

- 성능을 측정할 초기 골든 데이터셋 생성
- 성능 측정에 사용할 메트릭 정의
- 여러 프롬프트 또는 모델에서 평가 실행
- 결과를 수동으로 비교
- 시간에 따라 결과 추적
- CI/CD에서 자동화된 테스트 설정
설정
먼저 이 튜토리얼에 필요한 의존성을 설치합니다. 여기서는 OpenAI를 사용하지만, LangSmith는 어떤 모델과도 사용할 수 있습니다:데이터셋 생성
애플리케이션을 테스트하고 평가할 준비를 할 때 첫 번째 단계는 평가할 데이터 포인트를 정의하는 것입니다. 여기서 고려해야 할 몇 가지 측면이 있습니다:- 각 데이터 포인트의 스키마는 어떻게 되어야 할까?
- 얼마나 많은 데이터 포인트를 수집해야 할까?
- 데이터 포인트를 어떻게 수집해야 할까?
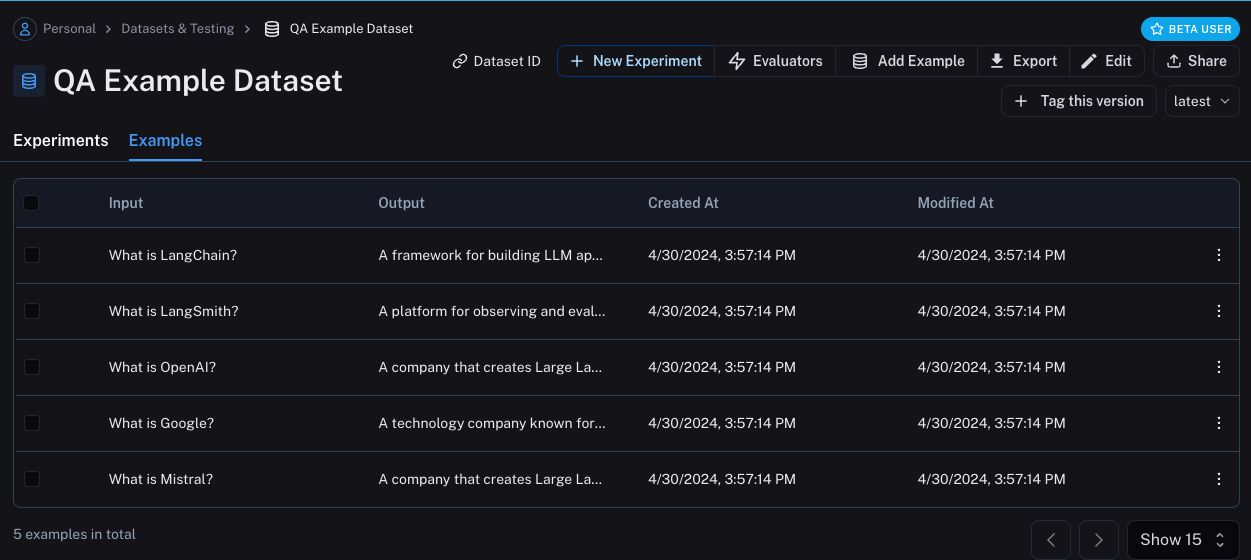
Datasets & Testing 페이지의 QA Example Dataset을 찾아 클릭하면, 5개의 새로운 예시가 추가된 것을 확인할 수 있습니다.
