LangSmith는 JavaScript 및 TypeScript 개발자가 익숙한 구문을 사용하여 데이터셋을 정의하고 평가할 수 있도록 Vitest 및 Jest와의 통합을 제공합니다.

evaluate() 평가 플로우와 비교했을 때, 다음과 같은 경우에 유용합니다:
- 각 예제가 서로 다른 평가 로직을 필요로 하는 경우
- 이진 기대값을 단언하고, 이러한 단언을 LangSmith에서 추적하면서 동시에 로컬에서 단언 오류를 발생시키고자 하는 경우 (예: CI 파이프라인에서)
- Vitest/Jest 생태계의 mock, watch mode, 로컬 결과 또는 기타 기능을 활용하고자 하는 경우
JS/TS SDK 버전 langsmith>=0.3.1이 필요합니다.
Vitest/Jest 통합은 베타 버전이며 향후 릴리스에서 변경될 수 있습니다.
*.test.ts 파일로), 아래 예제에서는 평가를 실행하기 위한 별도의 테스트 설정 파일과 명령을 설정합니다. 테스트 파일이 .eval.ts로 끝난다고 가정합니다.
이렇게 하면 사용자 정의 테스트 리포터 및 기타 LangSmith 접점이 기존 테스트 출력을 수정하지 않도록 보장합니다.
Vitest
아직 설치하지 않았다면 필요한 개발 의존성을 설치합니다:
yarn add -D vitest dotenv
openai (그리고 물론 langsmith!)도 의존성으로 필요합니다:
yarn add langsmith openai
ls.vitest.config.ts 파일을 생성합니다:
import { defineConfig } from "vitest/config";
export default defineConfig({
test: {
include: ["**/*.eval.?(c|m)[jt]s"],
reporters: ["langsmith/vitest/reporter"],
setupFiles: ["dotenv/config"],
},
});
include는 프로젝트에서 eval.ts의 일부 변형으로 끝나는 파일만 실행되도록 보장합니다reporters는 위에 표시된 것처럼 출력을 깔끔하게 포맷하는 역할을 합니다setupFiles는 평가를 실행하기 전에 환경 변수를 로드하기 위해 dotenv를 실행합니다
JSDom 환경은 현재 지원되지 않습니다. 설정에서 "environment" 필드를 생략하거나 "node"로 설정해야 합니다.
package.json의 scripts 필드에 다음을 추가합니다:
{
"name": "YOUR_PROJECT_NAME",
"scripts": {
"eval": "vitest run --config ls.vitest.config.ts"
},
"dependencies": {
...
},
"devDependencies": {
...
}
}
Jest
아직 설치하지 않았다면 필요한 개발 의존성을 설치합니다:
아래 예제에는 openai (그리고 물론 langsmith!)도 의존성으로 필요합니다:
yarn add langsmith openai
아래 설정 지침은 기본 JS 파일 및 CJS용입니다. TypeScript 및 ESM 지원을 추가하려면 Jest의 공식 문서를 참조하거나 Vitest를 사용하세요. ls.jest.config.cjs라는 별도의 설정 파일을 생성합니다:
module.exports = {
testMatch: ["**/*.eval.?(c|m)[jt]s"],
reporters: ["langsmith/jest/reporter"],
setupFiles: ["dotenv/config"],
};
testMatch는 프로젝트에서 eval.js의 일부 변형으로 끝나는 파일만 실행되도록 보장합니다reporters는 위에 표시된 것처럼 출력을 깔끔하게 포맷하는 역할을 합니다setupFiles는 평가를 실행하기 전에 환경 변수를 로드하기 위해 dotenv를 실행합니다
JSDom 환경은 현재 지원되지 않습니다. 설정에서 "testEnvironment" 필드를 생략하거나 "node"로 설정해야 합니다.
package.json의 scripts 필드에 다음을 추가합니다:
{
"name": "YOUR_PROJECT_NAME",
"scripts": {
"eval": "jest --config ls.jest.config.cjs"
},
"dependencies": {
...
},
"devDependencies": {
...
