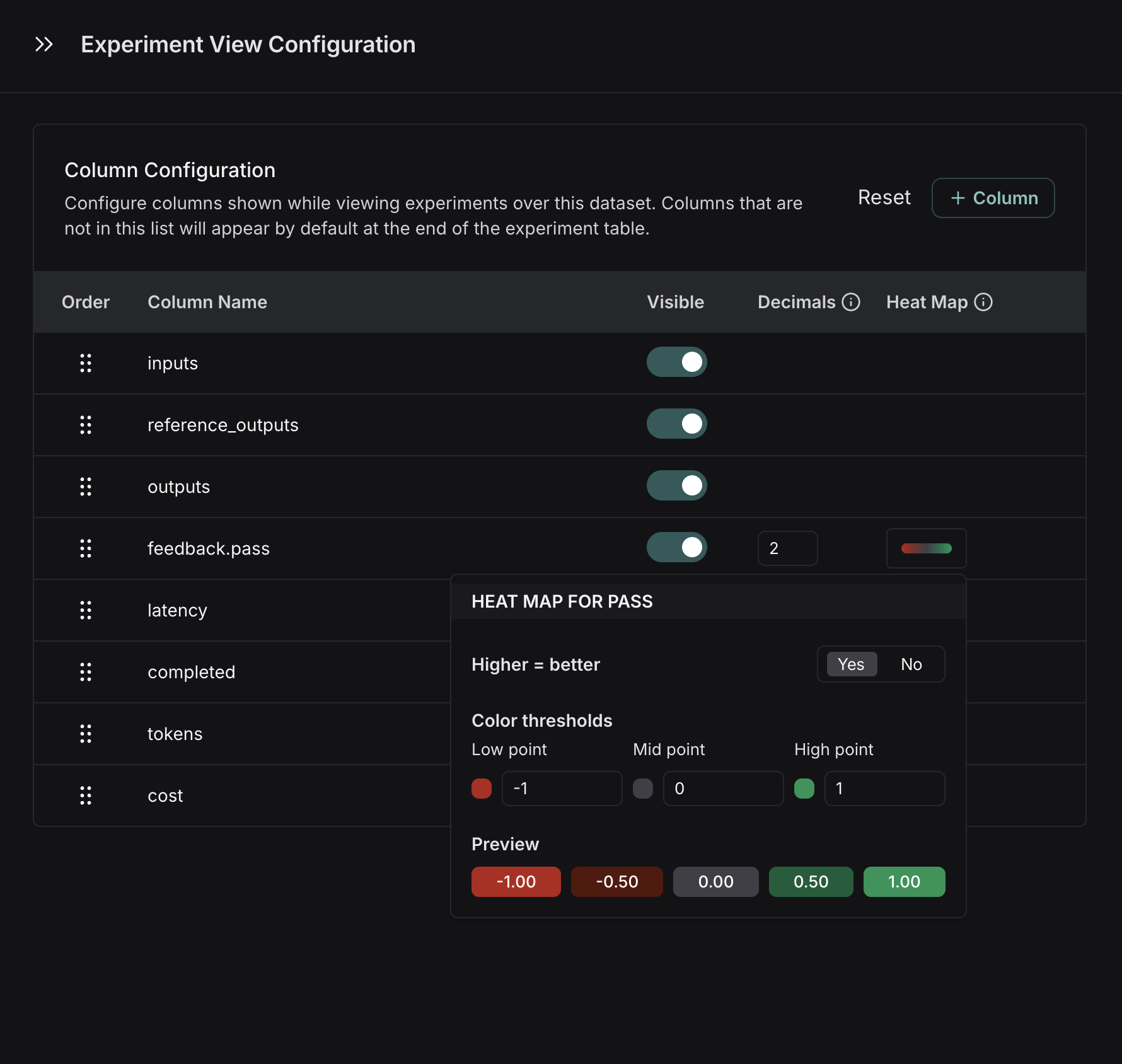
전체 dataset에 대한 기본 구성을 설정하거나 자신만을 위해 임시로 설정을 저장할 수 있습니다.
