

사전 준비 사항
- OpenAI API 키(여기서 생성) 또는 Anthropic API 키(여기서 생성)
- LangSmith에서 규칙을 생성할 수 있는 권한(새 Insights Report를 생성하는 데 필요)
- LangSmith에서 tracing 프로젝트를 볼 수 있는 권한(기존 Insights Report를 보기 위해 필요)
첫 번째 Insights Report 생성하기
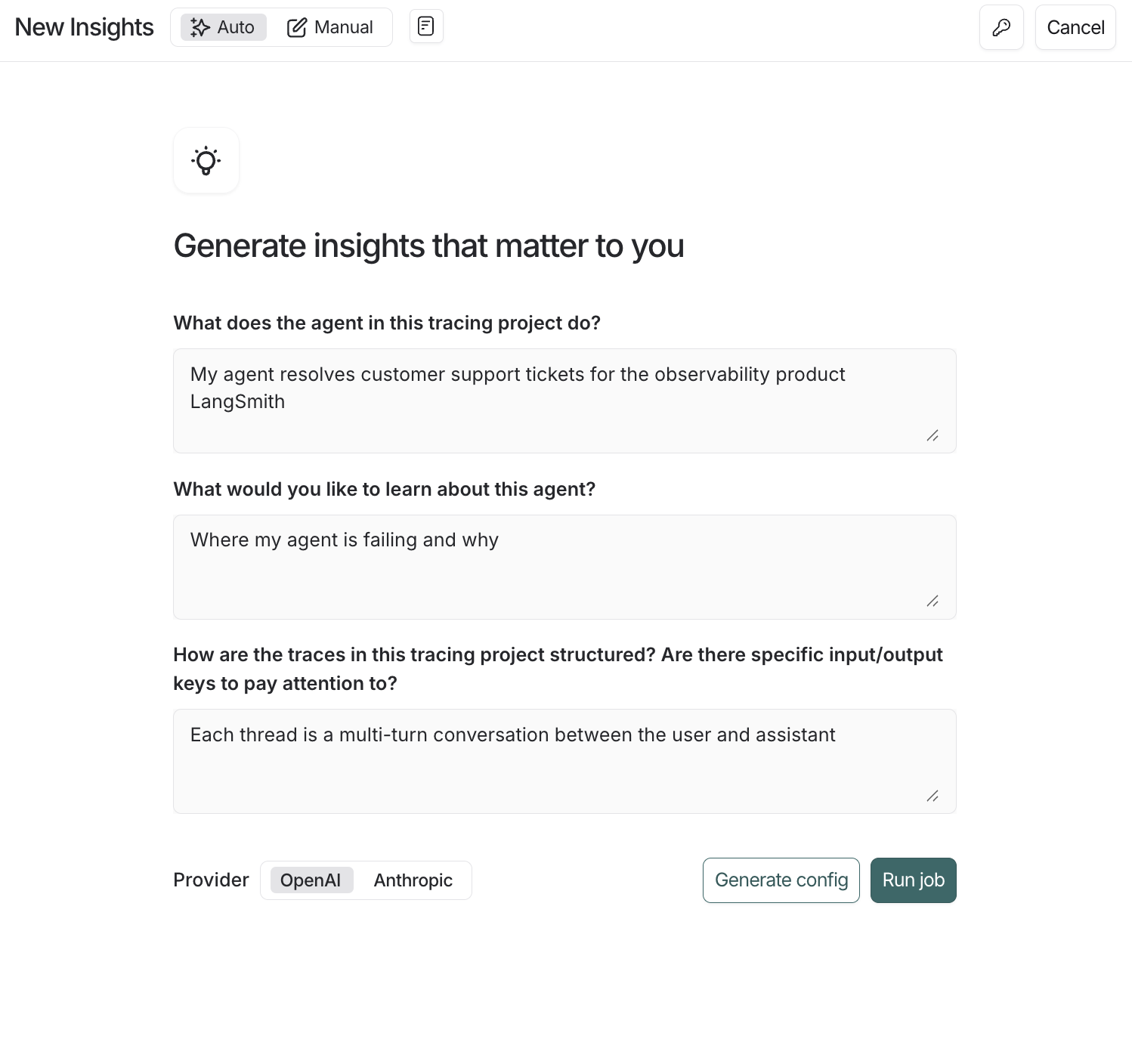
Insights Agent의 자동 구성 흐름
- 왼쪽 메뉴에서 Tracing Projects로 이동하여 tracing 프로젝트를 선택하세요.
