

프로토타이핑
처음부터 관찰 가능성을 설정하면 그렇지 않은 경우보다 훨씬 더 빠르게 반복할 수 있습니다. 이를 통해 프롬프트를 빠르게 반복하거나 사용하는 데이터와 모델을 변경할 때 애플리케이션에 대한 뛰어난 가시성을 확보할 수 있습니다. 이 섹션에서는 프로토타이핑하는 동안 최대한의 관찰 가능성을 확보할 수 있도록 관찰 가능성을 설정하는 방법을 안내합니다.환경 설정
먼저 설정 페이지로 이동하여 API 키를 생성합니다. 다음으로 LangSmith SDK를 설치합니다:default 프로젝트에 trace가 기록됩니다(쉽게 변경할 수 있습니다).
다른 곳에서 이러한 변수가
LANGCHAIN_*로 참조되는 것을 볼 수 있습니다. 이들은 모두 동일하지만, 모범 사례는 LANGSMITH_TRACING, LANGSMITH_API_KEY, LANGSMITH_PROJECT를 사용하는 것입니다.LANGSMITH_PROJECT 플래그는 JS SDK 버전 >= 0.2.16에서만 지원되며, 이전 버전을 사용하는 경우 LANGCHAIN_PROJECT를 대신 사용하세요.LLM 호출 추적
가장 먼저 추적하고 싶은 것은 모든 OpenAI 호출입니다. 결국 이것이 LLM이 실제로 호출되는 곳이므로 가장 중요한 부분입니다! LangSmith에서는 매우 간단한 OpenAI wrapper를 도입하여 이를 최대한 쉽게 만들었습니다. 다음과 같이 코드를 수정하기만 하면 됩니다:from langsmith.wrappers import wrap_openai를 import하고 이를 사용하여 OpenAI client를 래핑하는 방법(openai_client = wrap_openai(OpenAI()))을 주목하세요.
다음과 같은 방식으로 호출하면 어떻게 될까요?
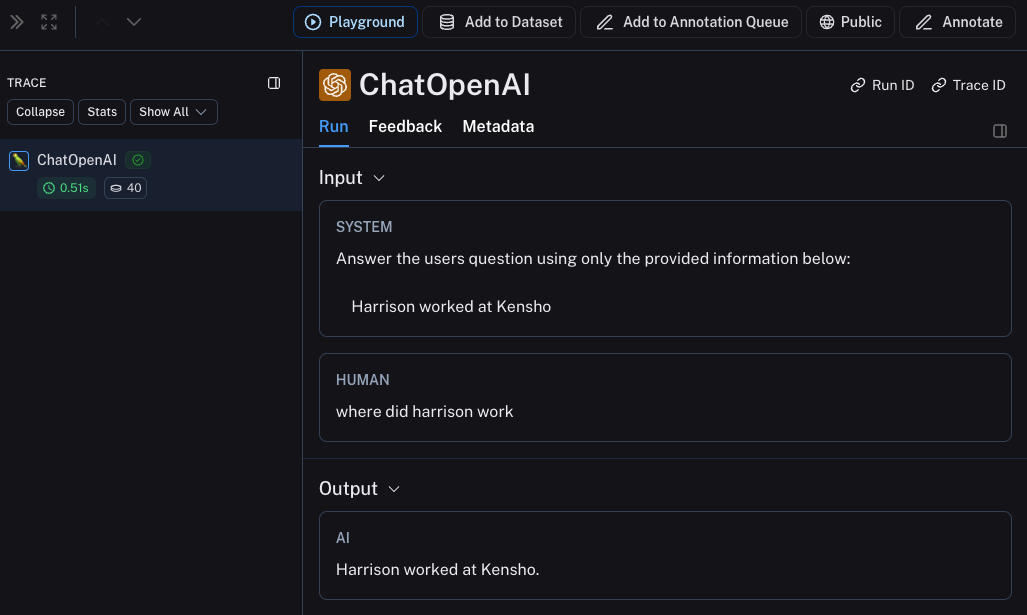
전체 체인 추적
좋습니다 - LLM 호출을 추적했습니다. 하지만 그 이상을 추적하는 것이 매우 유익한 경우가 많습니다. LangSmith는 전체 LLM 파이프라인을 추적하도록 설계되었습니다 - 그러니 그렇게 해봅시다! 이제 코드를 다음과 같이 수정하여 이를 수행할 수 있습니다:from langsmith import traceable을 import하고 이를 사용하여 전체 함수를 데코레이트하는 방법(@traceable)을 주목하세요.