정렬 및 필터링
feedback score를 정렬하거나 필터링하려면 열 헤더의 작업을 사용할 수 있습니다.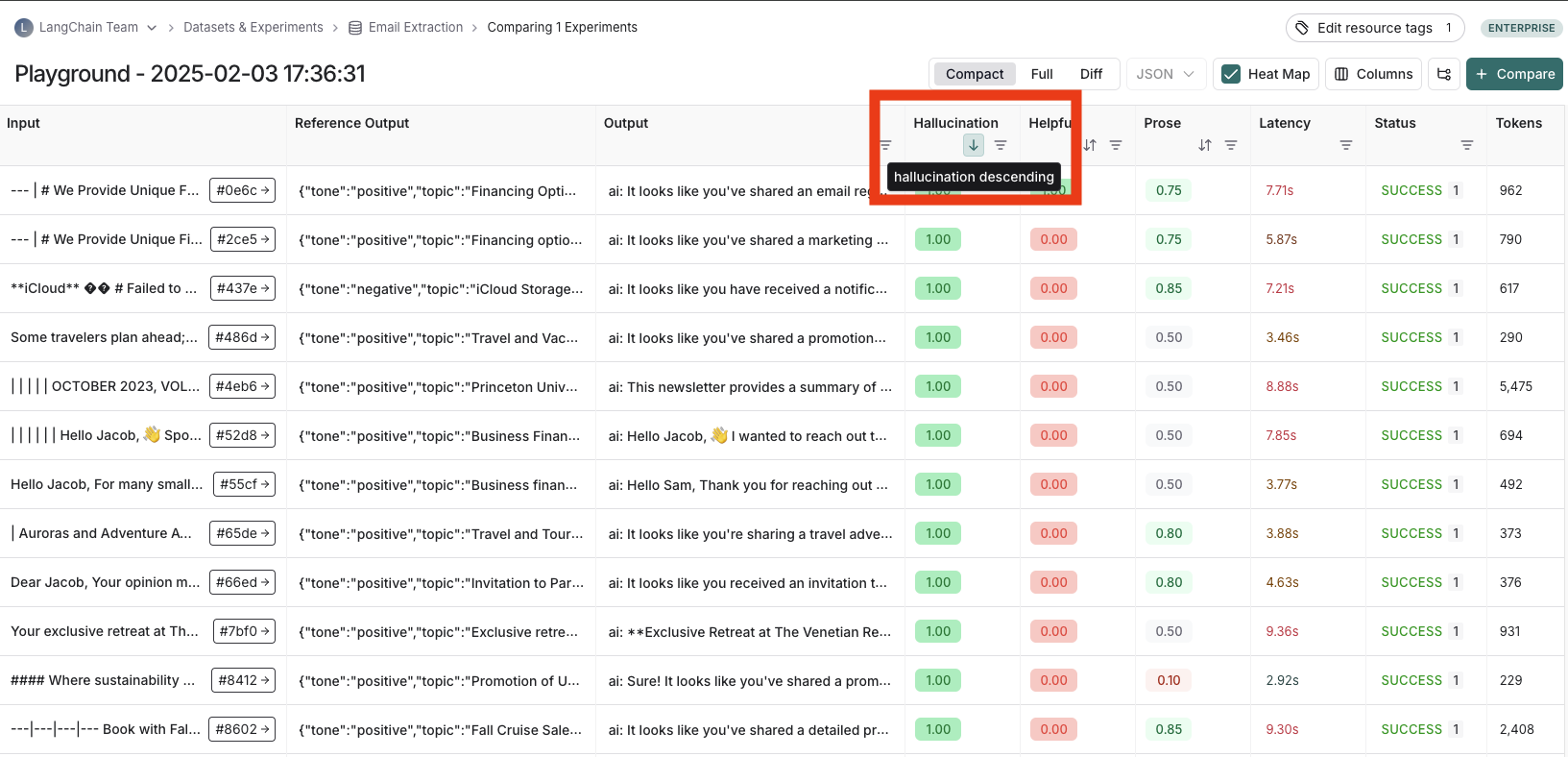
테이블 뷰
분석에 가장 유용한 뷰에 따라 compact 뷰, full 뷰, diff 뷰 간에 전환하여 테이블 형식을 변경할 수 있습니다.- Compact 뷰는 각 실행을 한 줄 행으로 표시하여 점수를 한눈에 비교하기 쉽게 합니다.