- 오른쪽 상단의 +New를 클릭한 후 New Insights Report를 선택하여 프로젝트에 대한 새로운 인사이트를 생성하세요.
- 작업(job)의 이름을 입력하세요.
- 작업 생성 창의 오른쪽 상단에 있는 아이콘을 클릭하여 OpenAI(또는 Anthropic) API 키를 workspace secret으로 설정하세요. 이미 workspace에 OpenAI API 키가 설정되어 있다면 이 단계는 건너뛸 수 있습니다.
- 안내되는 질문에 답하여 Insights Report가 여러분의 agent에 대해 알고 싶은 내용에 집중하도록 한 뒤, Run job을 클릭하세요.
OpenAI 모델로 1,000개의 thread에 대해 인사이트를 생성하는 비용은 일반적으로 $1.00~$2.00이며, 현재 Anthropic 모델은 $3.00~$4.00입니다. 비용은 샘플링된 thread 수와 각 thread의 크기에 따라 증가합니다.
결과 이해하기
작업이 완료되면 Insights 탭으로 이동하여 Insights Report 테이블을 볼 수 있습니다. 각 Report는 tracing 프로젝트에서 특정 샘플의 trace에 대해 생성된 인사이트를 포함합니다.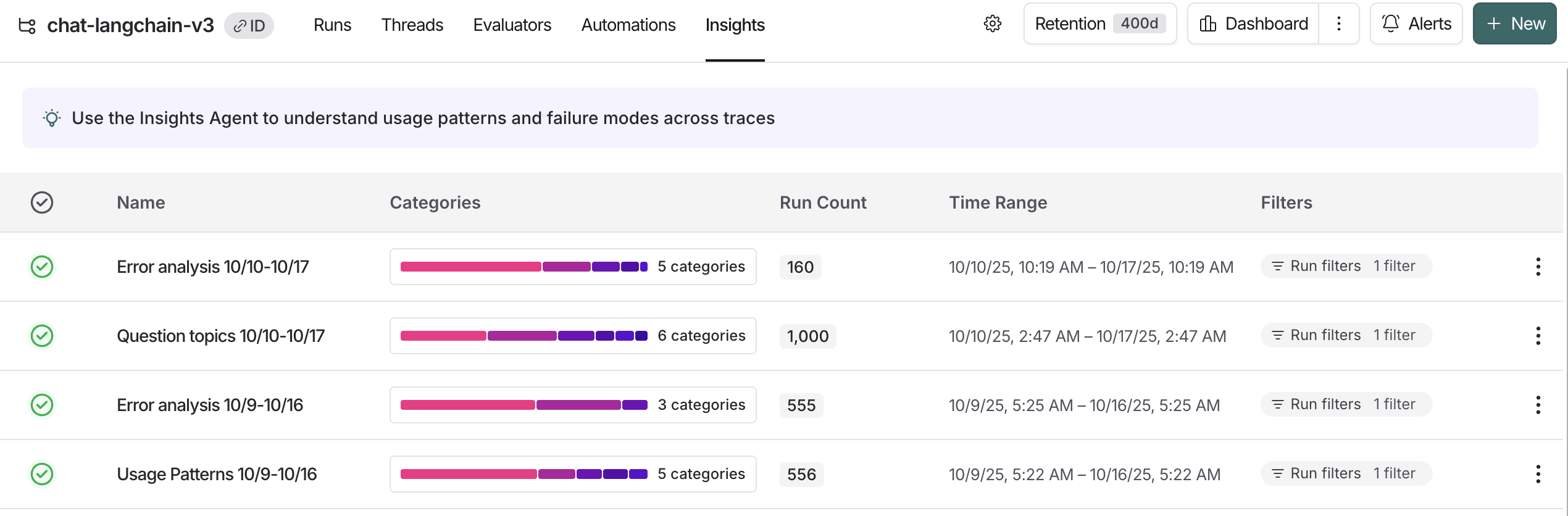
단일 tracing 프로젝트의 Insights Reports
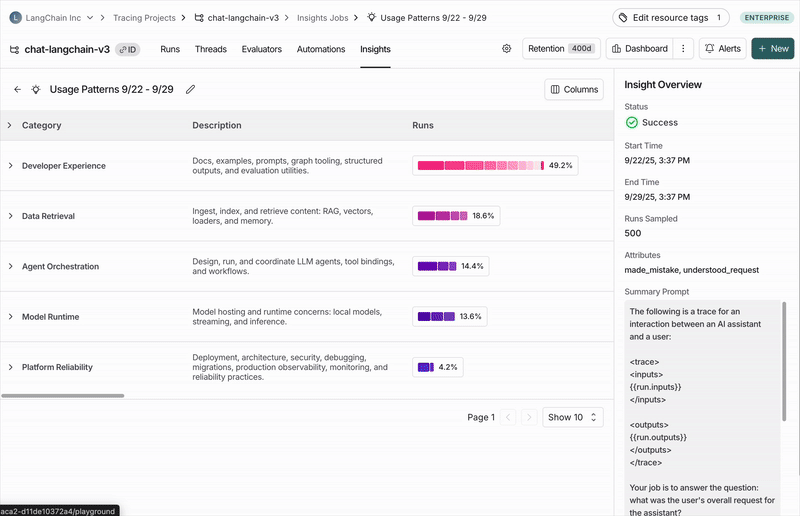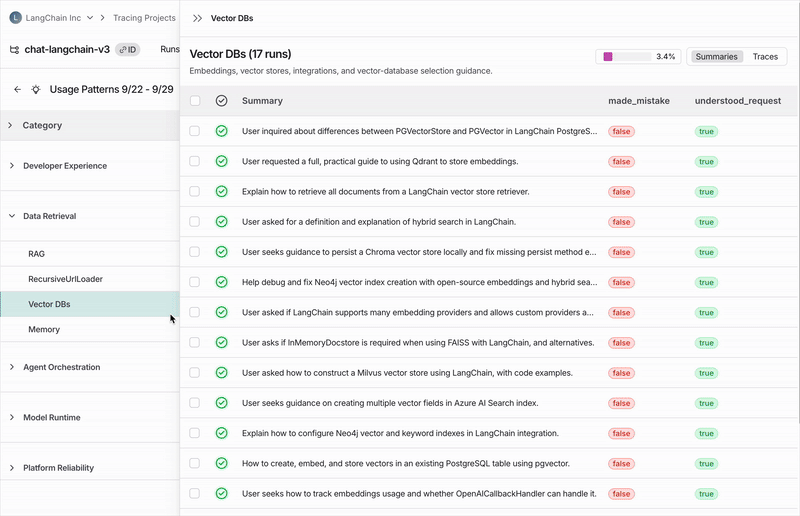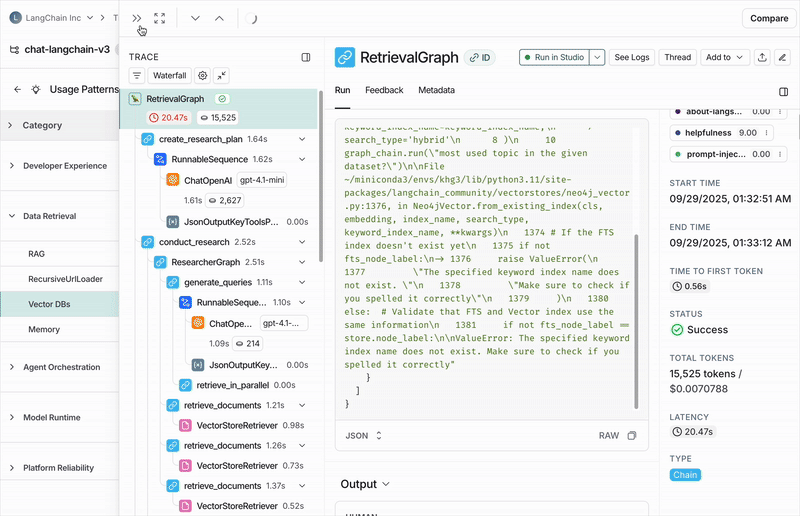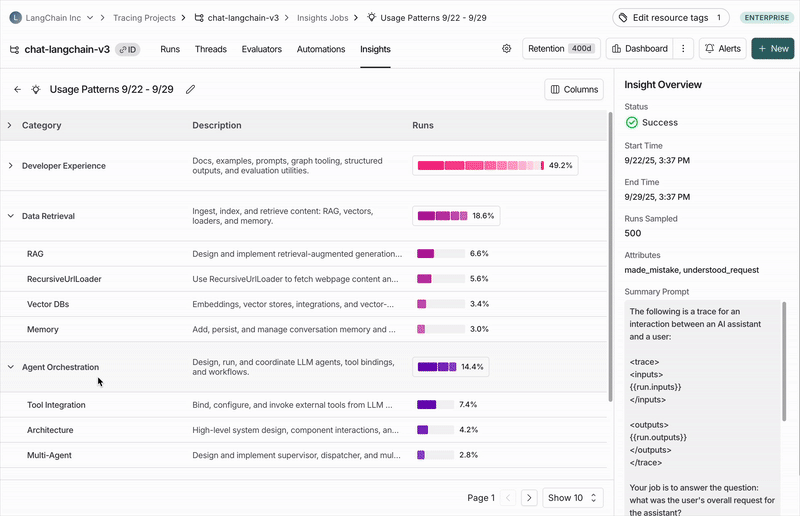
https://chat.langchain.com 챗봇과의 대화에서 자주 등장하는 주제
최상위 카테고리
여러분의 trace는 데이터에서 가장 넓은 패턴을 나타내는 최상위 카테고리로 자동 그룹화됩니다. 분포 막대는 각 패턴이 얼마나 자주 발생하는지 보여주어, 기대보다 더 자주 또는 덜 자주 발생하는 동작을 쉽게 파악할 수 있습니다. 각 카테고리에는 간단한 설명과 함께 포함된 trace에 대한 집계 지표가 표시됩니다. 예를 들어:- 일반적인 trace 통계(오류율, 지연 시간, 비용 등)
- 평가자의 피드백 점수
- 작업의 일부로 추출된 Attributes
하위 카테고리
카테고리를 클릭하면 하위 카테고리로 세분화되어 해당 trace 카테고리 내 상호작용 패턴을 더 세밀하게 이해할 수 있습니다. 위의 Chat Langchain 예시에서는 “Data & Retrieval” 아래에 “Vector Stores”와 “Data Ingestion” 같은 하위 카테고리가 있습니다.개별 trace
카테고리 또는 하위 카테고리에 할당된 trace는 trace 테이블을 통해 볼 수 있습니다. 여기서 각 trace를 클릭하여 전체 대화 내용을 확인할 수 있습니다.작업 구성하기
Insights Report는 세 가지 방법으로 생성할 수 있습니다. 자동 생성 흐름으로 기본 구성을 시작한 후, 저장된 설정이나 수동 설정을 반복적으로 수정하며 정교하게 다듬을 수 있습니다.구성 자동 생성하기
- New Insights를 열고 Auto 토글이 활성화되어 있는지 확인하세요.