메트릭 정의
데이터셋을 만든 후에는 응답을 평가할 메트릭을 정의할 수 있습니다. 기대하는 답변이 있으므로, 평가 시 이를 기준으로 비교할 수 있습니다. 하지만 애플리케이션이 정확히 그 답변을 출력하리라 기대하지는 않고, 비슷한 답변을 출력하길 기대합니다. 이로 인해 평가가 조금 더 까다로워집니다. 정확성 평가 외에도, 답변이 짧고 간결한지 확인해봅시다. 이 부분은 더 쉽습니다. 응답의 길이를 측정하는 간단한 Python 함수를 정의할 수 있습니다. 이 두 가지 메트릭을 정의해봅시다. 첫 번째로, LLM을 사용하여 출력이 기대하는 출력과 맞는지 판단하도록 합니다. 이런 LLM-as-a-judge 방식은 단순 함수로 측정하기 어려운 복잡한 경우에 흔히 사용됩니다. 평가에 사용할 프롬프트와 LLM을 직접 정의할 수 있습니다:평가 실행
좋습니다! 이제 평가를 어떻게 실행할까요? 데이터셋과 평가자(evaluator)가 준비되었으니, 이제 필요한 것은 애플리케이션입니다! 시스템 메시지에 응답 방법에 대한 지침을 넣고, 이를 LLM에 전달하는 간단한 애플리케이션을 만들어봅니다. OpenAI SDK를 직접 사용하여 구현합니다: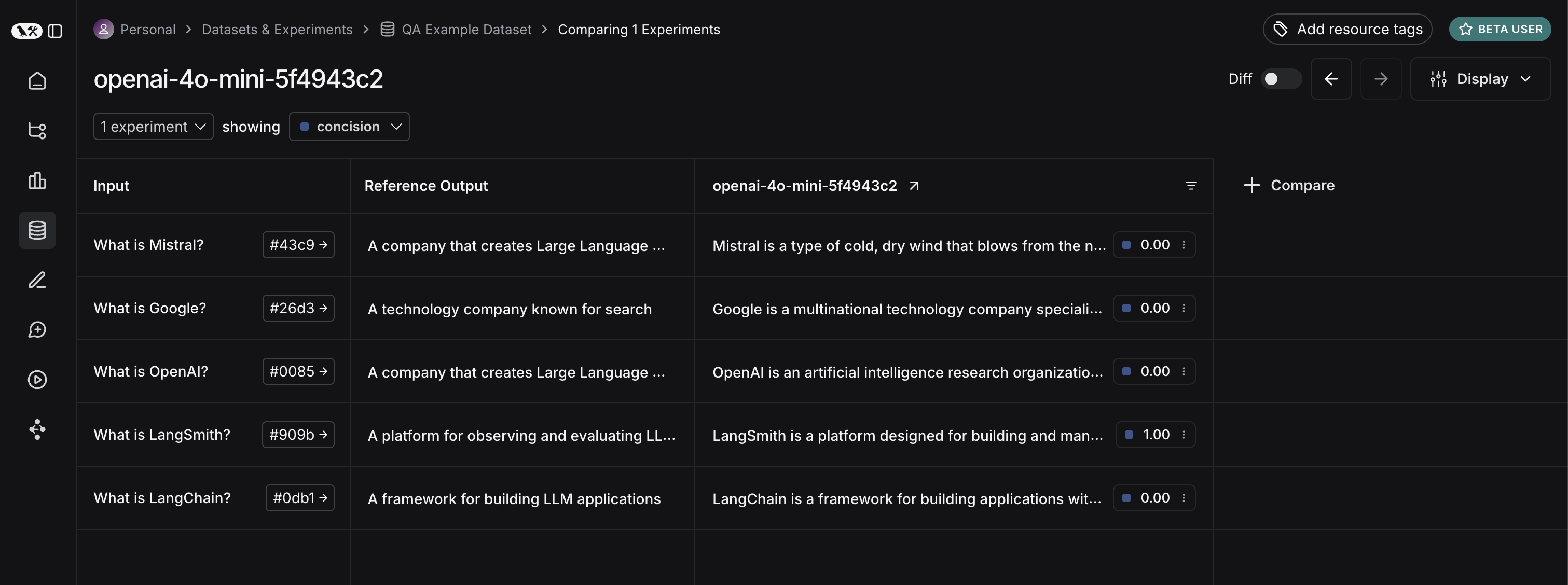 데이터셋 페이지로 돌아가서
데이터셋 페이지로 돌아가서 Experiments 탭을 선택하면, 한 번의 실행 요약을 볼 수 있습니다!
 이번에는 다른 모델로 시도해봅시다!
이번에는 다른 모델로 시도해봅시다! gpt-4-turbo를 사용해봅시다.