- Full 뷰는 개별 실행의 세부 사항을 파고들기 위해 각 실행의 전체 output을 표시합니다.
- Diff 뷰는 reference output과 각 실행의 output 간의 텍스트 차이를 표시합니다.
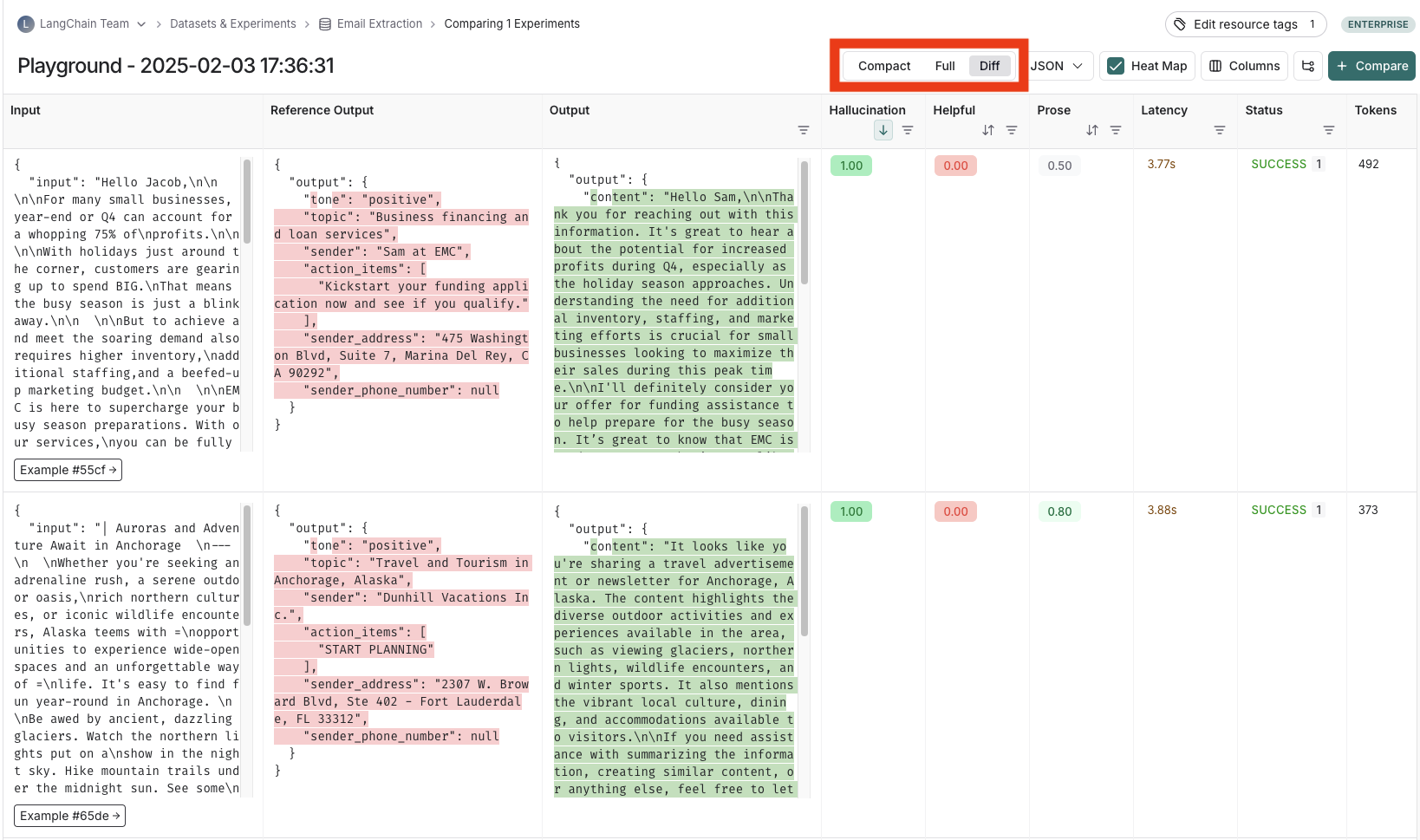
trace 보기
output cell 위에 마우스를 올리고 trace 아이콘을 클릭하면 해당 실행의 trace를 볼 수 있습니다. 이렇게 하면 사이드 패널에 trace가 열립니다. 전체 tracing project를 보려면 헤더 오른쪽 상단의 View Project 버튼을 클릭합니다.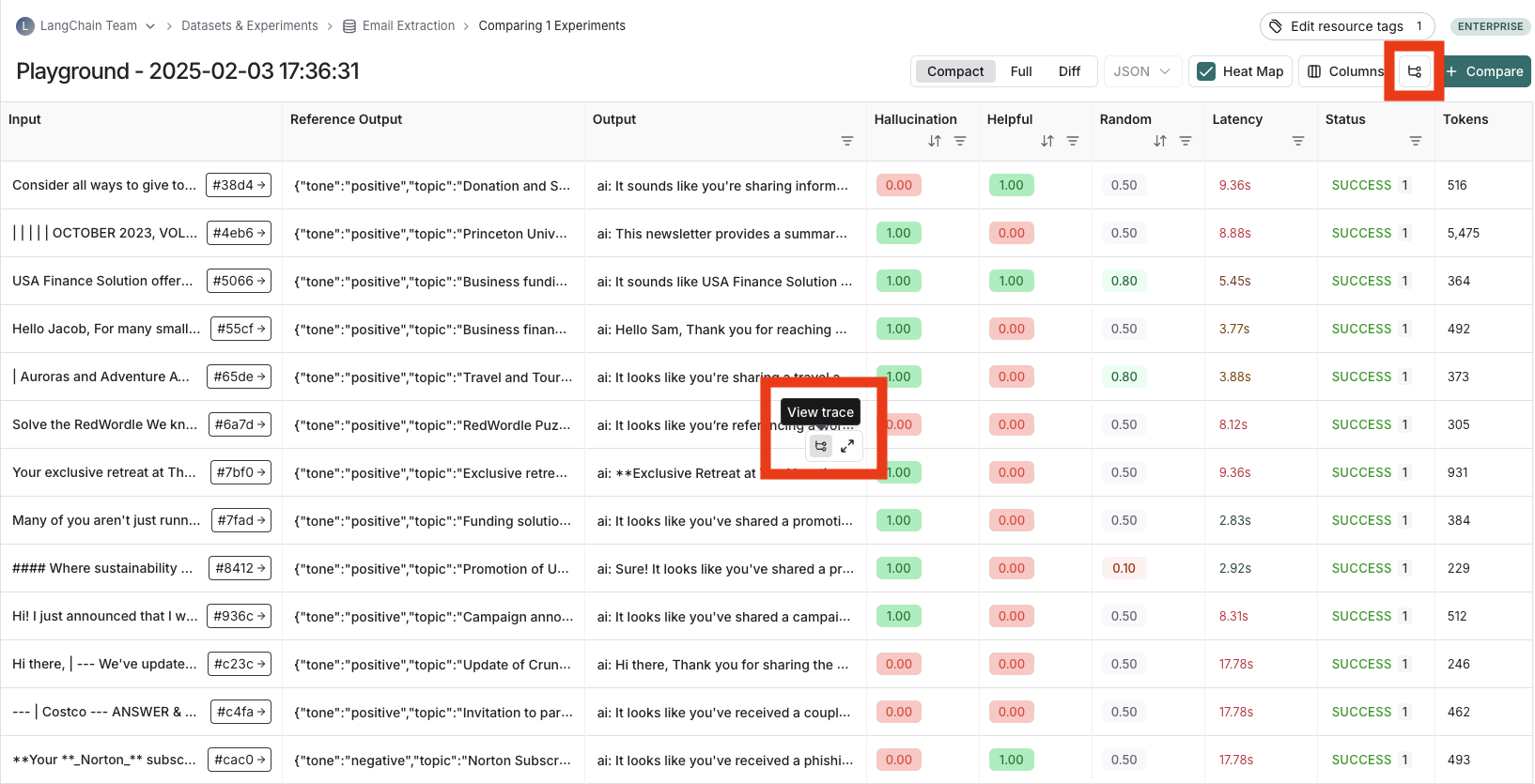
evaluator 실행 보기
