

온라인 평가는 프로덕션 트레이스에 대한 실시간 피드백을 제공합니다. 이는 애플리케이션의 성능을 지속적으로 모니터링하고, 문제를 식별하며, 개선 사항을 측정하고, 시간이 지나도 일관된 품질을 보장하는 데 유용합니다.
LangSmith에서는 두 가지 유형의 온라인 평가를 지원합니다:
- LLM-as-a-judge: LLM을 사용하여 트레이스를 평가하며, 인간과 유사한 판단(예: 독성, 환각, 정확성)에 대한 확장 가능한 대체 수단으로 활용합니다. 두 가지 수준의 세분화가 지원됩니다:
- Run level: 단일 실행을 평가합니다.
- Thread level: 스레드 내 모든 트레이스를 평가합니다.
- Custom Code: LangSmith 내에서 Python으로 직접 평가자를 작성합니다. 주로 데이터의 구조나 통계적 특성을 검증할 때 사용됩니다.
온라인 평가자가 트레이스 내의 어떤 실행(run)에서 실행되면, 해당 트레이스는 자동으로 확장된 데이터 보존으로 업그레이드됩니다. 이 업그레이드는 트레이스 가격에 영향을 미치지만, 평가 기준을 충족하는 트레이스(분석에 가장 가치 있는 경우)가 조사 목적으로 보존되도록 보장합니다.
온라인 평가자 보기
Tracing Projects 탭으로 이동하여 트레이싱 프로젝트를 선택하세요. 해당 프로젝트의 기존 온라인 평가자를 보려면 Evaluators 탭을 클릭하세요.
온라인 평가자 구성하기
1. 온라인 평가자 페이지로 이동
Tracing Projects 탭으로 이동하여 트레이싱 프로젝트를 선택하세요. 트레이싱 프로젝트 페이지 오른쪽 상단에서 + New를 클릭한 후, New Evaluator를 클릭하세요. 구성하려는 평가자를 선택합니다.2. 평가자 이름 지정
3. 필터 생성
예를 들어, 다음과 같은 기준에 따라 특정 평가자를 적용할 수 있습니다:- 사용자가 피드백을 남긴 실행(run) 중 응답이 만족스럽지 않다고 표시된 경우
- 특정 툴 호출이 발생한 실행(run). 자세한 내용은 툴 호출 필터링 참고
- 특정 메타데이터와 일치하는 실행(run)(예:
plan_type으로 트레이스를 기록하고, 엔터프라이즈 고객의 트레이스에만 평가를 적용하고 싶은 경우). 자세한 내용은 트레이스에 메타데이터 추가하기 참고
평가자에 대한 필터를 생성할 때 실행(run)을 직접 확인하는 것이 도움이 됩니다. 평가자 구성 패널을 열어두면 실행(run)을 검사하고 필터를 적용할 수 있습니다. 실행 테이블에 적용한 필터는 평가자 필터에도 자동으로 반영됩니다.
4. (선택 사항) 샘플링 비율 설정
샘플링 비율을 설정하여 필터링된 실행(run) 중 자동화 작업을 트리거할 비율을 제어할 수 있습니다. 예를 들어, 비용을 관리하기 위해 평가자를 전체 트레이스의 10%에만 적용하도록 필터를 설정할 수 있습니다. 이를 위해 샘플링 비율을 0.1로 설정하면 됩니다.5. (선택 사항) 과거 실행에 규칙 적용
Apply to past runs를 토글하고 “Backfill from” 날짜를 입력하여 과거 실행(run)에 규칙을 적용할 수 있습니다. 이 작업은 규칙 생성 시에만 가능합니다. 참고: 백필(backfill)은 백그라운드 작업으로 처리되므로 결과가 즉시 표시되지 않습니다. 백필 진행 상황을 추적하려면, 트레이싱 프로젝트 내 Evaluators 탭에서 생성한 평가자의 Logs 버튼을 클릭하여 평가자 로그를 확인할 수 있습니다. 온라인 평가자 로그는 자동화 규칙 로그와 유사합니다.- 평가자 이름 추가
- 평가자를 적용할 실행(run)을 필터링하거나 샘플링 비율을 설정(선택 사항)
- Apply Evaluator 선택
6. 평가자 유형 선택
LLM-as-a-judge 온라인 평가자 구성하기
LLM-as-a-judge 평가자 구성 가이드를 참고하세요.Custom code 평가자 구성하기
custom code 평가자를 선택하세요.평가 함수 작성하기
Custom code 평가자 제한 사항허용 라이브러리: 모든 표준 라이브러리 함수와 다음 공개 패키지를 import할 수 있습니다:네트워크 접근: custom code 평가자에서는 인터넷에 접근할 수 없습니다.