다음과 같은 방식으로 호출하면 어떻게 될까요?
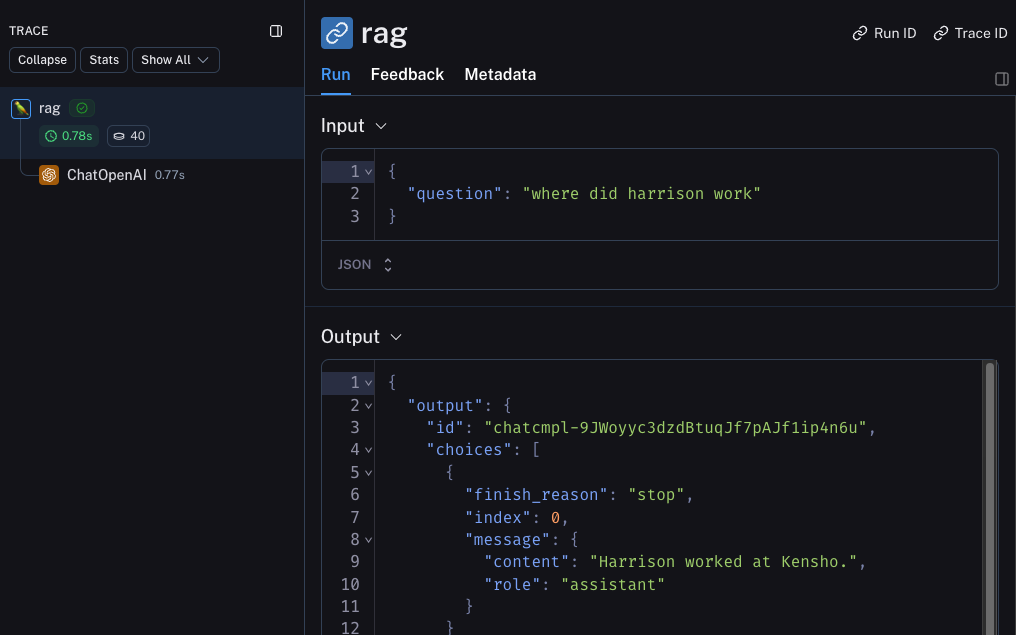
베타 테스팅
LLM 애플리케이션 개발의 다음 단계는 애플리케이션을 베타 테스트하는 것입니다. 이는 초기 사용자 몇 명에게 출시하는 단계입니다. 사용자가 실제로 애플리케이션을 어떻게 사용할지 정확히 알 수 없는 경우가 많기 때문에 여기서 좋은 관찰 가능성을 설정하는 것이 중요합니다. 이를 통해 사용자가 어떻게 사용하는지에 대한 인사이트를 얻을 수 있습니다. 이는 또한 이를 더 잘 허용하기 위해 추적 설정을 일부 변경하고 싶을 것임을 의미합니다. 이는 이전 섹션에서 설정한 관찰 가능성을 확장합니다.피드백 수집
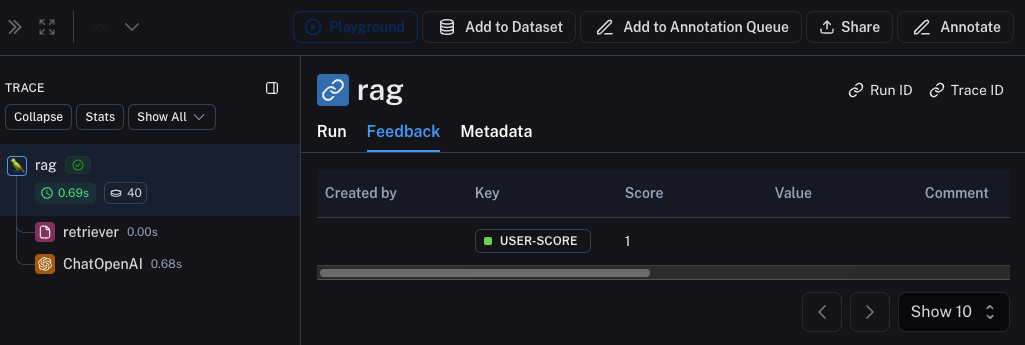
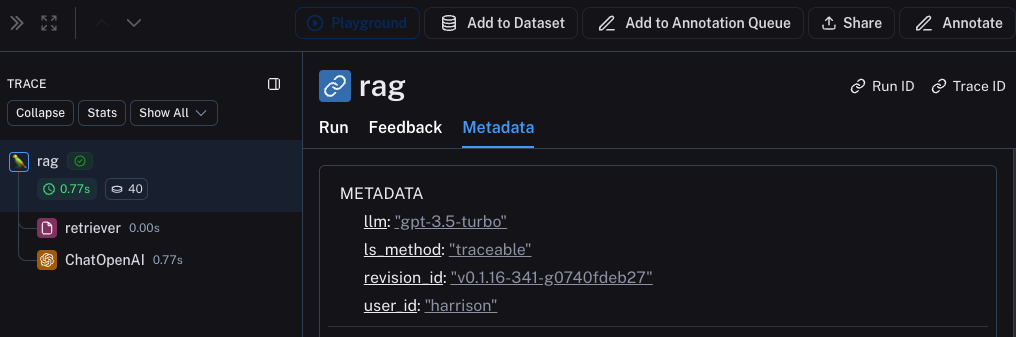
베타 테스트 중 좋은 관찰 가능성을 갖는 데 있어 큰 부분은 피드백을 수집하는 것입니다. 수집하는 피드백은 종종 애플리케이션에 따라 다르지만 최소한 간단한 좋아요/싫어요는 좋은 시작입니다. 피드백을 기록한 후에는 이를 해당 피드백을 발생시킨 run과 쉽게 연결할 수 있어야 합니다. 다행히 LangSmith는 이를 쉽게 수행할 수 있게 해줍니다. 먼저 앱에서 피드백을 기록해야 합니다. 