evaluator score의 경우, evaluator score cell 위에 마우스를 올리고 화살표 아이콘을 클릭하여 소스 실행을 볼 수 있습니다. 이렇게 하면 사이드 패널에 trace가 열립니다. LLM-as-a-judge evaluator를 실행하는 경우, 이 실행에서 evaluator에 사용된 prompt를 볼 수 있습니다. 실험에 repetition이 있는 경우, 집계된 평균 점수를 클릭하여 모든 개별 실행에 대한 링크를 찾을 수 있습니다.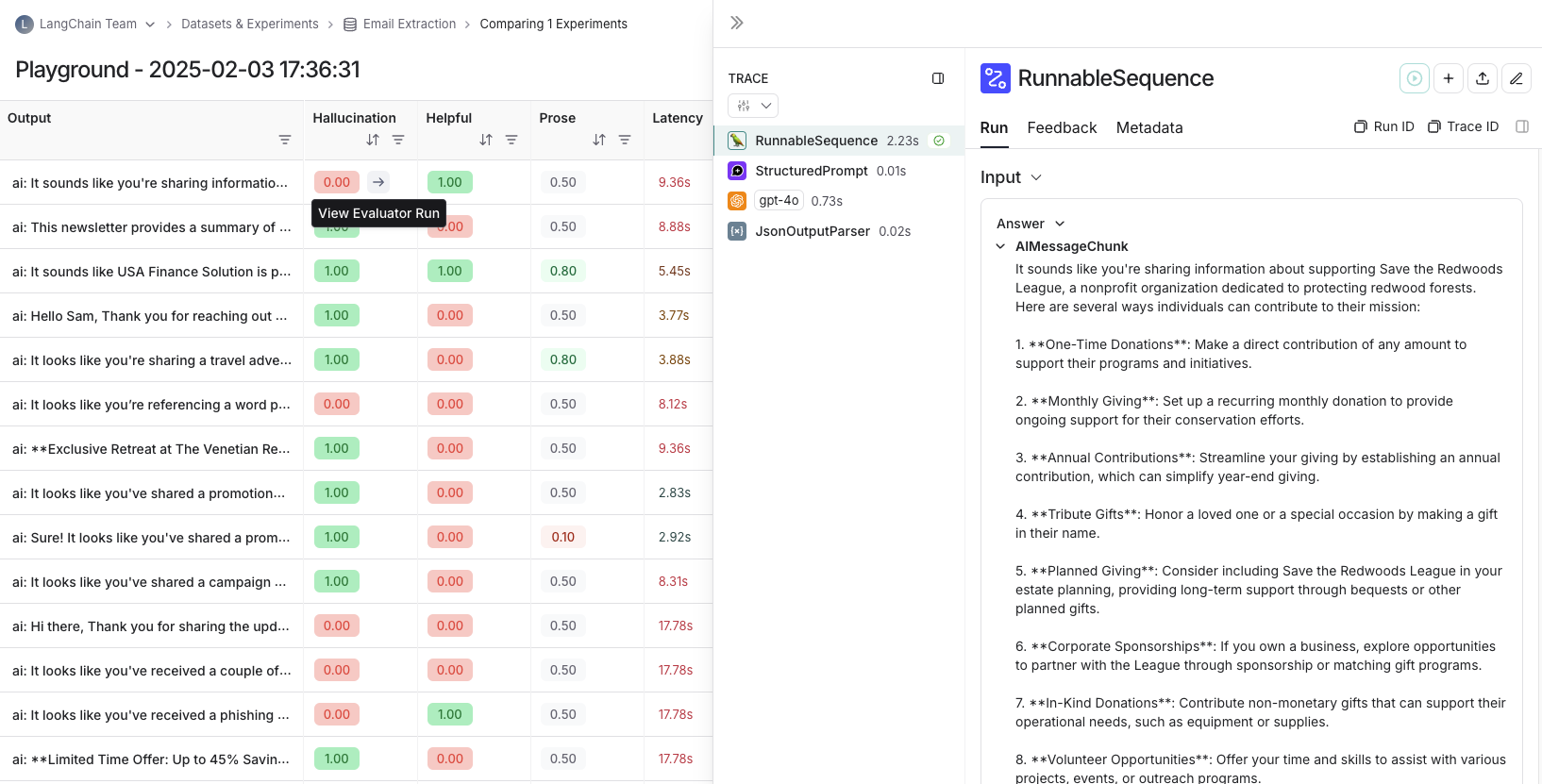
metadata로 결과 그룹화하기