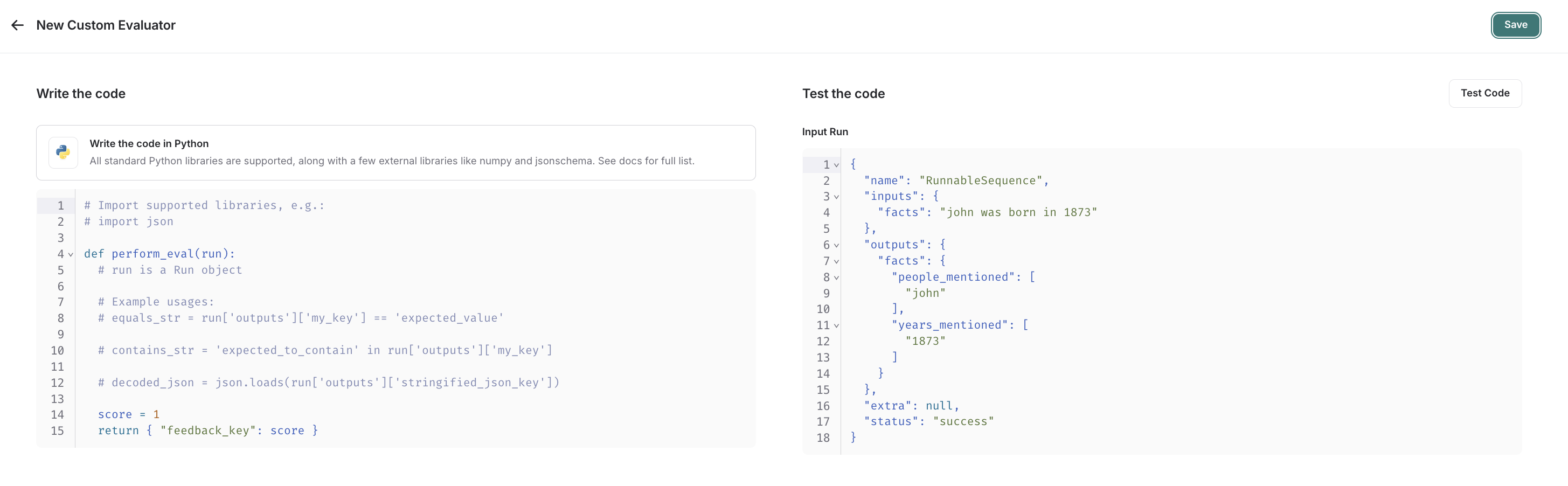 Custom code 평가자는 하나의 인자를 받습니다:
Custom code 평가자는 하나의 인자를 받습니다:
Run(참고): 평가할 샘플 실행(run)을 나타냅니다.
- Feedback(s) Dictionary: 반환하고자 하는 피드백 유형이 key, 해당 피드백 key에 대해 부여할 점수가 value인 딕셔너리입니다. 예를 들어,
{"correctness": 1, "silliness": 0}은 실행(run)에 두 가지 피드백을 생성하며, 하나는 올바름을, 다른 하나는 어리석지 않음을 나타냅니다.
평가 함수 테스트 및 저장
저장하기 전에, 최근 실행(run)에 평가자 함수를 테스트하려면 Test Code를 클릭하여 코드가 정상적으로 실행되는지 확인할 수 있습니다. Save를 클릭하면, 온라인 평가자가 새로 샘플링된 실행(run)(또는 백필 옵션을 선택했다면 과거 실행에도)에서 실행됩니다. 동영상 튜토리얼을 선호한다면, LangSmith 과정의 온라인 평가 동영상을 참고하세요.동영상 가이드
멀티턴 온라인 평가자 구성하기
멀티턴 온라인 평가자를 사용하면 인간과 에이전트 간의 전체 대화를 평가할 수 있습니다—개별 교환만 평가하는 것이 아닙니다. 모든 턴에 걸친 상호작용 품질을 종합적으로 측정합니다. 멀티턴 평가를 통해 다음을 측정할 수 있습니다:- Semantic Intent: 사용자가 무엇을 하려고 했는지
- Semantic Outcome: 실제로 어떤 일이 발생했는지, 과제가 성공했는지
- Trajectory: 대화가 어떻게 전개되었는지, 툴 호출의 흐름 포함
멀티턴 온라인 평가를 실행하면 스레드 내의 각 트레이스가 자동으로 확장된 데이터 보존으로 업그레이드됩니다. 이 업그레이드는 트레이스 가격에 영향을 미치지만, 평가 기준을 충족하는 트레이스(분석에 가장 가치 있는 경우)가 조사 목적으로 보존되도록 보장합니다.
사전 조건
- 트레이싱 프로젝트가 threads를 사용해야 합니다.