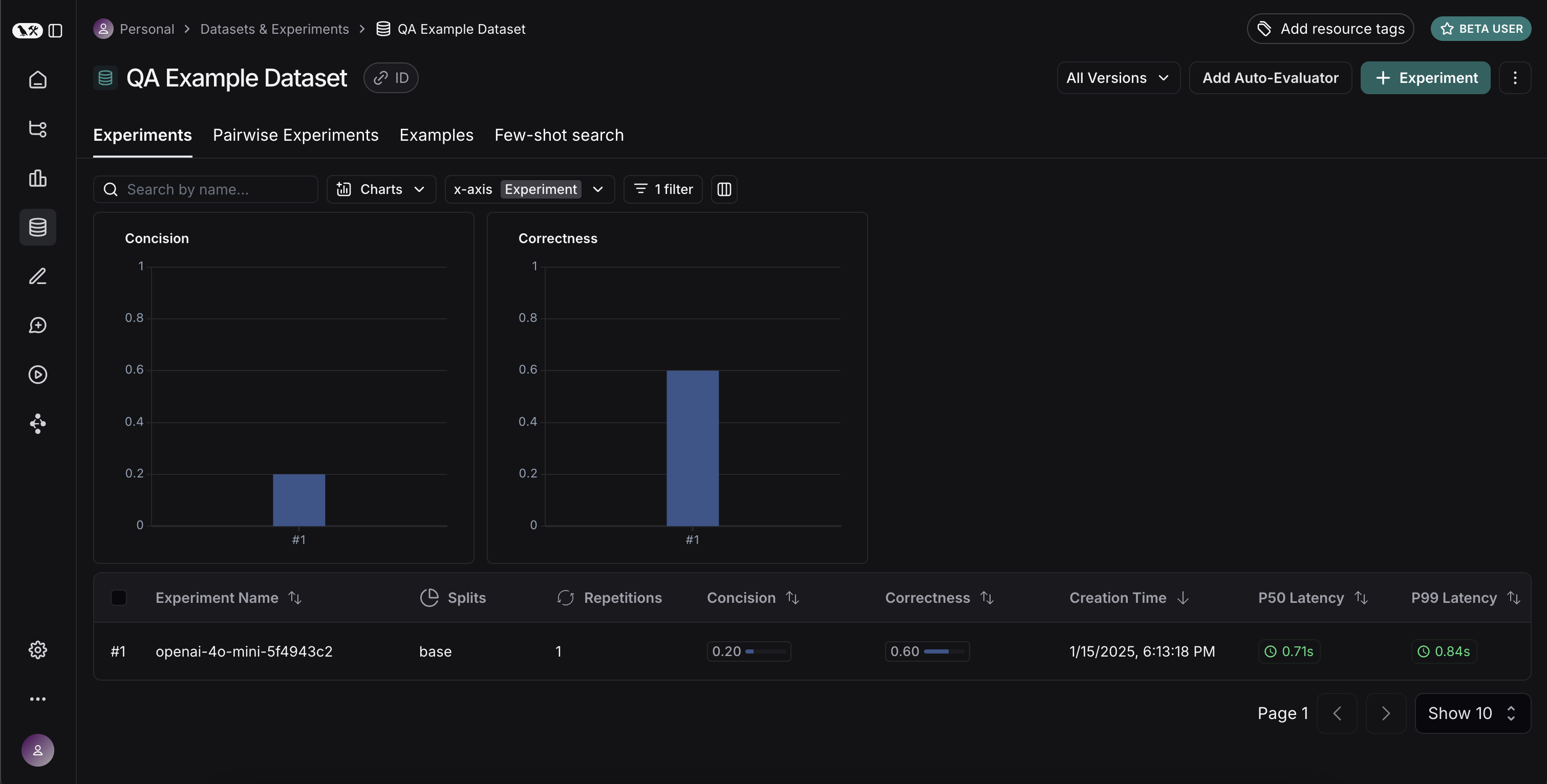
Experiments 탭으로 돌아가면, 세 번의 실행 결과가 모두 표시되는 것을 볼 수 있습니다!