example을 분류하고 구성하기 위해 metadata를 추가할 수 있습니다. 예를 들어, 질문 답변 dataset에서 사실 정확도를 평가하는 경우, metadata에는 각 질문이 속한 주제 영역이 포함될 수 있습니다. Metadata는 UI를 통해 또는 SDK를 통해 추가할 수 있습니다. metadata별로 결과를 분석하려면 experiment 뷰의 오른쪽 상단에 있는 Group by 드롭다운을 사용하고 원하는 metadata key를 선택합니다. 이렇게 하면 각 metadata 그룹에 대한 평균 feedback score, 지연 시간, 총 token 수, 비용이 표시됩니다.2025년 2월 20일 이후에 생성된 실험에서만 example metadata로 그룹화할 수 있습니다. 그 날짜 이전의 실험은 여전히 metadata로 그룹화할 수 있지만, metadata가 실험 trace 자체에 있는 경우에만 가능합니다.
Repetition
repetition으로 실험을 실행한 경우, output 결과 열에 화살표가 있어 테이블에서 output을 볼 수 있습니다. repetition의 각 실행을 보려면 output cell 위에 마우스를 올리고 확장 뷰를 클릭합니다. repetition으로 실험을 실행하면 LangSmith는 테이블에 각 feedback score의 평균을 표시합니다. feedback score를 클릭하면 개별 실행의 feedback score를 보거나 repetition 간의 표준 편차를 볼 수 있습니다.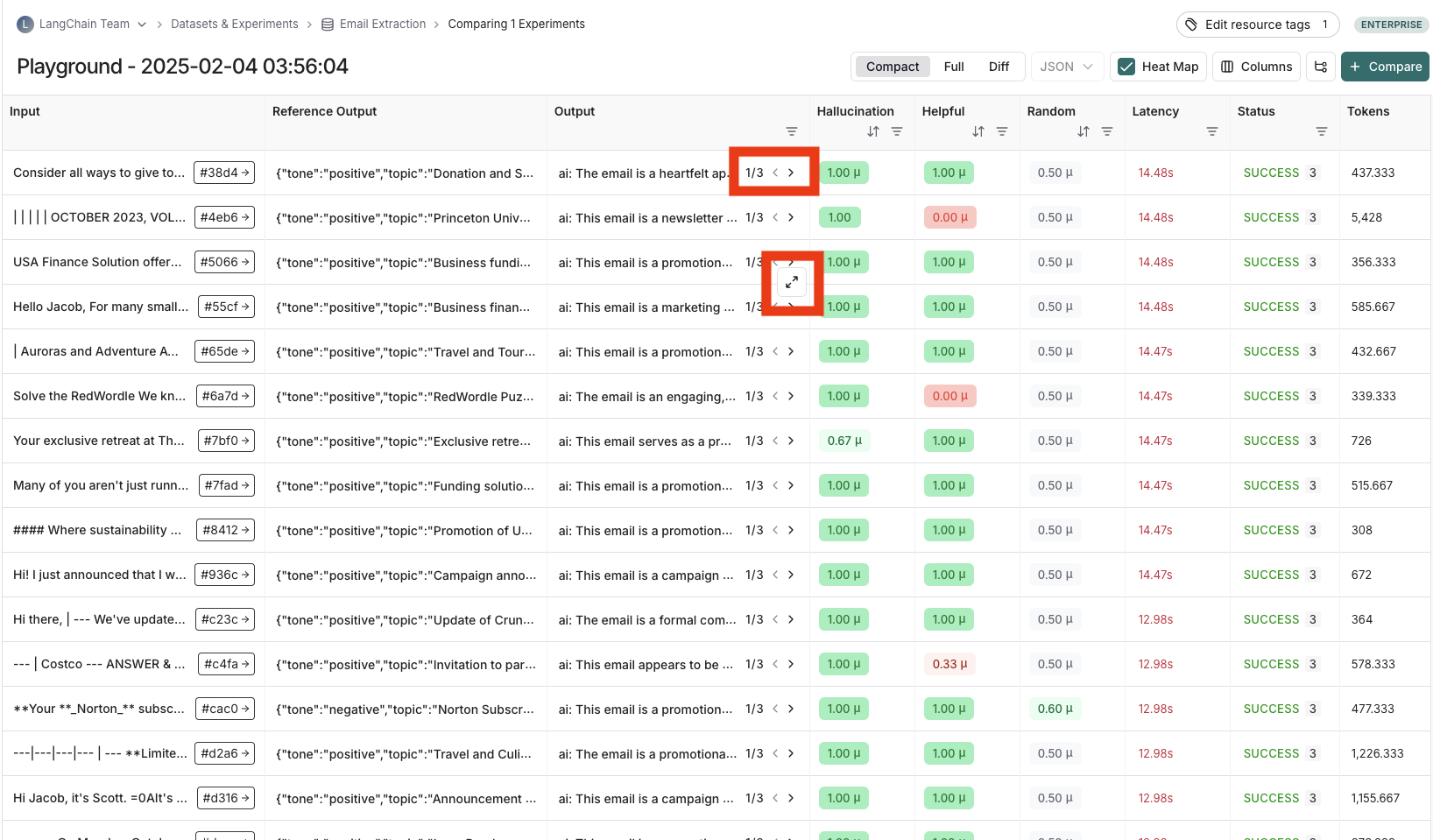