이를 수행하는 쉬운 방법은 각 run에 대한 run ID를 추적한 다음 이를 사용하여 피드백을 기록하는 것입니다. run ID를 추적하는 것은 다음과 같습니다:Metadata 탭을 클릭하여 각 run과 연결된 피드백을 볼 수 있습니다. 이것과 같이 보일 것입니다
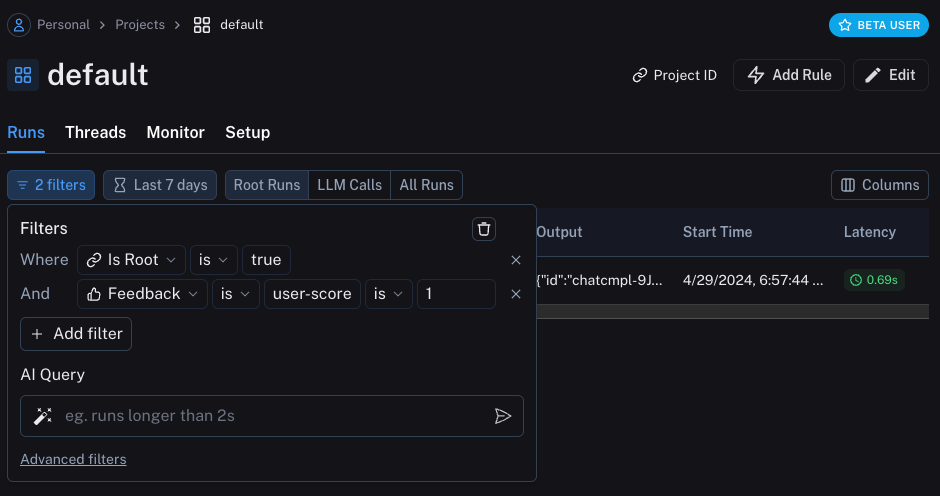
 runs 테이블의 필터링 로직을 사용하여 긍정적(또는 부정적) 피드백이 있는 모든 run을 쿼리할 수도 있습니다. 다음과 같은 필터를 생성하여 이를 수행할 수 있습니다:
runs 테이블의 필터링 로직을 사용하여 긍정적(또는 부정적) 피드백이 있는 모든 run을 쿼리할 수도 있습니다. 다음과 같은 필터를 생성하여 이를 수행할 수 있습니다:
메타데이터 기록
메타데이터 기록을 시작하는 것도 좋은 아이디어입니다. 이를 통해 앱의 다양한 속성을 추적할 수 있습니다. 이는 주어진 결과를 생성하는 데 사용된 앱의 버전이나 변형을 알 수 있도록 하는 데 중요합니다. 이 예제에서는 사용된 LLM을 기록합니다. 종종 다양한 LLM을 실험할 수 있으므로 해당 정보를 메타데이터로 갖는 것이 필터링에 유용할 수 있습니다. 이를 수행하기 위해 다음과 같이 추가할 수 있습니다:rag 함수에 @traceable(metadata={"llm": "gpt-4o-mini"})를 추가한 것을 주목하세요.
