

- Datasets: 테스트 입력과 참조 출력의 모음입니다.
- Evaluators: 출력물을 점수화하는 함수입니다. 이는 실시간으로 trace에서 실행되는 online evaluators 또는 데이터셋에서 실행되는 offline evaluators일 수 있습니다.
Datasets
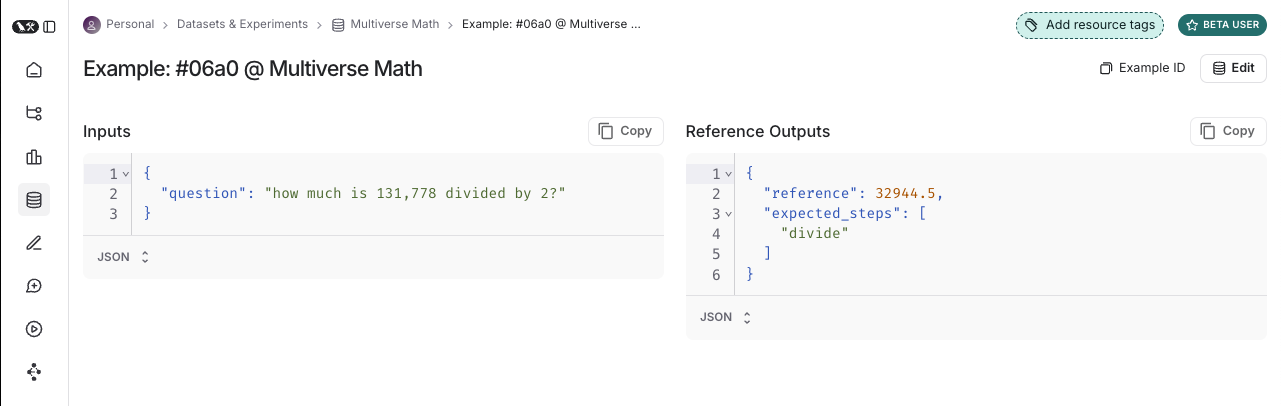
데이터셋은 애플리케이션 평가에 사용되는 예제들의 모음입니다. 예제란 테스트 입력과 참조 출력의 쌍입니다.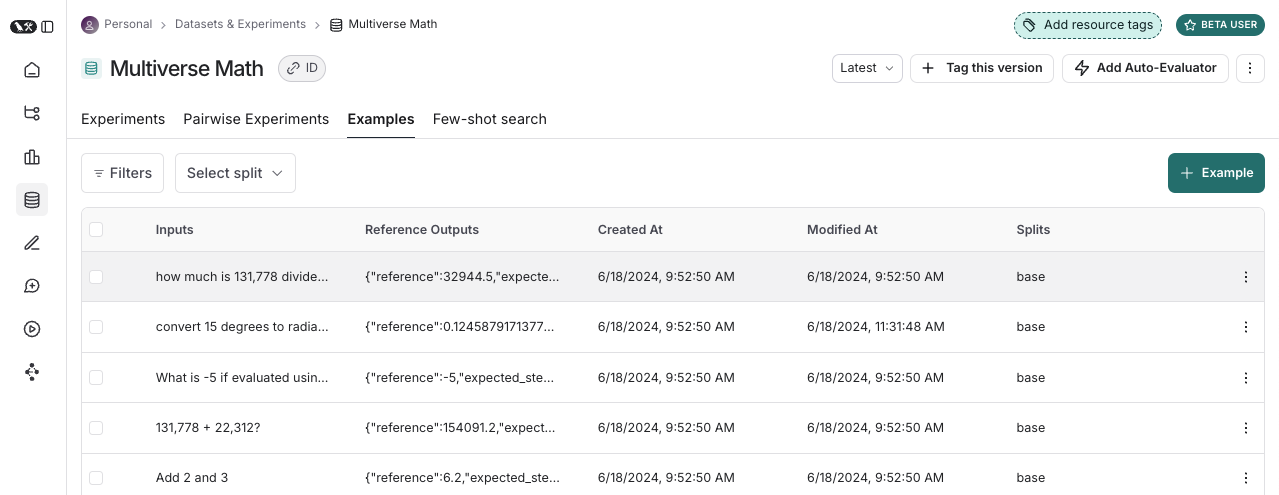
Examples
각 예제는 다음으로 구성됩니다:- Inputs: 애플리케이션에 전달할 입력 변수의 딕셔너리입니다.
- Reference outputs (선택 사항): 참조 출력의 딕셔너리입니다. 이는 애플리케이션에 전달되지 않고, 오직 evaluator에서만 사용됩니다.