}
}
평가 정의 및 실행
이제 익숙한 Vitest/Jest 구문을 사용하여 평가를 테스트로 정의할 수 있습니다. 몇 가지 주의사항이 있습니다:
langsmith/jest 또는 langsmith/vitest 엔트리포인트에서 describe 및 test를 import해야 합니다- 테스트 케이스를
describe 블록으로 감싸야 합니다
- 테스트를 선언할 때 시그니처가 약간 다릅니다 - 예제 입력 및 예상 출력을 포함하는 추가 인수가 있습니다
sql.eval.ts (또는 TypeScript 없이 Jest를 사용하는 경우 sql.eval.js)라는 파일을 생성하고 아래 내용을 붙여넣어 시도해 보세요:
import * as ls from "langsmith/vitest";
import { expect } from "vitest";
// import * as ls from "langsmith/jest";
// import { expect } from "@jest/globals";
import OpenAI from "openai";
import { traceable } from "langsmith/traceable";
import { wrapOpenAI } from "langsmith/wrappers/openai";
// Add "openai" as a dependency and set OPENAI_API_KEY as an environment variable
const tracedClient = wrapOpenAI(new OpenAI());
const generateSql = traceable(
async (userQuery: string) => {
const result = await tracedClient.chat.completions.create({
model: "gpt-4o-mini",
messages: [
{
role: "system",
content:
"Convert the user query to a SQL query. Do not wrap in any markdown tags.",
},
{
role: "user",
content: userQuery,
},
],
});
return result.choices[0].message.content;
},
{ name: "generate_sql" }
);
ls.describe("generate sql demo", () => {
ls.test(
"generates select all",
{
inputs: { userQuery: "Get all users from the customers table" },
referenceOutputs: { sql: "SELECT * FROM customers;" },
},
async ({ inputs, referenceOutputs }) => {
const sql = await generateSql(inputs.userQuery);
ls.logOutputs({ sql }); // <-- Log run outputs, optional
expect(sql).toEqual(referenceOutputs?.sql); // <-- Assertion result logged under 'pass' feedback key
}
);
});
ls.test() 케이스를 데이터셋 예제에 해당하는 것으로, ls.describe()를 LangSmith 데이터셋을 정의하는 것으로 생각할 수 있습니다. 테스트 스위트를 실행할 때 LangSmith 추적 환경 변수가 설정되어 있으면 SDK는 다음을 수행합니다:
- LangSmith에 존재하지 않는 경우
ls.describe()에 전달된 이름과 동일한 이름의 데이터셋을 생성합니다
- 일치하는 예제가 아직 존재하지 않는 경우 각 입력 및 예상 출력에 대해 데이터셋에 예제를 생성합니다
- 각 테스트 케이스에 대해 하나의 결과를 가진 새로운 실험을 생성합니다
- 각 테스트 케이스에 대해
pass 피드백 키 아래에 합격/불합격 비율을 수집합니다
이 테스트를 실행하면 테스트 케이스의 합격/불합격을 기반으로 기본 pass boolean 피드백 키가 생성됩니다. 또한 ls.logOutputs()로 로깅하거나 테스트 함수에서 반환하는 모든 출력을 실험의 앱에서 나온 “실제” 결과 값으로 추적합니다.
아직 없다면 OPENAI_API_KEY 및 LangSmith 자격 증명이 포함된 .env 파일을 생성합니다:
OPENAI_API_KEY="YOUR_KEY_HERE"
LANGSMITH_API_KEY="YOUR_LANGSMITH_KEY"
LANGSMITH_TRACING="true"
eval 스크립트를 사용하여 테스트를 실행합니다:
그러면 선언된 테스트가 실행됩니다!
완료되면 LangSmith 환경 변수를 설정한 경우 테스트 결과와 함께 LangSmith에서 생성된 실험으로 연결되는 링크가 표시됩니다.
다음은 해당 테스트 스위트에 대한 실험의 모습입니다:
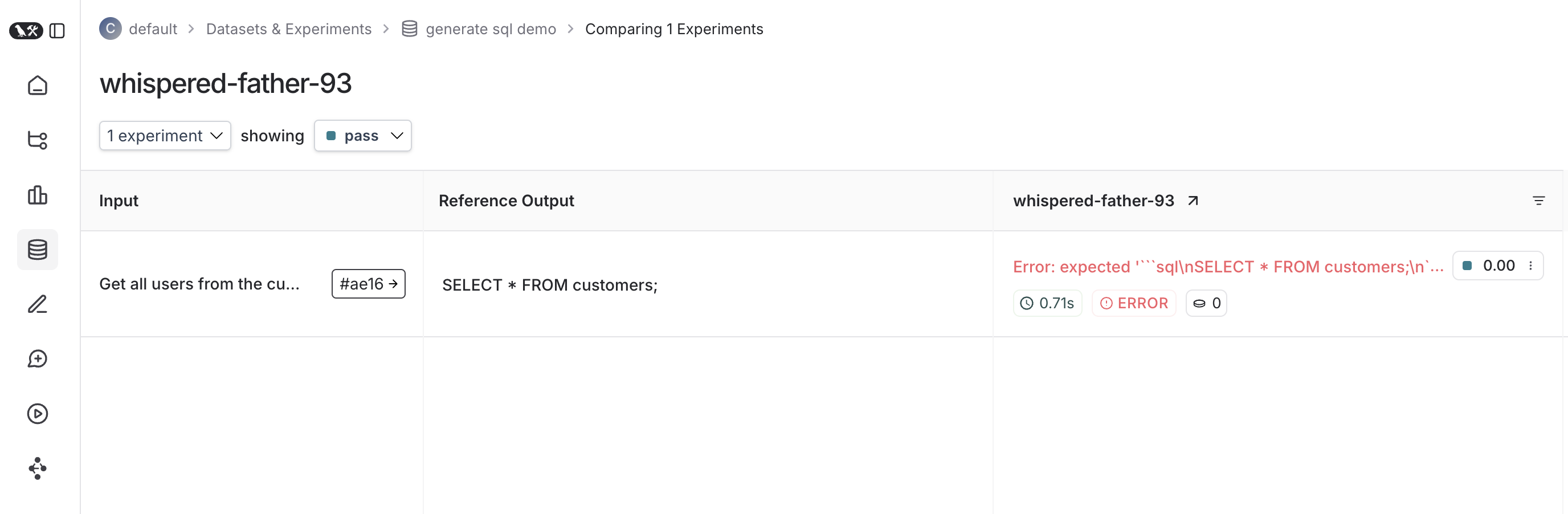
추적 피드백
기본적으로 LangSmith는 각 테스트 케이스에 대해 pass 피드백 키 아래에 합격/불합격 비율을 수집합니다. ls.logFeedback() 또는 wrapEvaluator()를 사용하여 추가 피드백을 추가할 수 있습니다. 이를 위해 sql.eval.ts 파일 (또는 TypeScript 없이 Jest를 사용하는 경우 sql.eval.js)에 다음을 시도해 보세요:
import * as ls from "langsmith/vitest";
// import * as ls from "langsmith/jest";