결과 비교
좋습니다, 세 번의 실행을 평가했습니다. 그런데 결과를 어떻게 비교할 수 있을까요? 첫 번째 방법은Experiments 탭에서 실행을 직접 확인하는 것입니다. 여기서 각 실행에 대한 메트릭을 한눈에 볼 수 있습니다:
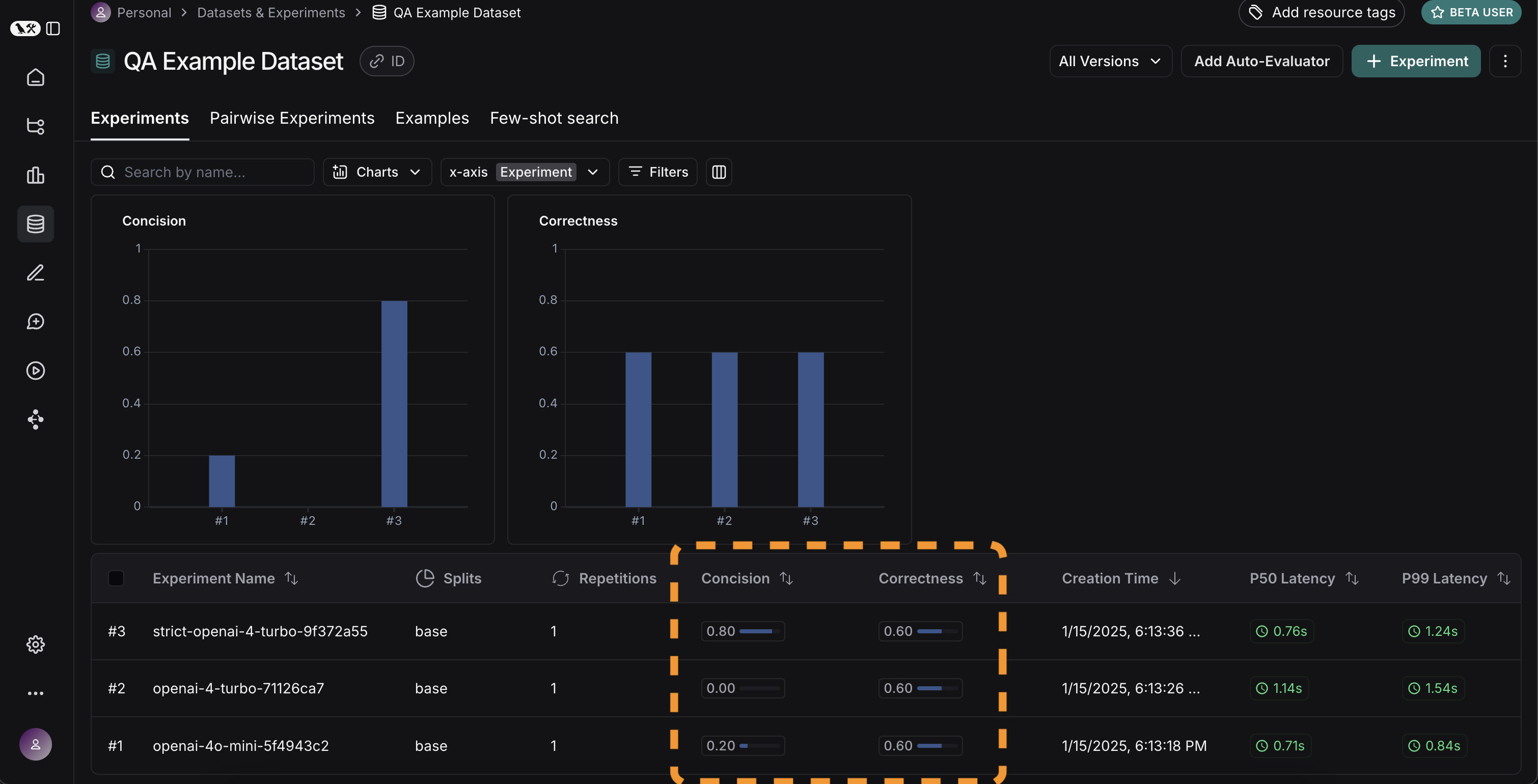 좋습니다! GPT-4가 GPT-3.5보다 기업 정보를 더 잘 알고 있고, 엄격한 프롬프트가 답변 길이에 큰 도움이 된 것을 알 수 있습니다. 더 자세히 살펴보고 싶다면 어떻게 해야 할까요?