- Metadata (선택 사항): 데이터셋의 필터링된 뷰를 생성하는 데 사용할 수 있는 추가 정보의 딕셔너리입니다.
데이터셋 큐레이션
평가를 위한 데이터셋을 구축하는 방법에는 여러 가지가 있습니다:수동 큐레이션 예제
대부분의 경우, 데이터셋을 만들 때 수동으로 예제를 큐레이션하는 방법을 추천합니다. 애플리케이션을 구축하면서, 어떤 유형의 입력을 처리할 수 있어야 하는지, 그리고 “좋은” 응답이 무엇인지에 대한 감이 있을 것입니다. 상상할 수 있는 몇 가지 일반적인 엣지 케이스나 상황을 커버하고 싶을 것입니다. 10~20개의 고품질 수동 큐레이션 예제만으로도 큰 도움이 됩니다.히스토리컬 트레이스
애플리케이션이 프로덕션에 들어가면, 실제 사용자가 어떻게 사용하는지에 대한 귀중한 정보를 얻게 됩니다. 이러한 실제 실행은 가장 현실적인 예제이기 때문에 훌륭한 데이터셋이 됩니다. 트래픽이 많을 경우, 어떤 실행을 데이터셋에 추가할 가치가 있는지 어떻게 결정할 수 있을까요? 사용할 수 있는 몇 가지 기법이 있습니다:- User feedback: 가능하다면 최종 사용자 피드백을 수집하세요. 어떤 데이터포인트가 부정적인 피드백을 받았는지 확인할 수 있습니다. 이는 매우 가치 있는 정보입니다! 애플리케이션이 제대로 동작하지 않은 부분이므로, 이러한 예제를 데이터셋에 추가하여 향후 테스트에 활용하세요.
- Heuristics: “흥미로운” 데이터포인트를 식별하기 위해 다른 휴리스틱을 사용할 수도 있습니다. 예를 들어, 실행 시간이 오래 걸린 경우, 이를 데이터셋에 추가해 살펴볼 수 있습니다.
- LLM feedback: 또 다른 LLM을 사용해 주목할 만한 실행을 감지할 수 있습니다. 예를 들어, 사용자가 질문을 다시 표현하거나 모델을 수정해야 했던 챗봇 대화를 LLM으로 라벨링하여 챗봇이 처음에 올바르게 응답하지 않았음을 나타낼 수 있습니다.
합성 데이터
몇 가지 예제가 준비되면, 인위적으로 더 많은 예제를 생성해볼 수 있습니다. 일반적으로, 합성 데이터를 만들기 전에 몇 개의 고품질 수작업 예제를 준비하는 것이 좋습니다. 합성 데이터는 종종 기존 예제를 어느 정도 닮기 때문입니다. 빠르게 많은 데이터포인트를 얻는 데 유용한 방법입니다.Splits
평가를 설정할 때, 데이터셋을 여러 split으로 분할할 수 있습니다. 예를 들어, 빠르고 저렴한 반복을 위해 작은 split을 사용하고, 최종 평가를 위해 더 큰 split을 사용할 수 있습니다. 또한 split은 실험의 해석 가능성 측면에서도 중요합니다. 예를 들어, RAG 애플리케이션의 경우, 데이터셋 split을 다양한 질문 유형(예: 사실, 의견 등)에 집중시켜 각 split별로 애플리케이션을 평가할 수 있습니다. 데이터셋 split 생성 및 관리 방법을 알아보세요.Versions
데이터셋은 버전 관리가 되어, 예제를 추가, 업데이트, 삭제할 때마다 새로운 버전이 생성됩니다. 이를 통해 실수로 변경한 경우에도 데이터셋의 변경 사항을 쉽게 확인하고 되돌릴 수 있습니다. 또한 버전에 태그를 달아 사람이 읽기 쉬운 이름을 부여할 수 있습니다. 이는 데이터셋의 중요한 이정표를 표시하는 데 유용합니다. 특정 버전의 데이터셋에 대해 평가를 실행할 수 있습니다. 이는 CI에서 평가를 실행할 때, 데이터셋 업데이트가 CI 파이프라인을 실수로 깨뜨리지 않도록 하는 데 유용합니다.Evaluators
Evaluator는 애플리케이션이 특정 예제에서 얼마나 잘 동작하는지 점수화하는 함수입니다.Evaluator 입력값
Evaluator는 다음 입력값을 받습니다:- Example: Dataset의 예제(들)입니다. 입력값, (참조) 출력값, 메타데이터를 포함합니다.
- Run: 예제 입력을 애플리케이션에 전달하여 얻은 실제 출력 및 중간 단계(child runs)입니다.