import OpenAI from "openai";
import { traceable } from "langsmith/traceable";
import { wrapOpenAI } from "langsmith/wrappers/openai";
// Add "openai" as a dependency and set OPENAI_API_KEY as an environment variable
const tracedClient = wrapOpenAI(new OpenAI());
const generateSql = traceable(
async (userQuery: string) => {
const result = await tracedClient.chat.completions.create({
model: "gpt-4o-mini",
messages: [
{
role: "system",
content:
"Convert the user query to a SQL query. Do not wrap in any markdown tags.",
},
{
role: "user",
content: userQuery,
},
],
});
return result.choices[0].message.content ?? "";
},
{ name: "generate_sql" }
);
const myEvaluator = async (params: {
outputs: { sql: string };
referenceOutputs: { sql: string };
}) => {
const { outputs, referenceOutputs } = params;
const instructions = [
"Return 1 if the ACTUAL and EXPECTED answers are semantically equivalent, ",
"otherwise return 0. Return only 0 or 1 and nothing else.",
].join("\n");
const grade = await tracedClient.chat.completions.create({
model: "gpt-4o-mini",
messages: [
{
role: "system",
content: instructions,
},
{
role: "user",
content: `ACTUAL: ${outputs.sql}\nEXPECTED: ${referenceOutputs?.sql}`,
},
],
});
const score = parseInt(grade.choices[0].message.content ?? "");
return { key: "correctness", score };
};
ls.describe("generate sql demo", () => {
ls.test(
"generates select all",
{
inputs: { userQuery: "Get all users from the customers table" },
referenceOutputs: { sql: "SELECT * FROM customers;" },
},
async ({ inputs, referenceOutputs }) => {
const sql = await generateSql(inputs.userQuery);
ls.logOutputs({ sql });
const wrappedEvaluator = ls.wrapEvaluator(myEvaluator);
// Will automatically log "correctness" as feedback
await wrappedEvaluator({
outputs: { sql },
referenceOutputs,
});
// You can also manually log feedback with `ls.logFeedback()`
ls.logFeedback({
key: "harmfulness",
score: 0.2,
});
}
);
ls.test(
"offtopic input",
{
inputs: { userQuery: "whats up" },
referenceOutputs: { sql: "sorry that is not a valid query" },
},
async ({ inputs, referenceOutputs }) => {
const sql = await generateSql(inputs.userQuery);
ls.logOutputs({ sql });
const wrappedEvaluator = ls.wrapEvaluator(myEvaluator);
// Will automatically log "correctness" as feedback
await wrappedEvaluator({
outputs: { sql },
referenceOutputs,
});
// You can also manually log feedback with `ls.logFeedback()`
ls.logFeedback({
key: "harmfulness",
score: 0.2,
});
}
);
});
myEvaluator 함수를 감싸는 ls.wrapEvaluator()의 사용에 주목하세요. 이렇게 하면 LLM-as-judge 호출이 나머지 테스트 케이스와 별도로 추적되어 혼란을 피할 수 있으며, 래핑된 함수의 반환 값이 { key: string; score: number | boolean }과 일치하면 편리하게 피드백을 생성합니다. 이 경우 메인 테스트 케이스 실행에 표시되는 대신 평가자 추적이 correctness 피드백 키와 연결된 추적에 표시됩니다.