- agent의 목적, 알고 싶은 내용, trace 구조에 대한 자연어 질문에 답하세요. Insights는 여러분의 답변을 초안 구성(작업 이름, 요약 프롬프트, 속성, 샘플링 기본값)으로 변환합니다.
- 제공자를 선택한 후 Generate config로 미리보기를 하거나 Run job으로 즉시 실행하세요.
모델 제공자 선택하기
agent를 구동할 모델로 OpenAI 또는 Anthropic 중 하나를 선택할 수 있습니다. 선택한 제공자에 맞는 workspace secret(OPENAI_API_KEY 또는 ANTHROPIC_API_KEY)이 반드시 설정되어 있어야 합니다. 현재 Anthropic 모델 사용 시 비용이 OpenAI 모델 대비 약 3배 더 높다는 점을 참고하세요.미리 만들어진 구성 사용하기
Saved configurations 드롭다운을 사용하여 Usage Patterns 또는 Error Analysis와 같은 일반적인 작업에 대한 프리셋을 불러올 수 있습니다. 바로 실행하여 빠르게 시작하거나, 필터, 프롬프트, 제공자를 조정한 후 맞춤 버전을 저장하세요. 커스터마이즈 가능한 항목에 대해 더 알고 싶다면 아래 섹션을 참고하세요.직접 구성 만들기
직접 구성(config)을 만들면 더 세밀한 제어가 가능합니다 — 예를 들어, 데이터를 그룹화할 카테고리를 미리 정의하거나 특정 피드백 점수 및 필터에 맞는 trace만 대상으로 할 수 있습니다.trace 선택
- Sample size: 분석할 trace의 최대 개수(현재 1,000개로 제한)
- Time range: 이 시간 범위에서 trace가 샘플링됨
- Filters: 추가 trace 필터. 필터를 조정하면 기준에 맞는 trace 개수를 확인할 수 있습니다.
카테고리
기본적으로 최상위 카테고리는 하위 trace에서 bottom-up 방식으로 자동 생성됩니다. 특정 카테고리에 관심이 있다면, 작업이 trace를 미리 정의된 카테고리로 분류하도록 할 수 있습니다. 구성의 Categories 섹션에서 사용하고 싶은 최상위 카테고리의 이름과 설명을 나열할 수 있습니다. 하위 카테고리는 여전히 알고리즘이 미리 정의된 최상위 카테고리 내에서 자동 생성합니다.요약 프롬프트
작업의 첫 단계는 각 trace에 대한 간단한 요약을 만드는 것입니다 — 이 요약들이 이후 분류됩니다. 요약에서 올바른 정보를 추출하는 것이 유용한 카테고리를 얻는 데 필수적입니다. 요약을 생성하는 데 사용되는 프롬프트는 편집할 수 있습니다. 프롬프트를 편집할 때 고려해야 할 두 가지:- 요약 지침: trace 요약에 포함되지 않은 정보는 생성되는 카테고리에 영향을 주지 않으므로, 각 trace에서 어떤 정보를 추출해야 하는지 명확하게 지침을 제공하세요.
- trace 내용: mustache 포맷을 사용하여 각 trace의 어떤 부분을 요약기에 전달할지 지정하세요. 입력과 출력이 많은 대형 trace는 비용이 많이 들고 노이즈가 많을 수 있습니다. 프롬프트를 가장 관련성 높은 부분만 포함하도록 줄이면 결과가 개선됩니다.
| Variable | Best for | Example |
|---|---|---|
| run.* | thread에서 가장 최근의 root run(즉, 마지막 턴)의 데이터 접근 | {{run.inputs}} {{run.outputs}} {{run.error}} |
"Summarize this: {{run.inputs.foo.bar}}"는 마지막 run의 inputs에서 “foo”의 “bar” 값만 포함합니다.