Evaluator 출력값
Evaluator는 하나 이상의 metric을 반환합니다. 이는 다음과 같은 형태의 딕셔너리 또는 딕셔너리 리스트로 반환되어야 합니다:key: metric의 이름score|value: metric의 값. 숫자 metric에는score, 범주형 metric에는value를 사용하세요.comment(선택 사항): 점수에 대한 근거 또는 추가 정보 문자열
Evaluator 정의
Evaluator를 정의하고 실행하는 방법에는 여러 가지가 있습니다:- Custom code: 커스텀 evaluator를 Python 또는 TypeScript 함수로 정의하고, SDK를 통해 클라이언트 측에서 실행하거나 UI를 통해 서버 측에서 실행할 수 있습니다.
- Built-in evaluators: LangSmith에는 UI를 통해 구성하고 실행할 수 있는 여러 내장 evaluator가 있습니다.
평가 기법
LLM 평가에는 몇 가지 상위 수준의 접근 방식이 있습니다:Human
휴먼 평가는 평가의 훌륭한 시작점이 되는 경우가 많습니다. LangSmith는 LLM 애플리케이션의 출력과 trace(모든 중간 단계)를 쉽게 검토할 수 있도록 지원합니다. LangSmith의 annotation queue를 사용하면 애플리케이션 출력에 대해 휴먼 피드백을 쉽게 받을 수 있습니다.Heuristic
휴리스틱 evaluator는 결정적이고 규칙 기반의 함수입니다. 챗봇 응답이 비어 있지 않은지, 생성된 코드가 컴파일되는지, 분류가 정확한지 등 간단한 체크에 적합합니다.LLM-as-judge
LLM-as-judge evaluator는 LLM을 사용해 애플리케이션의 출력을 점수화합니다. 이를 사용하려면 일반적으로 grading 규칙/기준을 LLM 프롬프트에 인코딩합니다. 참조 없이도 사용할 수 있고(예: 시스템 출력에 공격적인 내용이 포함되어 있는지, 특정 기준을 준수하는지 확인), 참조 출력과 비교할 수도 있습니다(예: 출력이 참조에 비해 사실적으로 정확한지 확인). LLM-as-judge evaluator를 사용할 때는 결과 점수를 신중하게 검토하고 필요하다면 grader 프롬프트를 조정하는 것이 중요합니다. 종종 few-shot evaluator로 작성하는 것이 도움이 되며, 입력, 출력, 기대 등급의 예시를 grader 프롬프트에 포함합니다. LLM-as-a-judge evaluator 정의 방법을 알아보세요.Pairwise
