

이 기능은 오픈 베타 버전입니다. 유료 팀 플랜에서만 사용할 수 있습니다. 활성화에 대한 질문이 있으시면 [email protected]로 문의해 주세요.
사전 조건
- 데이터셋은 KV store 데이터 타입을 사용해야 합니다 (현재 chat model 또는 LLM 타입 데이터셋은 지원하지 않습니다)
- 데이터셋에 대한 input schema가 정의되어 있어야 합니다. 자세한 내용은 UI에서 스키마 검증 설정하기에 대한 문서를 참조하세요.
- 유료 팀 플랜(예: Plus 플랜)을 사용해야 합니다
- LangSmith cloud를 사용해야 합니다
few shot 검색을 위한 데이터셋 인덱싱
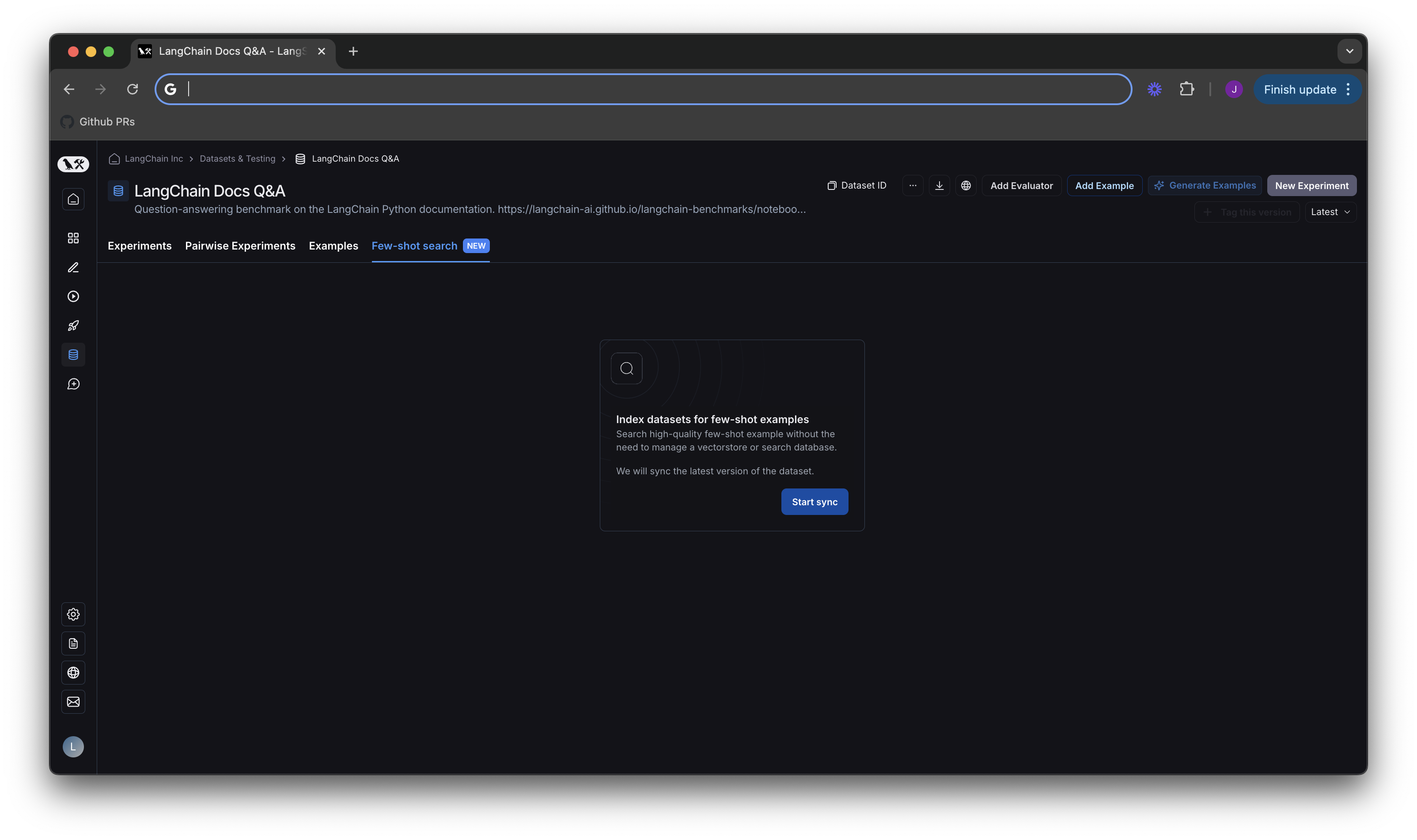
데이터셋 UI로 이동하여 새로운Few-Shot search 탭을 클릭하세요. Start sync 버튼을 누르면 데이터셋에 새로운 인덱스가 생성되어 검색 가능하게 됩니다.