이러한 방식으로 메타데이터를 추적하는 것은 미리 알려진 것으로 가정합니다. 이는 LLM 유형에는 괜찮지만 User ID와 같은 다른 유형의 정보에는 덜 바람직합니다. 그러한 정보를 기록하기 위해 run ID와 함께 런타임에 전달할 수 있습니다.
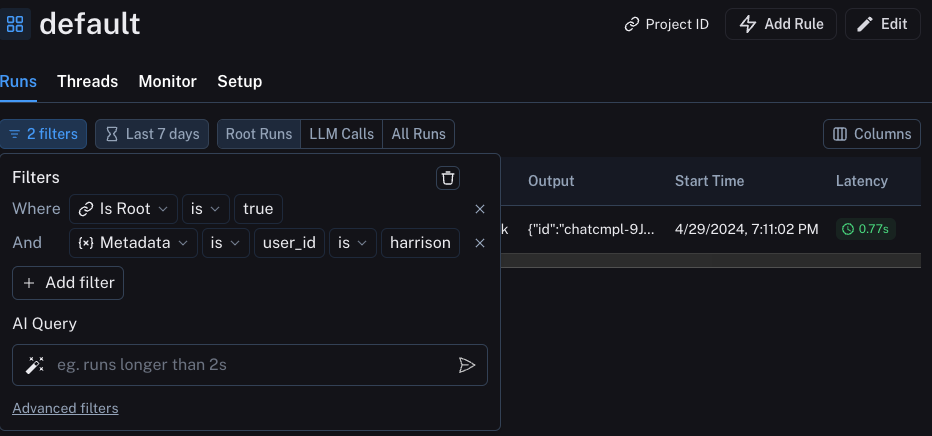
 다음과 같은 필터를 구성하여 이러한 정보를 필터링할 수 있습니다:
다음과 같은 필터를 구성하여 이러한 정보를 필터링할 수 있습니다:
프로덕션
좋습니다 - 이 새로운 관찰 가능성을 사용하여 빠르게 반복하고 앱이 잘 작동한다는 확신을 얻었습니다. 이제 프로덕션에 배포할 시간입니다! 어떤 새로운 관찰 가능성을 추가해야 할까요? 먼저, 이미 추가한 동일한 관찰 가능성이 프로덕션에서도 계속 가치를 제공할 것입니다. 특정 run을 계속 드릴다운할 수 있습니다. 프로덕션에서는 훨씬 더 많은 트래픽이 있을 것입니다. 따라서 한 번에 하나의 데이터 포인트를 보는 데 갇히고 싶지 않을 것입니다. 다행히 LangSmith에는 프로덕션에서 관찰 가능성을 돕는 일련의 도구가 있습니다.모니터링
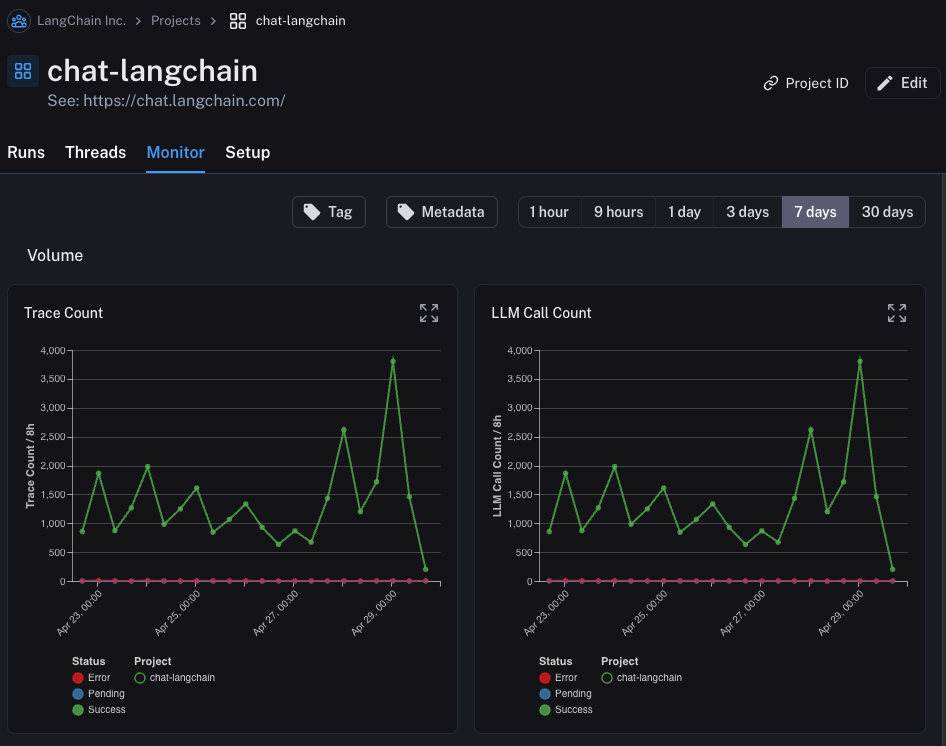
프로젝트의Monitor 탭을 클릭하면 일련의 모니터링 차트가 표시됩니다. 여기서는 trace 수, 피드백, time-to-first-token 등 많은 LLM 특정 통계를 추적합니다. 몇 가지 다른 시간 단위에 걸쳐 시간 경과에 따라 이를 볼 수 있습니다.