Pairwise evaluator는 애플리케이션의 두 버전의 출력을 비교할 수 있게 해줍니다. LMSYS Chatbot Arena와 같은 개념이지만, 모델뿐 아니라 AI 애플리케이션 전반에 적용됩니다! 휴리스틱(“어떤 응답이 더 긴가”), LLM(특정 pairwise 프롬프트), 휴먼(직접 예제를 주석 처리) 등 다양한 방식으로 사용할 수 있습니다. 언제 pairwise 평가를 사용해야 할까요? LLM 출력에 직접 점수를 매기기 어렵지만 두 출력을 비교하는 것이 더 쉬운 경우 pairwise 평가가 유용합니다. 예를 들어 요약 작업에서는 요약에 절대 점수를 주기 어렵지만, 두 요약 중 어느 것이 더 정보가 풍부한지 선택하는 것은 쉽습니다. Pairwise 평가 실행 방법을 알아보세요.Experiment
애플리케이션을 데이터셋에 평가할 때마다 하나의 experiment를 수행하는 것입니다. experiment에는 특정 버전의 애플리케이션을 데이터셋에 실행한 결과가 포함됩니다. LangSmith experiment 뷰 사용법은 experiment 결과 분석 방법을 참고하세요.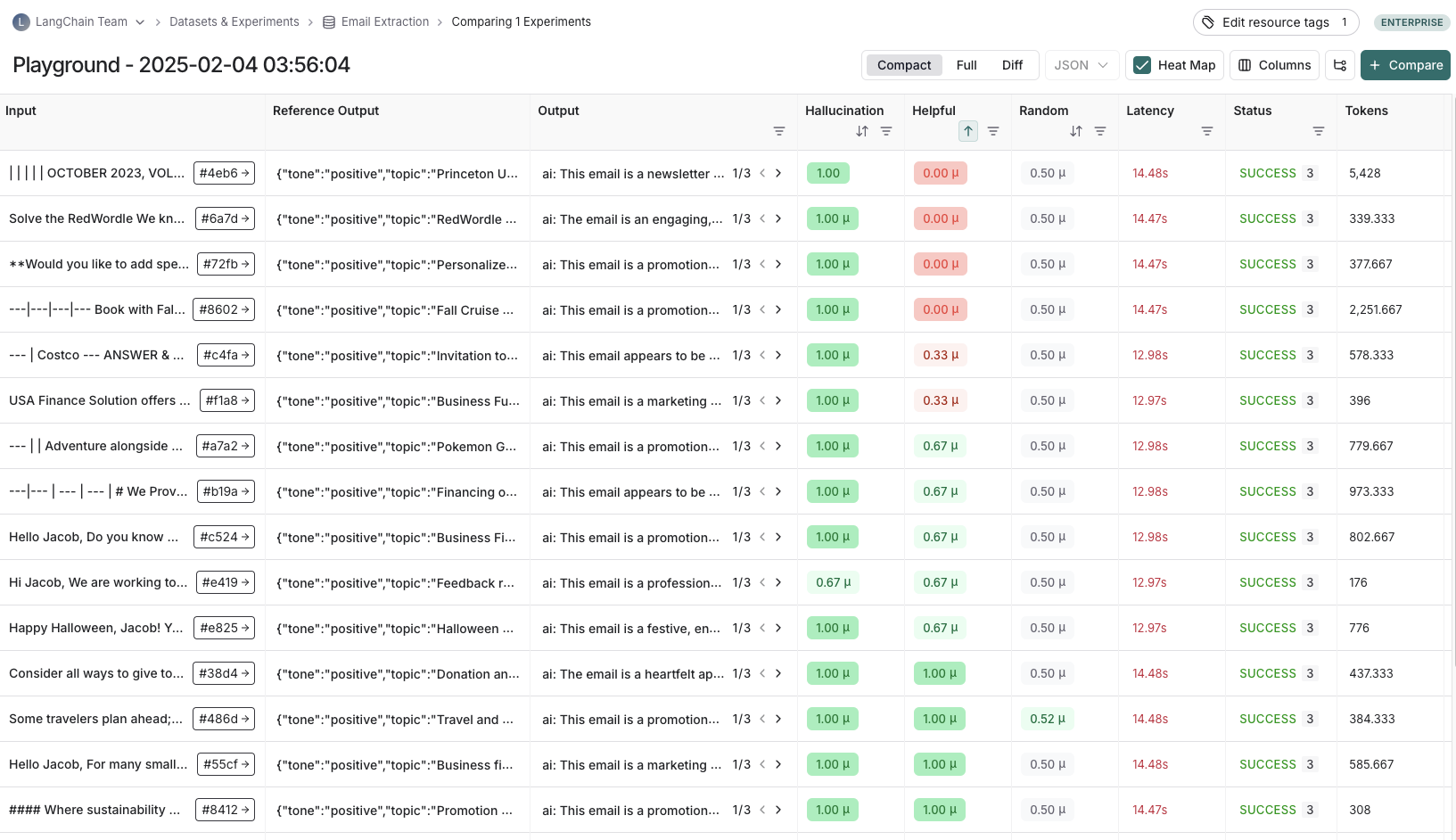 일반적으로 하나의 데이터셋에 대해 여러 experiment를 실행하여 애플리케이션의 다양한 구성(예: 프롬프트, LLM 등)을 테스트합니다. LangSmith에서는 데이터셋과 연결된 모든 experiment를 쉽게 볼 수 있습니다. 또한 여러 experiment를 비교 뷰에서 비교할 수 있습니다.
일반적으로 하나의 데이터셋에 대해 여러 experiment를 실행하여 애플리케이션의 다양한 구성(예: 프롬프트, LLM 등)을 테스트합니다. LangSmith에서는 데이터셋과 연결된 모든 experiment를 쉽게 볼 수 있습니다. 또한 여러 experiment를 비교 뷰에서 비교할 수 있습니다.
Experiment 구성
LangSmith는 원하는 방식으로 평가를 실행할 수 있도록 다양한 experiment 구성을 지원합니다.반복 실행
experiment를 여러 번 실행하는 것은 LLM 출력이 결정적이지 않고 반복마다 다를 수 있기 때문에 도움이 됩니다. 여러 번 반복 실행하면 시스템 성능을 더 정확하게 추정할 수 있습니다. 반복 실행은evaluate / aevaluate에 num_repetitions 인자를 전달하여 구성할 수 있습니다(Python, TypeScript). experiment를 반복 실행하면 출력 생성 대상 함수와 evaluator 모두를 다시 실행하게 됩니다.
experiment 반복 실행에 대해 더 알아보려면 how-to-guide를 참고하세요.
