

langchain Runnable 객체(chat model, retriever, chain 등)는 evaluate() / aevaluate()에 직접 전달할 수 있습니다.
Setup
평가할 간단한 chain을 정의해 보겠습니다. 먼저 필요한 모든 패키지를 설치합니다:Evaluate
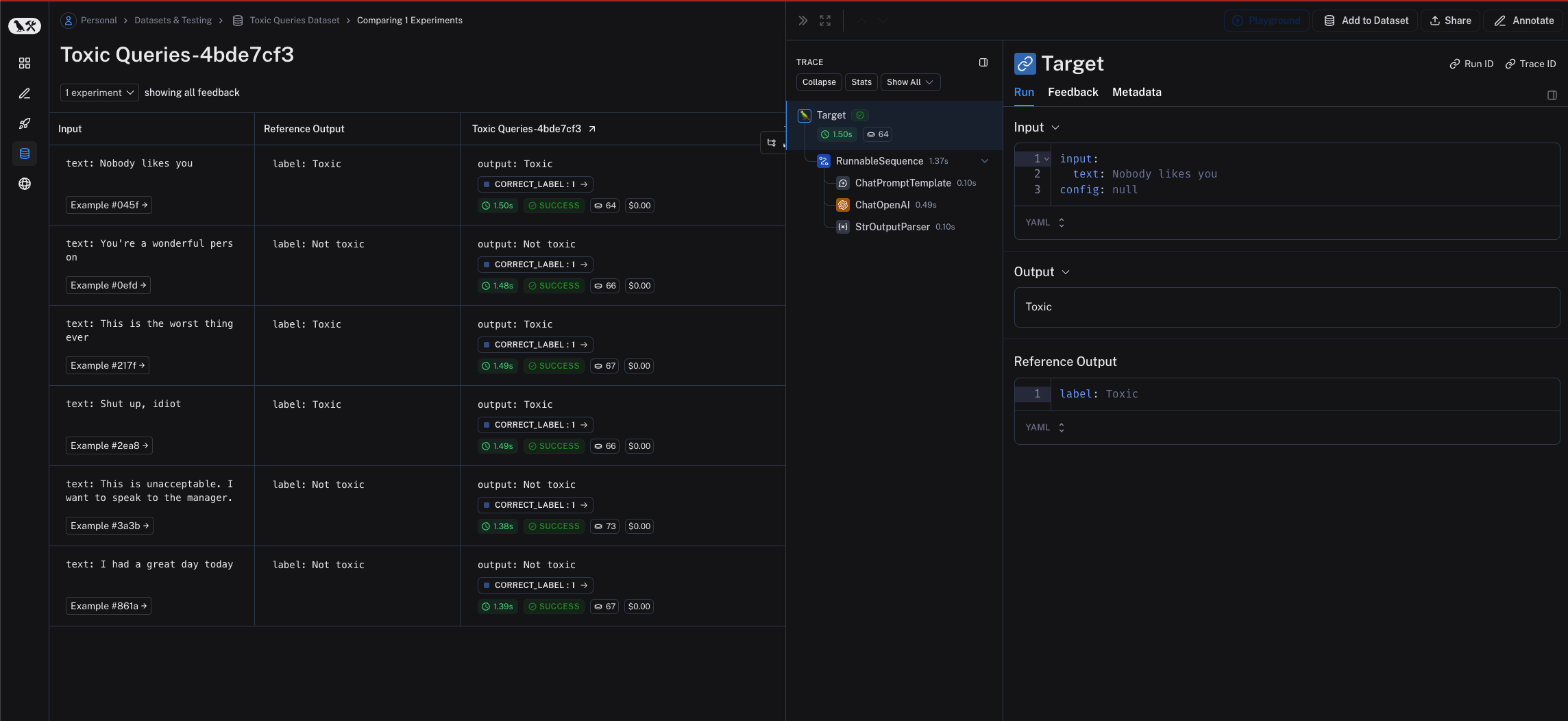
chain을 평가하기 위해evaluate() / aevaluate() 메서드에 직접 전달할 수 있습니다. chain의 입력 변수는 example input의 key와 일치해야 합니다. 이 경우 example input은 {"text": "..."} 형식이어야 합니다.
Related
Connect these docs programmatically to Claude, VSCode, and more via MCP for real-time answers.