다른 실험과 비교하기
experiment 뷰의 오른쪽 상단에서 비교할 다른 실험을 선택할 수 있습니다. 이렇게 하면 두 실험을 비교할 수 있는 비교 뷰가 열립니다. 비교 뷰에 대해 자세히 알아보려면 실험 결과 비교 방법을 참조하세요.실험 결과를 CSV로 다운로드하기
LangSmith를 사용하면 실험 결과를 CSV 파일로 다운로드할 수 있어 결과를 분석하고 공유할 수 있습니다. CSV로 다운로드하려면 experiment 뷰 상단의 다운로드 아이콘을 클릭합니다. 이 아이콘은 Compact 토글 바로 왼쪽에 있습니다.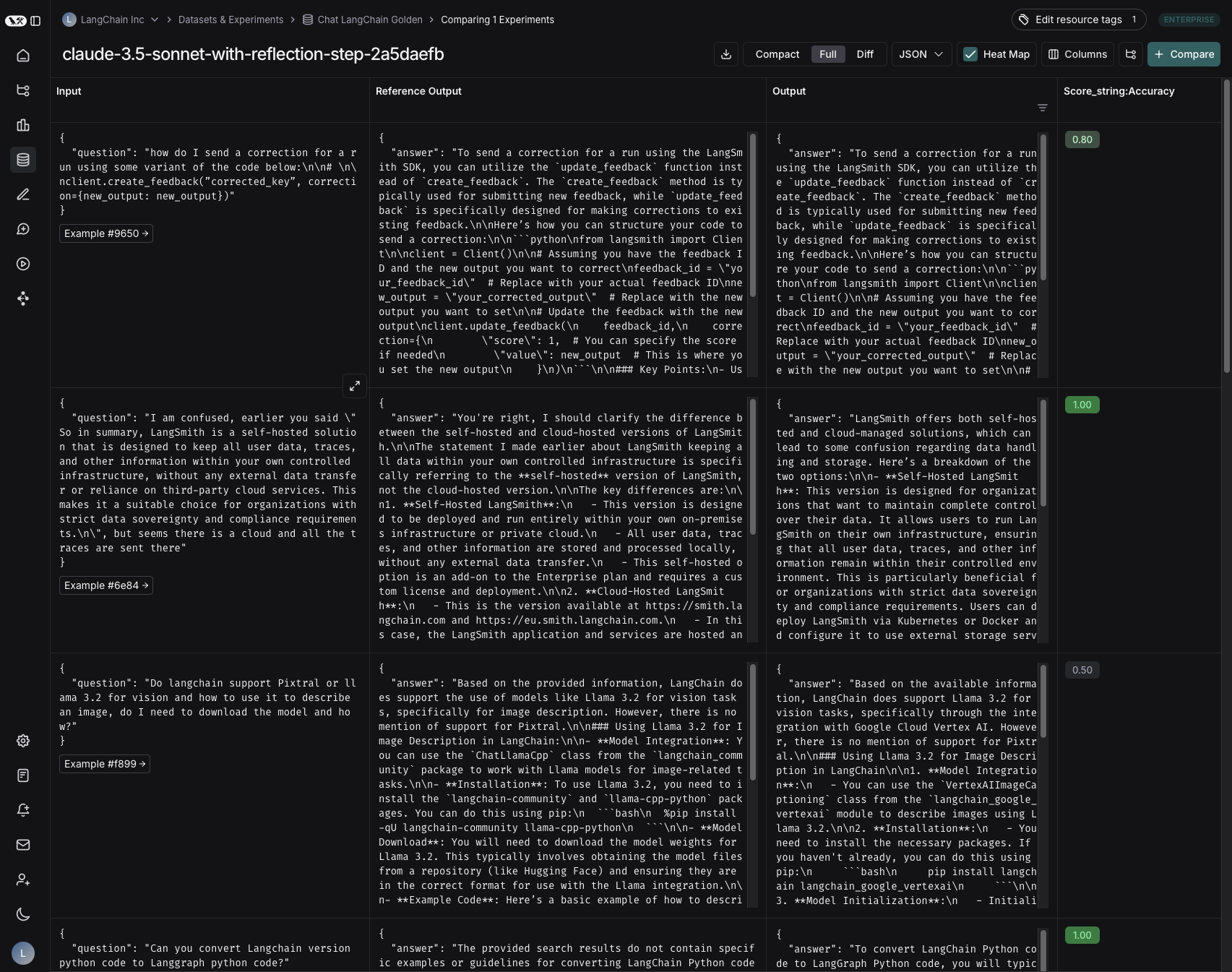
실험 이름 변경하기
실험 이름은 workspace당 고유해야 합니다.
-
Playground. Playground에서 실험을 실행할 때
pg::prompt-name::model::uuid형식의 기본 이름(예:pg::gpt-4o-mini::897ee630)이 자동으로 할당됩니다. Playground 테이블 헤더에서 이름을 편집하여 실험을 실행한 직후 이름을 변경할 수 있습니다.
-
Experiments 뷰. experiments 뷰에서 결과를 볼 때 실험 이름 옆의 연필 아이콘을 사용하여 실험 이름을 변경할 수 있습니다.

Connect these docs programmatically to Claude, VSCode, and more via MCP for real-time answers.