동시성
evaluate / aevaluate에 max_concurrency 인자를 전달하여 experiment의 동시성을 지정할 수 있습니다. max_concurrency 인자는 evaluate와 aevaluate에 따라 의미가 약간 다릅니다.
evaluate
evaluate의 max_concurrency 인자는 experiment 실행 시 사용할 최대 동시 스레드 수를 지정합니다. 이는 대상 함수 실행과 evaluator 실행 모두에 적용됩니다.
aevaluate
aevaluate의 max_concurrency 인자는 evaluate와 유사하지만, 동시에 실행할 수 있는 작업 수를 제한하기 위해 세마포어를 사용합니다. aevaluate는 데이터셋의 각 예제에 대해 작업을 생성합니다. 각 작업은 해당 예제에 대해 대상 함수와 모든 evaluator를 실행하는 것으로 구성됩니다. max_concurrency 인자는 동시에 실행할 최대 작업(즉, 예제) 수를 지정합니다.
캐싱
마지막으로, 실험에서 발생하는 API 호출을 캐시하려면LANGSMITH_TEST_CACHE를 쓰기 권한이 있는 유효한 폴더로 설정하세요. 이렇게 하면 실험에서 발생하는 API 호출이 디스크에 캐시되어, 동일한 API 호출을 하는 향후 실험의 속도가 크게 빨라집니다.
Annotation queues
휴먼 피드백은 애플리케이션에서 얻을 수 있는 가장 가치 있는 피드백인 경우가 많습니다. annotation queue를 사용하면 애플리케이션 실행을 annotation 대상으로 지정할 수 있습니다. 휴먼 annotator는 큐에 있는 실행을 검토하고 피드백을 제공할 수 있는 간편한 뷰를 갖게 됩니다. 종종 이러한 annotation된 실행(일부 또는 전체)은 데이터셋으로 이전되어 향후 평가에 사용됩니다. 실행을 인라인으로 annotation할 수도 있지만, annotation queue는 실행을 그룹화하고, annotation 기준을 지정하며, 권한을 구성할 수 있는 또 다른 옵션을 제공합니다. annotation queue와 휴먼 피드백에 대해 더 알아보세요.Offline evaluation