A/B 테스팅
A/B 테스팅을 위한 Group-by 기능을 사용하려면 주어진 메타데이터 키에 대해 최소 2개의 다른 값이 존재해야 합니다.
llm이었습니다. 모니터링 차트를 ANY 메타데이터 속성으로 그룹화하고 시간 경과에 따라 그룹화된 차트를 즉시 얻을 수 있습니다. 이를 통해 다양한 LLM(또는 프롬프트 또는 기타)을 실험하고 시간 경과에 따른 성능을 추적할 수 있습니다.
이를 수행하려면 상단의 Metadata 버튼을 클릭하기만 하면 됩니다. 그러면 그룹화할 옵션의 드롭다운이 표시됩니다:
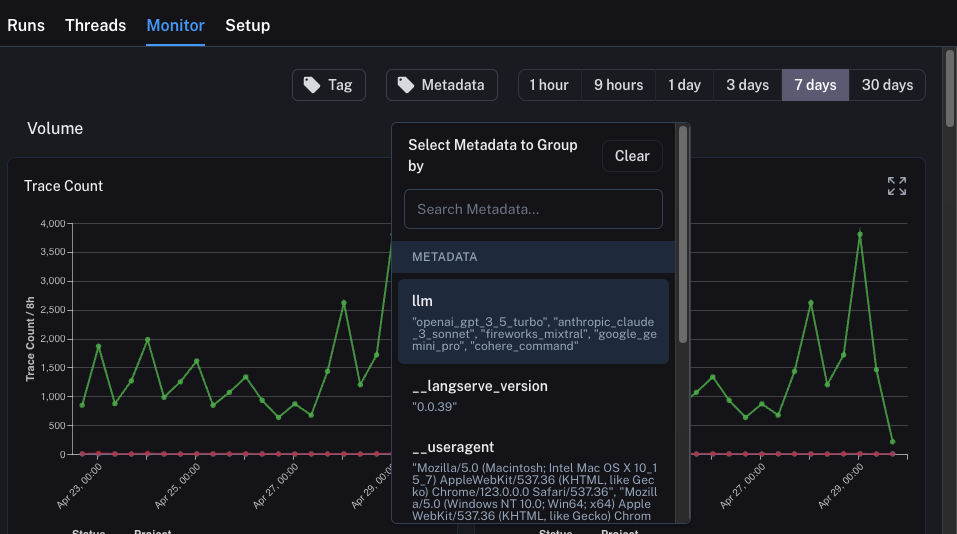 이를 선택하면 이 속성으로 그룹화된 차트가 표시되기 시작합니다:
이를 선택하면 이 속성으로 그룹화된 차트가 표시되기 시작합니다:
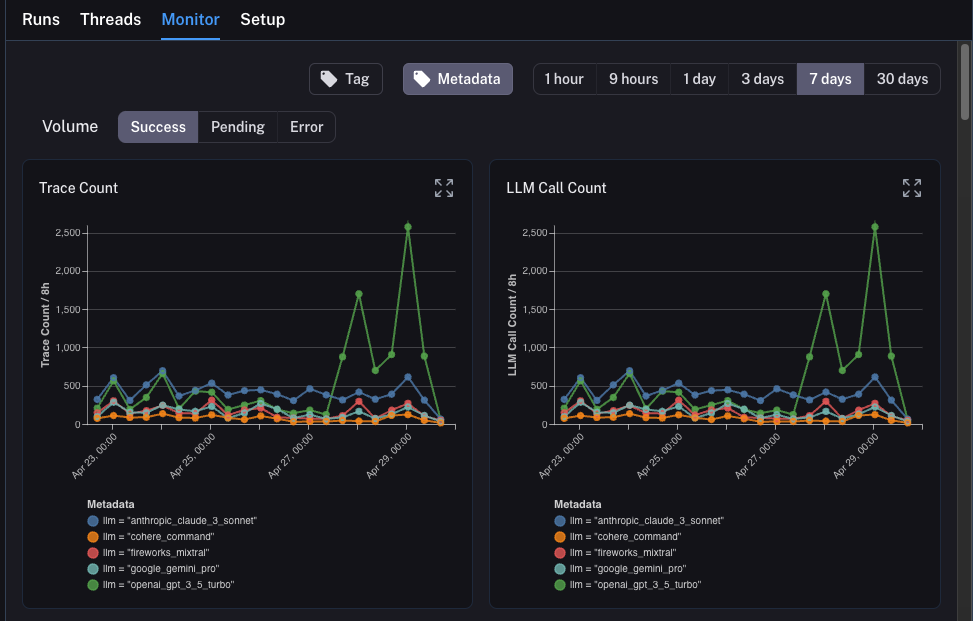
드릴다운