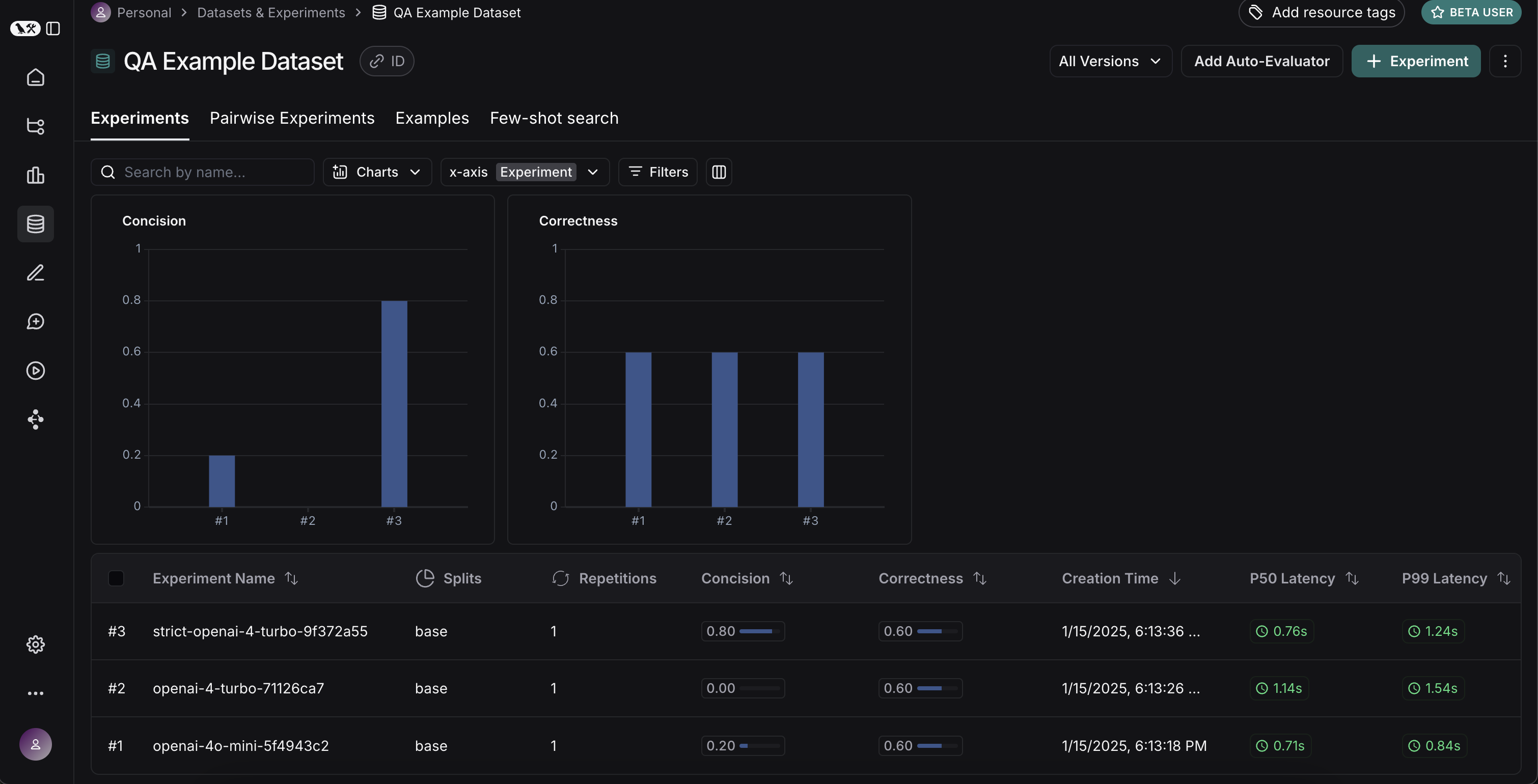
비교하고 싶은 실행(여기서는 세 개 모두)을 선택하고, 비교 뷰에서 열어볼 수 있습니다. 세 가지 테스트가 나란히 표시됩니다. 일부 셀은 색상으로 구분되어 있는데, 이는 특정 메트릭이 특정 기준과 비교해 어떻게 변화했는지 보여줍니다. 기준과 메트릭은 기본값으로 자동 선택되지만, 직접 변경할 수도 있습니다.
좋습니다! GPT-4가 GPT-3.5보다 기업 정보를 더 잘 알고 있고, 엄격한 프롬프트가 답변 길이에 큰 도움이 된 것을 알 수 있습니다. 더 자세히 살펴보고 싶다면 어떻게 해야 할까요?
비교하고 싶은 실행(여기서는 세 개 모두)을 선택하고, 비교 뷰에서 열어볼 수 있습니다. 세 가지 테스트가 나란히 표시됩니다. 일부 셀은 색상으로 구분되어 있는데, 이는 특정 메트릭이 특정 기준과 비교해 어떻게 변화했는지 보여줍니다. 기준과 메트릭은 기본값으로 자동 선택되지만, 직접 변경할 수도 있습니다. Display 컨트롤을 사용해 표시할 열과 메트릭을 선택할 수 있습니다. 상단 아이콘을 클릭하면 개선/퇴보가 있는 실행만 자동으로 필터링할 수도 있습니다.