애플리케이션을 데이터셋에 평가하는 것을 “offline” 평가라고 합니다. offline 평가란 미리 준비된 데이터셋을 대상으로 평가하는 것입니다. 반면, online 평가는 배포된 애플리케이션의 출력을 실제 트래픽에 대해 거의 실시간으로 평가하는 것입니다. offline 평가는 애플리케이션의 버전을 배포 전에 테스트하는 데 사용됩니다. offline 평가는 LangSmith SDK(Python, TypeScript)를 사용해 클라이언트 측에서 실행할 수 있습니다. 서버 측에서는 Prompt Playground 또는 automations를 구성해 특정 evaluator를 새로운 experiment마다 특정 데이터셋에 실행할 수 있습니다.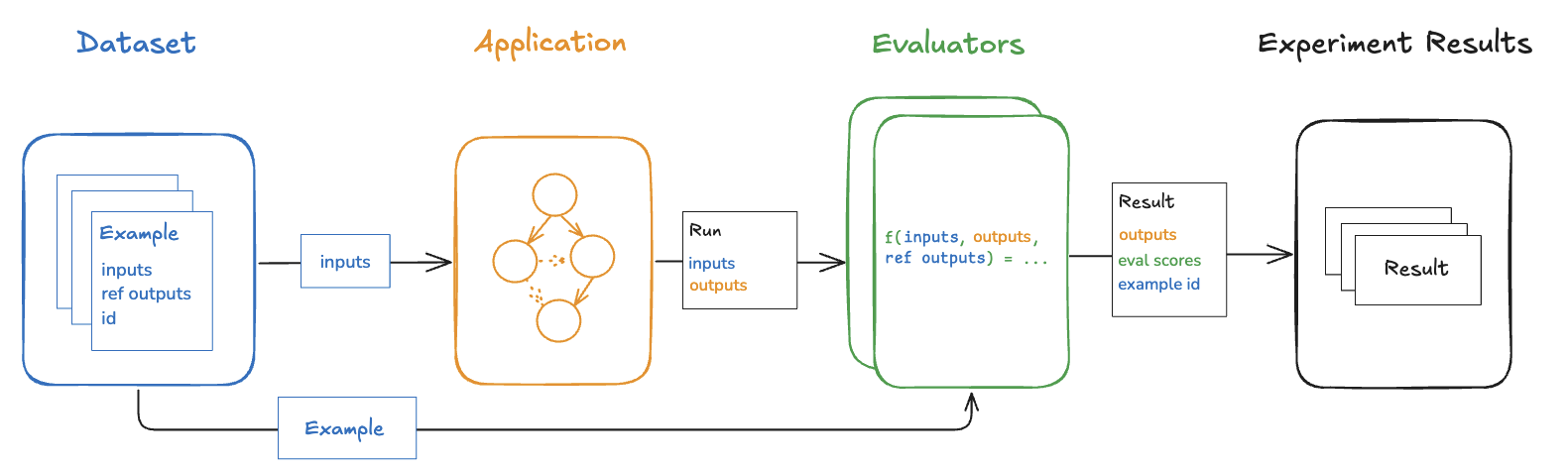
벤치마킹
offline 평가의 가장 일반적인 유형은 대표적인 입력 데이터셋을 큐레이션하고, 핵심 성능 metric을 정의한 뒤, 여러 버전의 애플리케이션을 벤치마킹하여 최적의 버전을 찾는 것입니다. 벤치마킹은 많은 경우 gold-standard 참조 출력이 포함된 데이터셋을 큐레이션하고, 실험 출력을 비교할 좋은 metric을 설계해야 하므로 수고가 많이 듭니다. 예를 들어 RAG Q&A 봇의 경우, 질문과 참조 답변의 데이터셋, 그리고 실제 답변이 참조 답변과 의미적으로 동등한지 판단하는 LLM-as-judge evaluator가 필요합니다. ReACT agent의 경우, 사용자 요청과 모델이 호출해야 하는 모든 툴 호출의 참조 집합, 그리고 모든 참조 툴 호출이 실제로 이루어졌는지 확인하는 휴리스틱 evaluator가 필요합니다.단위 테스트
단위 테스트는 소프트웨어 개발에서 시스템의 개별 구성 요소의 정확성을 검증하는 데 사용됩니다. LLM 맥락에서의 단위 테스트는 종종 입력 또는 출력에 대한 규칙 기반 assertion(예: LLM이 생성한 코드가 컴파일되는지, JSON이 로드되는지 등)으로 기본 기능을 검증합니다. 단위 테스트는 항상 통과해야 한다는 기대를 갖고 작성하는 경우가 많습니다. 이러한 테스트는 CI의 일부로 실행하기에 적합합니다. 이때 LLM 호출을 최소화하기 위해 캐시를 설정하는 것이 유용합니다(LMM 호출 비용이 빠르게 증가할 수 있기 때문입니다).회귀 테스트