UI에서 해당 피드백 칩을 클릭하여 LangSmith에서 평가자 실행을 볼 수 있습니다.
테스트 케이스에 대해 여러 예제 실행
ls.test.each()를 사용하여 동일한 테스트 케이스를 여러 예제에 대해 실행하고 테스트를 매개변수화할 수 있습니다. 이는 다른 입력에 대해 앱을 동일한 방식으로 평가하려는 경우에 유용합니다:
import * as ls from "langsmith/vitest";
// import * as ls from "langsmith/jest";
const DATASET = [
{
inputs: { userQuery: "whats up" },
referenceOutputs: { sql: "sorry that is not a valid query" }
},
{
inputs: { userQuery: "what color is the sky?" },
referenceOutputs: { sql: "sorry that is not a valid query" }
},
{
inputs: { userQuery: "how are you today?" },
referenceOutputs: { sql: "sorry that is not a valid query" }
}
];
ls.describe("generate sql demo", () => {
ls.test.each(DATASET)(
"offtopic inputs",
async ({ inputs, referenceOutputs }) => {
...
},
);
});
출력 로깅
테스트를 실행할 때마다 데이터셋 예제와 동기화하고 실행으로 추적합니다. 실행의 최종 출력을 추적하려면 다음과 같이 ls.logOutputs()를 사용할 수 있습니다:
import * as ls from "langsmith/vitest";
// import * as ls from "langsmith/jest";
ls.describe("generate sql demo", () => {
ls.test(
"offtopic input",
{
inputs: { userQuery: "..." },
referenceOutputs: { sql: "..." }
},
async ({ inputs, referenceOutputs }) => {
ls.logOutputs({ sql: "SELECT * FROM users;" })
},
);
});
import * as ls from "langsmith/vitest";
// import * as ls from "langsmith/jest";
ls.describe("generate sql demo", () => {
ls.test(
"offtopic input",
{
inputs: { userQuery: "..." },
referenceOutputs: { sql: "..." }
},
async ({ inputs, referenceOutputs }) => {
return { sql: "SELECT * FROM users;" }
},
);
});
중간 호출 추적
LangSmith는 테스트 케이스 실행 과정에서 발생하는 추적 가능한 중간 호출을 자동으로 추적합니다.
테스트 포커싱 또는 건너뛰기
ls.test() 및 ls.describe()에 Vitest/Jest .skip 및 .only 메서드를 체이닝할 수 있습니다:
import * as ls from "langsmith/vitest";
// import * as ls from "langsmith/jest";
ls.describe("generate sql demo", () => {
ls.test.skip(
"offtopic input",
{
inputs: { userQuery: "..." },
referenceOutputs: { sql: "..." }
},
async ({ inputs, referenceOutputs }) => {
return { sql: "SELECT * FROM users;" }
},
);
ls.test.only(
"other",
{
inputs: { userQuery: "..." },
referenceOutputs: { sql: "..." }
},
async ({ inputs, referenceOutputs }) => {
return { sql: "SELECT * FROM users;" }
},
);
});
테스트 스위트 구성
전체 스위트에 대해 ls.describe()에 추가 인수를 전달하거나 개별 테스트에 대해 ls.test()에 config 필드를 전달하여 메타데이터 또는 사용자 정의 클라이언트와 같은 값으로 테스트 스위트를 구성할 수 있습니다:
ls.describe("test suite name", () => {
ls.test(
"test name",
{
inputs: { ... },
referenceOutputs: { ... },
// Extra config for the test run
config: { tags: [...], metadata: { ... } }
},
{
name: "test name",
tags: ["tag1", "tag2"],
skip: true,
only: true,
}
);
}, {
testSuiteName: "overridden value",
metadata: { ... },
// Custom client
client: new Client(),
});
process.env.ENVIRONMENT, process.env.NODE_ENV 및 process.env.LANGSMITH_ENVIRONMENT에서 환경 변수를 자동으로 추출하고 생성된 실험에 메타데이터로 설정합니다. 그런 다음 LangSmith의 UI에서 메타데이터로 실험을 필터링할 수 있습니다.
전체 구성 옵션 목록은 API 참조를 참조하세요.
Dry-run 모드
결과를 LangSmith와 동기화하지 않고 테스트를 실행하려면 LangSmith 추적 환경 변수를 생략하거나 환경에서 LANGSMITH_TEST_TRACKING=false를 설정할 수 있습니다.
테스트는 정상적으로 실행되지만 실험 로그는 LangSmith로 전송되지 않습니다.