- 스레드 내 각 트레이스의 최상위 입력 및 출력에
messages키가 있어야 하며, 메시지 리스트를 포함해야 합니다. LangChain, OpenAI Chat Completions, Anthropic Messages 형식을 지원합니다.- 각 트레이스의 최상위 입력 및 출력에 대화의 최신 메시지만 포함되어 있다면, LangSmith가 자동으로 여러 턴의 메시지를 스레드로 결합합니다.
- 각 트레이스의 최상위 입력 및 출력에 전체 대화 기록이 포함되어 있다면, LangSmith가 해당 내용을 직접 사용합니다.
트레이스가 위의 형식을 따르지 않으면, thread level 평가자가 작동하지 않습니다. 각 트레이스의 최상위 입력 및 출력에
messages 리스트가 포함되도록 LangSmith로 트레이스를 업데이트해야 합니다.자세한 내용은 문제 해결 섹션을 참고하세요.구성 방법
- Tracing Projects 탭으로 이동하여 트레이싱 프로젝트를 선택하세요.
- 트레이싱 프로젝트 페이지 오른쪽 상단에서 + New > New Evaluator > Evaluate a multi-turn thread를 클릭하세요.
- 평가자 이름 지정
- 필터 또는 샘플링 비율 적용
필터 또는 샘플링을 사용하여 평가자 비용을 제어하세요. 예를 들어, N 턴 이하의 스레드만 평가하거나 전체 스레드의 10%만 샘플링할 수 있습니다. - 유휴 시간(Idle time) 구성
스레드 레벨 평가자를 처음 구성할 때, 유휴 시간—스레드의 마지막 트레이스 이후 평가 준비가 완료된 것으로 간주되는 시간—을 정의합니다. 이 값은 앱에서 예상되는 사용자 상호작용 길이를 반영해야 하며, 프로젝트 내 모든 평가자에 적용됩니다.
평가자를 처음 테스트할 때는 짧은 유휴 시간을 사용하여 빠르게 결과를 확인하세요. 검증 후에는 앱의 예상 사용자 상호작용 길이에 맞게 늘려주세요.
-
모델 구성
평가자에 사용할 공급자와 모델을 선택하세요. 스레드는 길어질 수 있으므로, 컨텍스트 윈도우가 큰 모델을 사용해야 제한에 걸리지 않습니다. 예를 들어, OpenAI의 GPT-4.1 mini 또는 Gemini 2.5 Flash는 모두 1M+ 토큰 컨텍스트 윈도우를 제공하므로 좋은 선택입니다. -
LLM-as-a-judge 프롬프트 구성
평가하고자 하는 내용을 정의하세요. 이 프롬프트는 스레드를 평가하는 데 사용됩니다. 또한 평가자에 전달되는messages리스트의 범위를 구성하여 전달되는 내용을 제어할 수 있습니다:- 모든 메시지: 전체 메시지 리스트를 전달
- Human과 AI 페어: 사용자와 어시스턴트 메시지만 전달(시스템 메시지, 툴 호출 등 제외)
- 첫 번째 Human과 마지막 AI: 첫 번째 사용자 메시지와 마지막 어시스턴트 답변만 전달
-
피드백 구성 설정
피드백 key의 이름, 수집할 피드백 형식, 선택적으로 피드백에 대한 reasoning 활성화를 구성하세요.
스레드 레벨 평가자와 실행(run) 레벨 평가자에 동일한 피드백 key를 사용하는 것은 구분이 어려우므로 권장하지 않습니다.
- 평가자 저장
제한 사항
멀티턴 온라인 평가자의 현재 제한 사항(변경될 수 있음)은 다음과 같습니다. 이 제한에 문제가 있다면 문의해 주세요.- 실행(run)은 1주일 이내여야 함: 스레드가 유휴 상태가 되면, 최근 7일 이내의 실행(run)만 평가 대상이 됩니다.
- 한 번에 최대 500개 스레드 평가: 5분 내 유휴 상태로 표시된 스레드가 500개를 초과하면, 500개를 초과하는 부분은 자동으로 샘플링됩니다.
- 워크스페이스당 최대 10개의 멀티턴 온라인 평가자
문제 해결
평가자 상태 확인트레이싱 프로젝트 내 Evaluators 탭에서 생성한 평가자의 Logs 버튼을 클릭하여 마지막 실행 시점을 확인할 수 있습니다. 평가자에 전달된 데이터 확인
트레이싱 프로젝트 내 Evaluators 탭에서 생성한 평가자를 클릭한 후 Evaluator traces 탭을 클릭하여 평가자에 전달된 데이터를 확인할 수 있습니다. 이 탭에서는 LLM-as-a-judge 평가자에 전달된 입력값을 볼 수 있습니다. 메시지가 올바르게 전달되지 않으면 입력값이 비어 있는 것을 볼 수 있습니다. 이는 메시지가 예상 형식 중 하나로 포맷되지 않은 경우 발생할 수 있습니다.
Connect these docs programmatically to Claude, VSCode, and more via MCP for real-time answers.