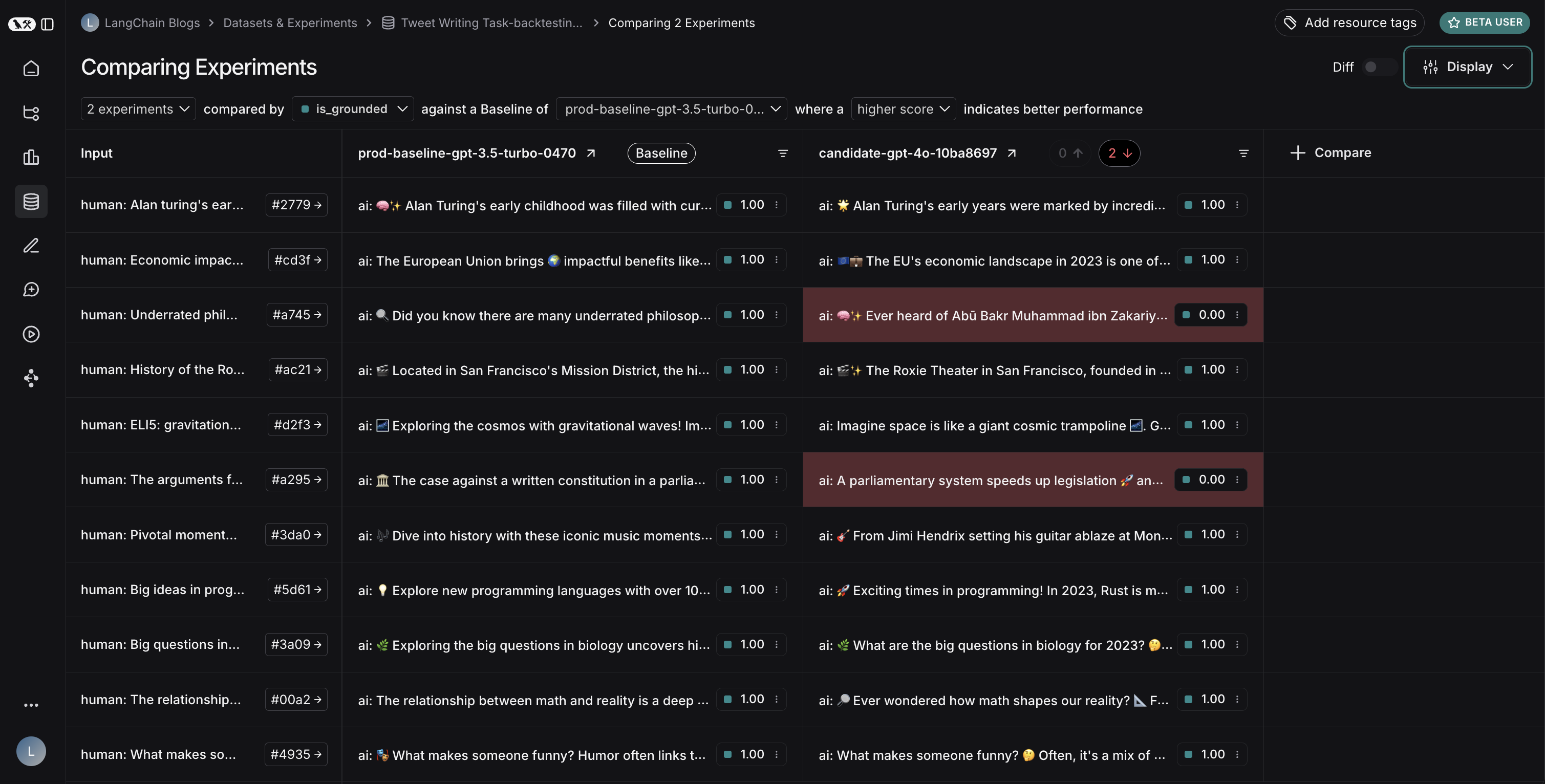
회귀 테스트는 시간에 따라 애플리케이션의 버전별 성능을 측정하는 데 사용됩니다. 최소한 새로운 앱 버전이 현재 버전에서 올바르게 처리하는 예제에서 성능이 저하되지 않도록 보장하며, 이상적으로는 새로운 버전이 얼마나 더 나은지 측정합니다. 주로 모델이나 아키텍처 등 사용자 경험에 영향을 줄 것으로 예상되는 앱 업데이트 시 실행됩니다. LangSmith의 비교 뷰는 회귀 테스트를 네이티브로 지원하여, 기준선 대비 변경된 예제를 빠르게 확인할 수 있습니다. 회귀는 빨간색, 개선은 초록색으로 표시됩니다.
백테스팅
백테스팅은 데이터셋 생성(위에서 설명)과 평가를 결합한 접근 방식입니다. 프로덕션 로그가 있다면 이를 데이터셋으로 변환할 수 있습니다. 그런 다음, 최신 애플리케이션 버전으로 해당 프로덕션 예제를 다시 실행할 수 있습니다. 이를 통해 과거의 실제 사용자 입력에 대한 성능을 평가할 수 있습니다. 이는 새로운 모델 버전을 평가할 때 흔히 사용됩니다. 예를 들어, Anthropic에서 새로운 모델이 출시되었다면, 최근 1000개의 애플리케이션 실행을 새로운 모델로 처리한 뒤, 실제 프로덕션 결과와 비교할 수 있습니다.Pairwise 평가
일부 작업에서는 휴먼 또는 LLM grader가 “버전 A가 B보다 낫다”를 판단하는 것이 A 또는 B에 절대 점수를 부여하는 것보다 더 쉽습니다. Pairwise 평가는 두 버전의 출력을 서로 비교하여 점수화하는 것으로, 참조 출력이나 절대 기준과 비교하는 것이 아닙니다. Pairwise 평가는 보다 일반적인 작업에서 LLM-as-judge evaluator를 사용할 때 유용합니다. 예를 들어, 요약 애플리케이션의 경우, LLM-as-judge가 “이 두 요약 중 어느 것이 더 명확하고 간결한가?”를 판단하는 것이 “명확성과 간결성 측면에서 1~10점으로 평가하라”보다 더 쉽습니다. Pairwise 평가 실행 방법을 알아보세요.Online evaluation