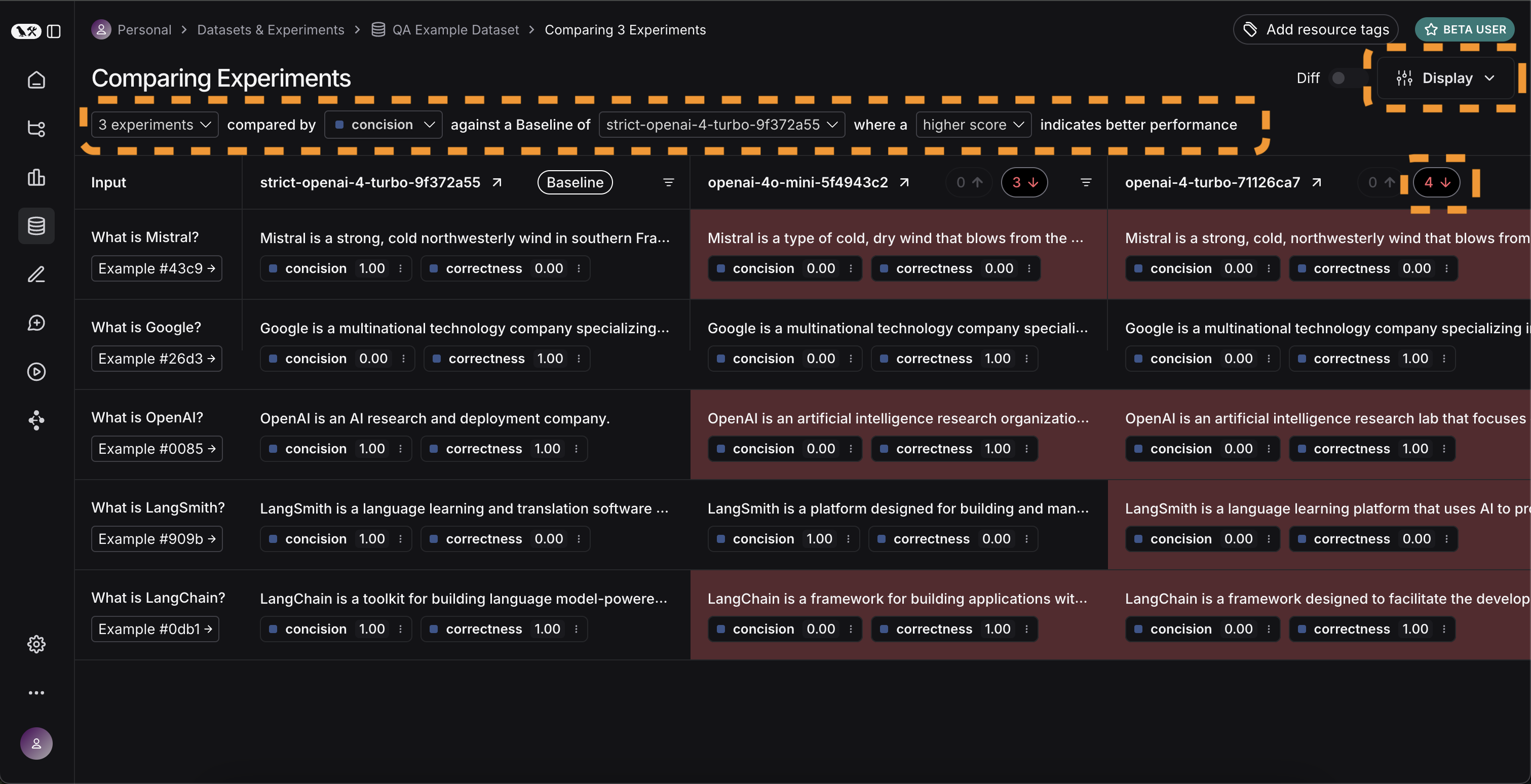 더 많은 정보를 보고 싶다면, 행 위에 마우스를 올리면 나타나는
더 많은 정보를 보고 싶다면, 행 위에 마우스를 올리면 나타나는 Expand 버튼을 클릭해 사이드 패널에서 상세 정보를 확인할 수 있습니다:
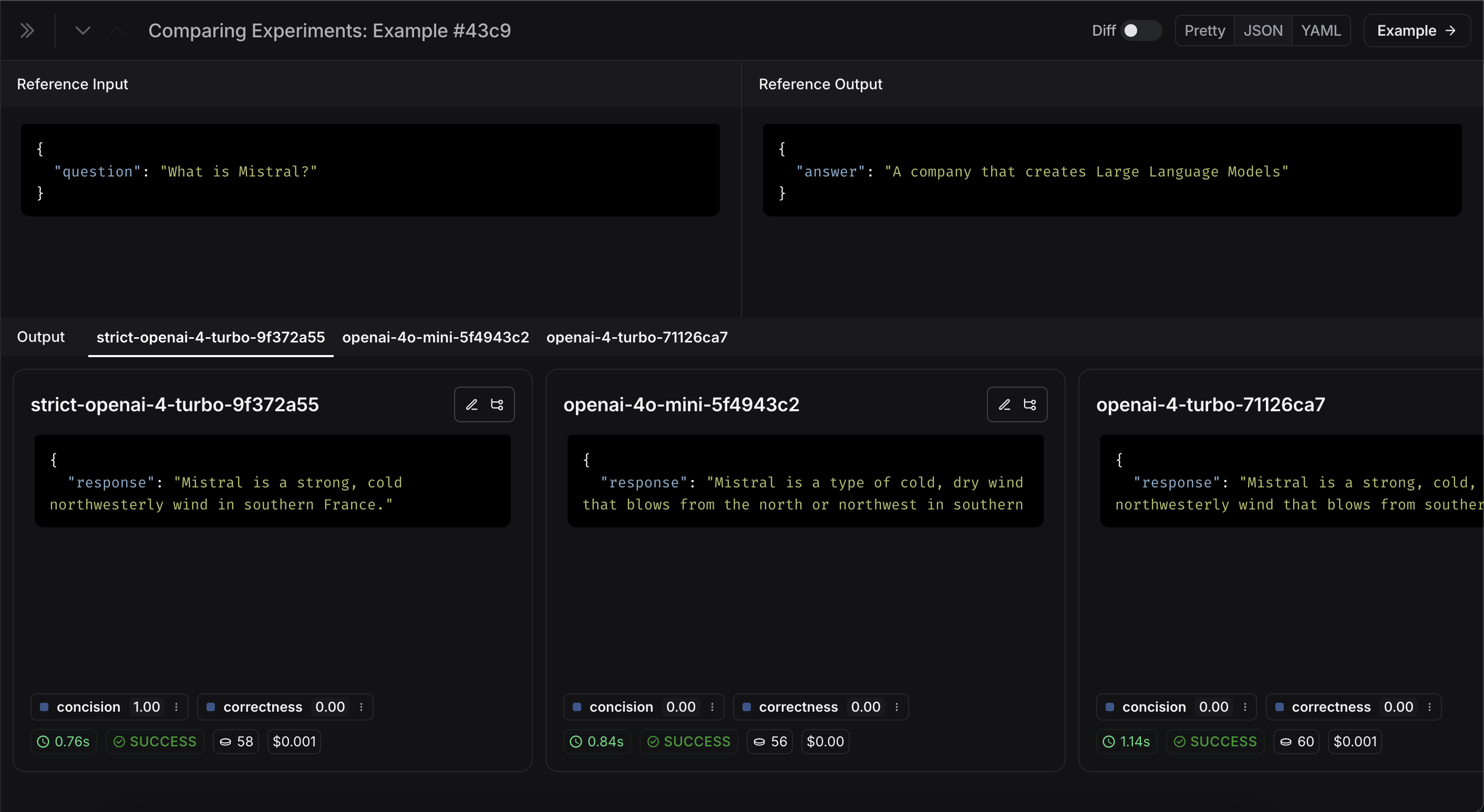
CI/CD에서 자동화된 테스트 설정
이제 일회성으로 실행해봤으니, 자동화 방식으로 실행하도록 설정할 수 있습니다. pytest 파일로 만들어 CI/CD에서 실행하면 매우 쉽게 자동화할 수 있습니다. 이 과정에서 결과만 기록하거나, 통과 여부를 판단하는 기준을 설정할 수도 있습니다. 예를 들어, 생성된 응답 중 최소 80%가length 체크를 통과해야 한다는 기준을 설정하려면 다음과 같이 테스트할 수 있습니다:
