

- retrieval 단계를 평가하여 입력 쿼리와 관련하여 올바른 문서가 검색되는지 확인합니다.
- generation 단계를 평가하여 검색된 문서와 관련하여 올바른 답변이 생성되는지 확인합니다.
Run 객체인 run/rootRun 인수를 탐색하고 처리해야 합니다.
1. LLM 파이프라인 정의하기
아래 RAG 파이프라인은 1) 입력 질문에 대한 Wikipedia 쿼리 생성, 2) Wikipedia에서 관련 문서 검색, 3) 검색된 문서를 기반으로 답변 생성으로 구성됩니다.langsmith>=0.3.13 필요
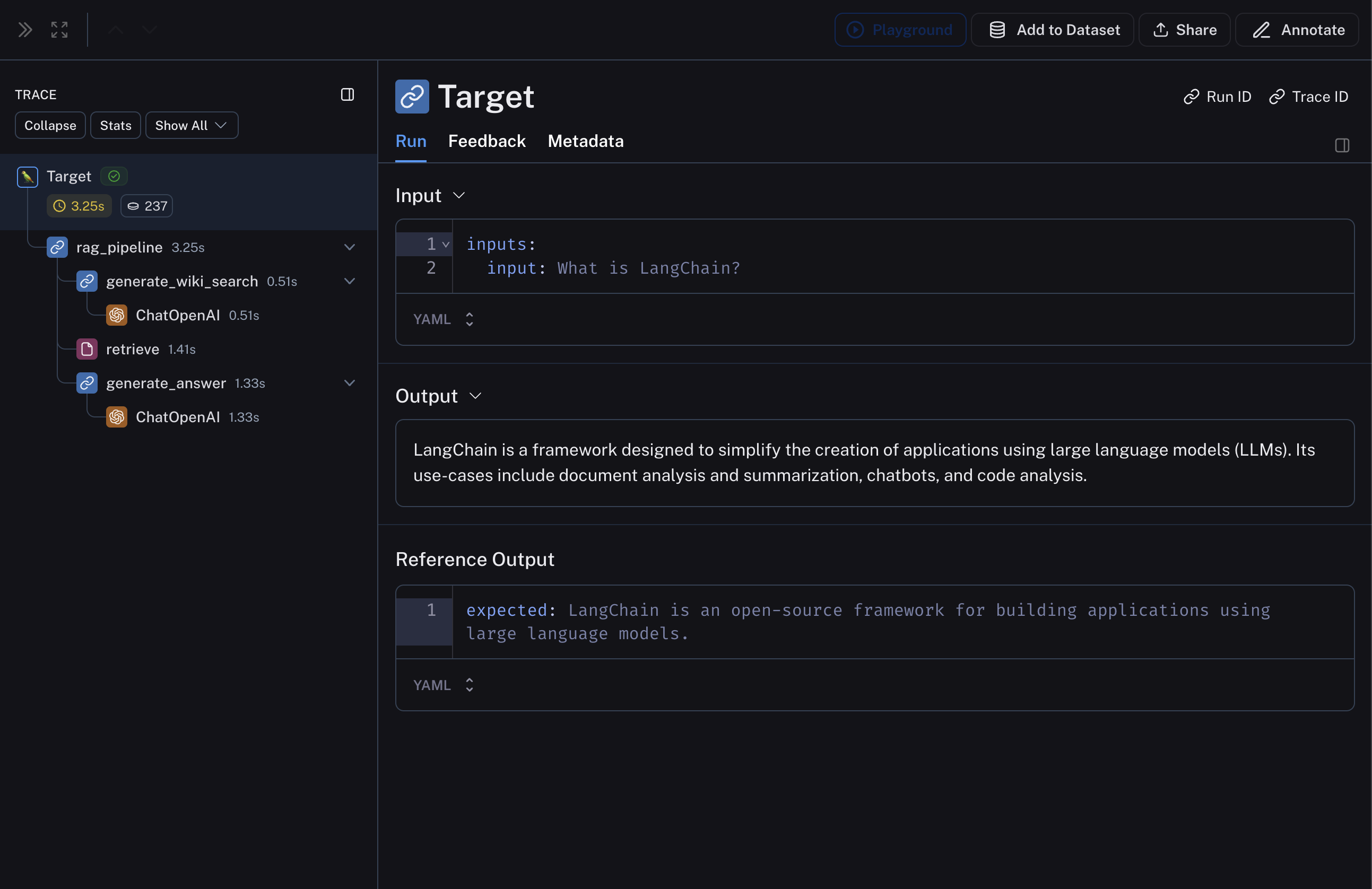
2. 파이프라인을 평가할 dataset과 example 생성하기
파이프라인을 평가하기 위해 몇 가지 example이 포함된 매우 간단한 dataset을 구축합니다.langsmith>=0.3.13 필요
3. 커스텀 evaluator 정의하기
위에서 언급한 것처럼, 두 개의 evaluator를 정의합니다: 하나는 입력 쿼리와 관련하여 검색된 문서의 관련성을 평가하고, 다른 하나는 검색된 문서와 관련하여 생성된 답변의 hallucination을 평가합니다. hallucination을 위한 evaluator를 정의하기 위해with_structured_output과 함께 LangChain LLM wrapper를 사용합니다.
여기서 핵심은 evaluator 함수가 파이프라인의 중간 단계에 접근하기 위해 run / rootRun 인수를 탐색해야 한다는 것입니다. 그런 다음 evaluator는 중간 단계의 입력과 출력을 처리하여 원하는 기준에 따라 평가할 수 있습니다.
편의를 위해 langchain을 사용하는 예제이며, 필수는 아닙니다.
4. 파이프라인 평가하기
마지막으로, 위에서 정의한 커스텀 evaluator를 사용하여evaluate를 실행합니다.

관련 항목
Connect these docs programmatically to Claude, VSCode, and more via MCP for real-time answers.