배포된 애플리케이션의 출력을 (거의) 실시간으로 평가하는 것을 “online” 평가라고 합니다. 이 경우 데이터셋이나 참조 출력이 없으며, 실제 입력과 실제 출력에 대해 evaluator를 실행합니다. 이는 애플리케이션을 모니터링하고 의도하지 않은 동작을 감지하는 데 유용합니다. online 평가는 offline 평가와 함께 사용할 수도 있습니다. 예를 들어, online evaluator를 사용해 입력 질문을 여러 카테고리로 분류하고, 이를 기반으로 offline 평가용 데이터셋을 큐레이션할 수 있습니다. online evaluator는 일반적으로 서버 측에서 실행하도록 설계되었습니다. LangSmith에는 구성 가능한 LLM-as-judge evaluator가 내장되어 있으며, 커스텀 코드 evaluator도 LangSmith 내에서 실행할 수 있습니다.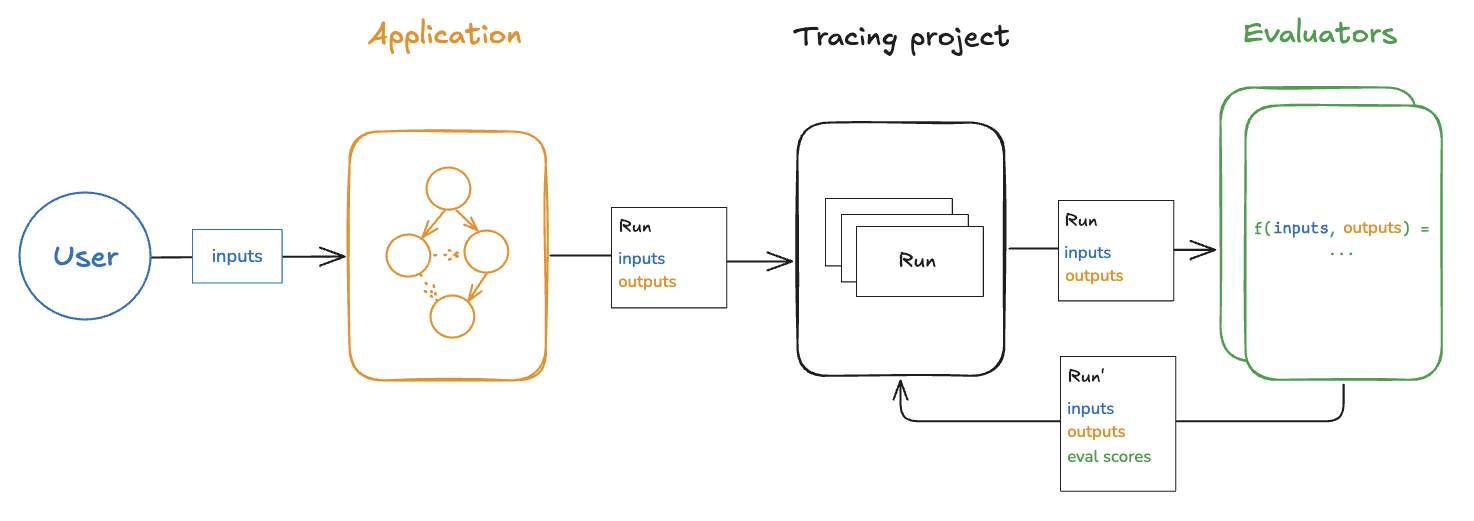
Testing
평가와 테스트의 차이
테스트와 평가는 매우 유사하고 겹치는 개념으로, 종종 혼동됩니다. 평가는 metric에 따라 성능을 측정합니다. 평가 metric은 모호하거나 주관적일 수 있으며, 절대적인 값보다는 상대적인 비교에 더 유용합니다. 즉, 개별 시스템에 대해 단언하기보다는 두 시스템을 서로 비교하는 데 자주 사용됩니다. 테스트는 정확성을 단언합니다. 모든 테스트를 통과해야만 시스템을 배포할 수 있습니다. 평가 metric을 테스트로 변환할 수도 있습니다. 예를 들어, 회귀 테스트를 작성하여 시스템의 새로운 버전이 관련 평가 metric에서 기준선 버전보다 반드시 더 뛰어나야 한다고 단언할 수 있습니다. 시스템 실행 비용이 높고 테스트와 평가에 중복되는 데이터셋이 있다면, 테스트와 평가를 함께 실행하는 것이 더 효율적일 수 있습니다. 편의상pytest 또는 vitest/jest와 같은 표준 소프트웨어 테스트 도구를 사용해 평가를 작성할 수도 있습니다.
pytest 및 Vitest/Jest 사용
LangSmith SDK는 pytest 및 Vitest/Jest와의 통합 기능을 제공합니다. 이를 통해 다음을 쉽게 할 수 있습니다:
- LangSmith에서 테스트 결과 추적
- 평가를 테스트로 작성
Connect these docs programmatically to Claude, VSCode, and more via MCP for real-time answers.