LangSmith가 제공하는 놀라운 기능 중 하나는 모니터링 차트를 보면서 문제가 있다고 식별한 데이터 포인트로 쉽게 드릴다운할 수 있는 기능입니다. 이를 수행하려면 모니터링 차트의 데이터 포인트 위로 마우스를 가져가기만 하면 됩니다. 이렇게 하면 데이터 포인트를 클릭할 수 있습니다. 그러면 필터링된 보기로 runs 테이블로 돌아갑니다: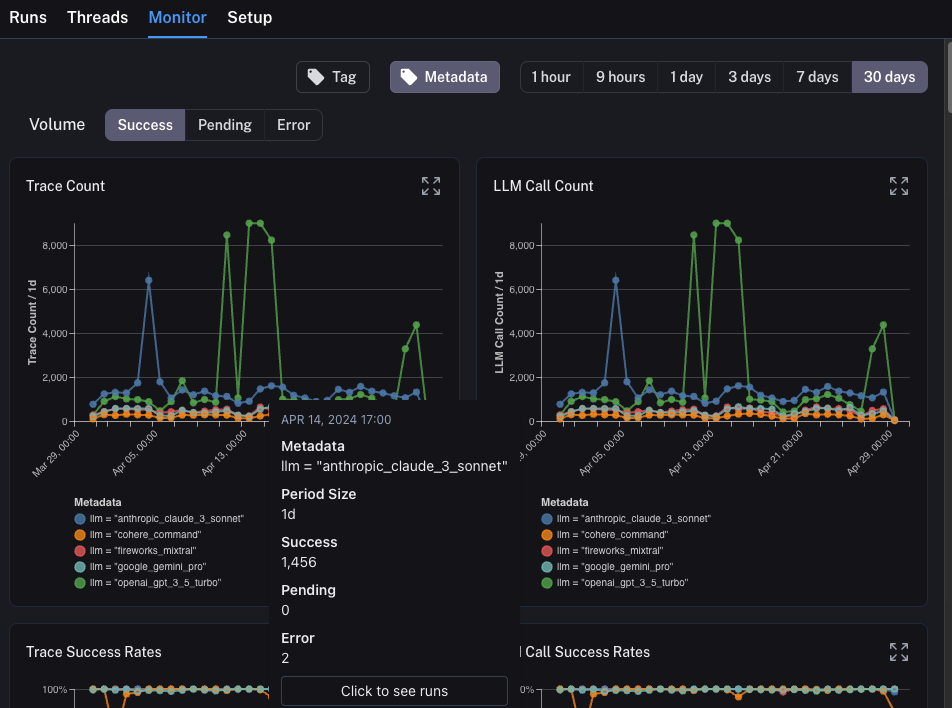
결론
이 튜토리얼에서는 최고 수준의 관찰 가능성으로 LLM 애플리케이션을 설정하는 방법을 살펴보았습니다. 애플리케이션이 어떤 단계에 있든 관찰 가능성의 이점을 누릴 수 있습니다. 관찰 가능성에 대한 더 심층적인 질문이 있는 경우 테스팅, 프롬프트 관리 등과 같은 주제에 대한 가이드는 how-to 섹션을 확인하세요.Connect these docs programmatically to Claude, VSCode, and more via MCP for real-time answers.