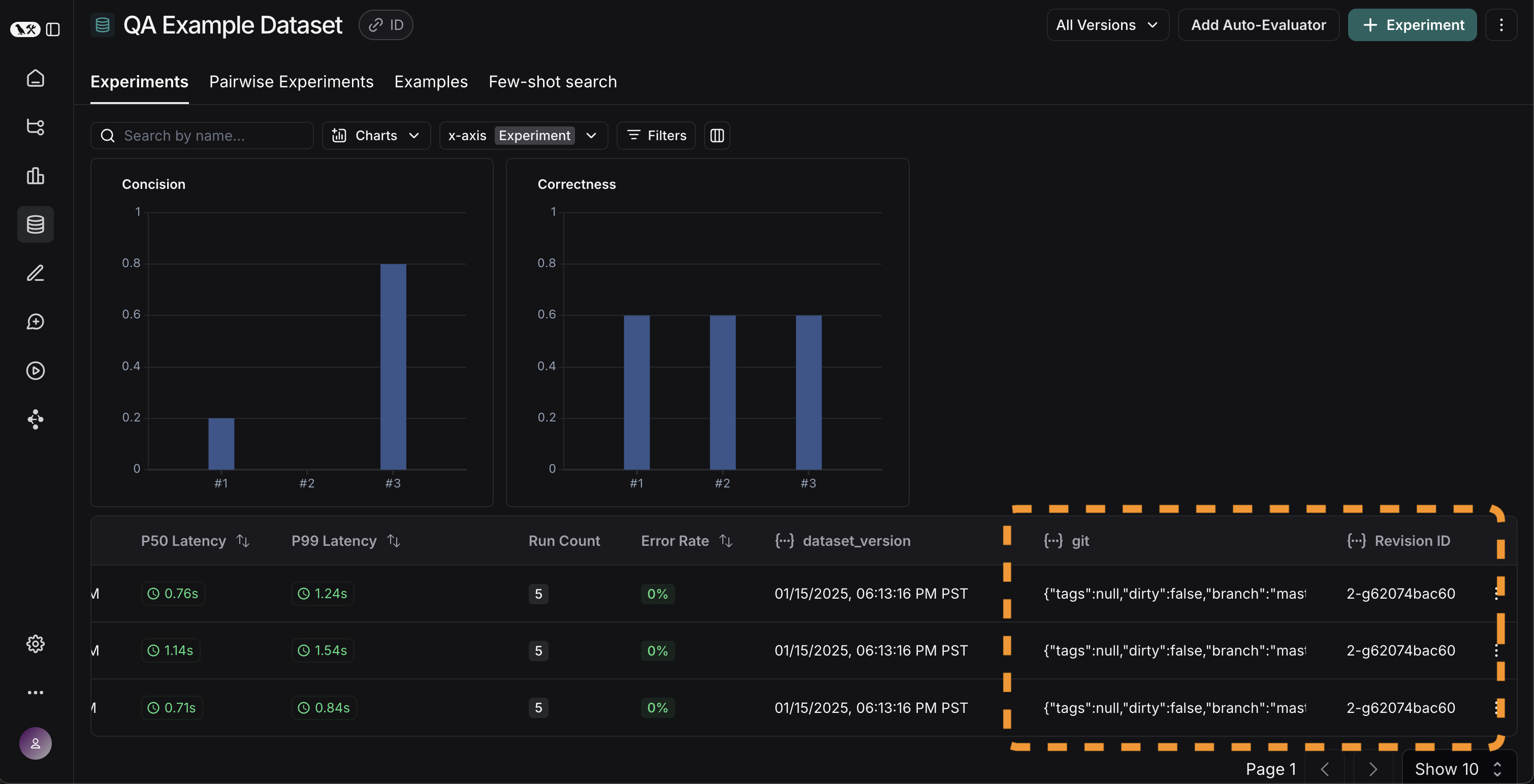
시간에 따라 결과 추적
이제 실험을 자동화 방식으로 실행하게 되었으니, 시간에 따라 결과를 추적하고 싶을 것입니다. 데이터셋 페이지의 전체Experiments 탭에서 이를 확인할 수 있습니다. 기본적으로 시간에 따른 평가 메트릭(빨간색 강조)을 표시합니다. 또한 git 메트릭도 자동으로 추적하여 코드의 브랜치와 쉽게 연관시킬 수 있습니다(노란색 강조).
결론
이 튜토리얼은 여기까지입니다! 초기 테스트 세트 생성, 평가 메트릭 정의, 실험 실행, 수동 비교, CI/CD 설정, 시간에 따른 결과 추적까지 살펴보았습니다. 이 과정이 자신 있게 반복 개발하는 데 도움이 되길 바랍니다. 이것은 시작에 불과합니다. 앞서 언급했듯, 평가는 지속적인 과정입니다. 예를 들어, 평가하고 싶은 데이터 포인트는 시간이 지나면서 계속 바뀔 수 있습니다. 다양한 평가자(evaluator)도 탐색해볼 수 있습니다. 이에 대한 정보는 how-to guides를 참고하세요. 또한, 이와 같은 “오프라인” 방식 외에도 데이터를 평가하는 다른 방법이 있습니다(예: 운영 데이터 평가). 온라인 평가에 대한 자세한 내용은 이 가이드를 참고하세요.참고 코드
통합 코드 스니펫 보기
통합 코드 스니펫 보기
Connect these docs programmatically to Claude, VSCode, and more via MCP for real-time answers.