속성(Attributes)
요약과 함께, 각 trace에서 추가로 범주형, 수치형, 불리언 속성을 추출하도록 정의할 수 있습니다. 이 속성들은 분류 단계에 영향을 주며 — 유사한 속성 값을 가진 trace는 함께 분류되는 경향이 있습니다. 또한 각 카테고리별로 이 속성의 집계도 볼 수 있습니다. 예를 들어, 각 trace에서user_satisfied: boolean 속성을 추출하여 알고리즘이 긍정적/부정적 사용자 경험을 구분하는 카테고리로 분류하도록 유도하고, 카테고리별 평균 사용자 만족도를 볼 수 있습니다.
속성 필터링
불리언 속성에filter_by 파라미터를 사용하여 인사이트 생성 전에 trace를 미리 필터링할 수 있습니다. 활성화하면 해당 속성이 true인 trace만 분석에 포함됩니다.
이는 특정 trace 집합에만 집중하여 Insights Report를 생성하고 싶을 때 유용합니다 — 예를 들어, 오류만 분석하거나, 영어 대화만 검토하거나, 특정 품질 기준을 충족하는 trace만 포함할 때 등입니다.
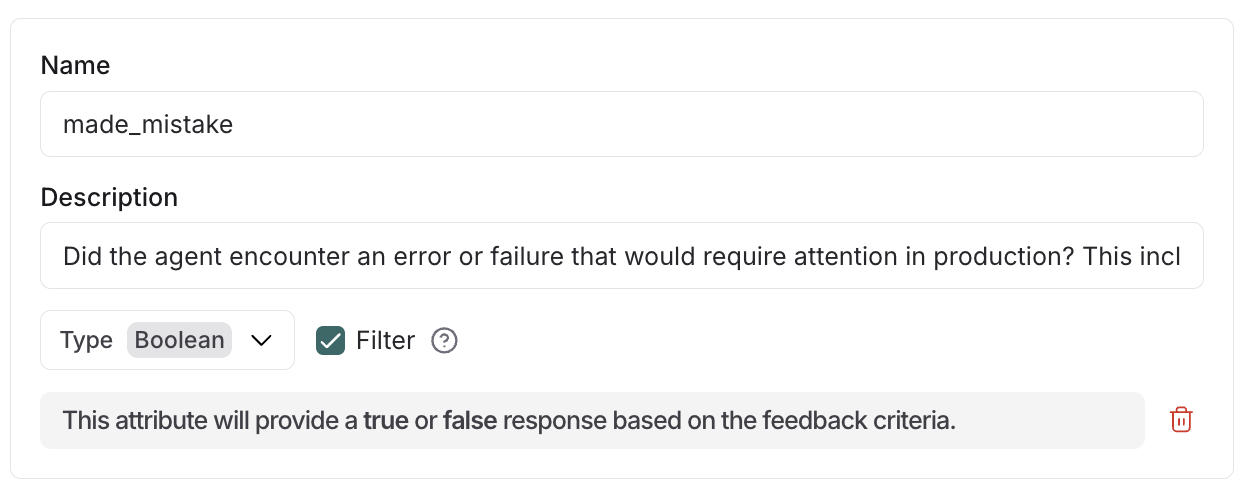
agent 오류가 있는 trace에만 인사이트를 생성하기 위해 filter 속성 사용
- Insights Agent의 구성 생성 시 불리언 속성에
"filter_by": true를 추가하세요 - LLM이 요약 과정에서 각 trace를 속성 설명에 따라 평가합니다
- 속성이
false이거나 누락된 trace는 인사이트 생성 전에 제외됩니다
구성 저장하기
구성을 ‘save as’ 버튼으로 저장하여 향후 재사용할 수 있습니다. 이는 시간에 따라 Insights Report를 비교하여 사용자 및 agent 행동 변화를 파악하고 싶을 때 특히 유용합니다. 새 Insights Report를 생성할 때 창의 왼쪽 상단 드롭다운에서 이전에 저장한 구성을 선택할 수 있습니다.Connect these docs programmatically to Claude, VSCode, and more via MCP for real-time answers.