 기본적으로 데이터셋의 최신 버전과 동기화됩니다. 즉, 데이터셋에 새로운 예제가 추가되면 자동으로 인덱스에 추가됩니다. 이 프로세스는 몇 분마다 실행되므로 새로운 예제를 인덱싱하는 데 매우 짧은 지연만 발생합니다. 다음 섹션의 화면 왼쪽에 있는
기본적으로 데이터셋의 최신 버전과 동기화됩니다. 즉, 데이터셋에 새로운 예제가 추가되면 자동으로 인덱스에 추가됩니다. 이 프로세스는 몇 분마다 실행되므로 새로운 예제를 인덱싱하는 데 매우 짧은 지연만 발생합니다. 다음 섹션의 화면 왼쪽에 있는 Few-shot index에서 인덱스가 최신 상태인지 확인할 수 있습니다.
few shot playground에서 검색 품질 테스트
데이터셋에 대한 인덱싱을 활성화하면 새로운 few shot playground가 표시됩니다.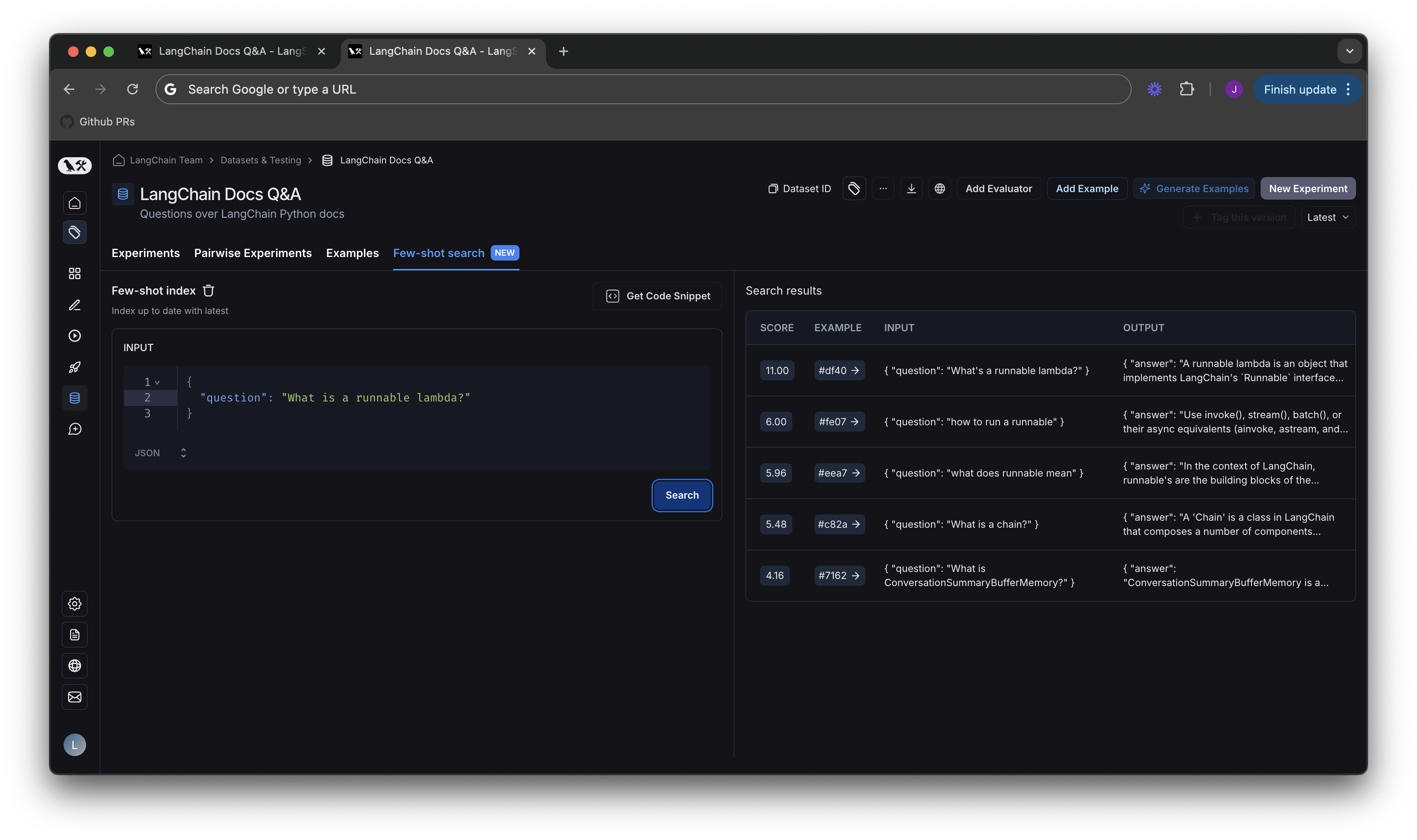 각 결과에는 점수와 데이터셋의 예제로 연결되는 링크가 있습니다. 점수 시스템은 0이 완전히 무작위 결과이고 점수가 높을수록 더 좋습니다. 결과는 점수에 따라 내림차순으로 정렬됩니다.
각 결과에는 점수와 데이터셋의 예제로 연결되는 링크가 있습니다. 점수 시스템은 0이 완전히 무작위 결과이고 점수가 높을수록 더 좋습니다. 결과는 점수에 따라 내림차순으로 정렬됩니다.
검색은 키워드 기반 유사도 점수를 위해 BM25와 유사한 알고리즘을 사용합니다. 실제 점수는 검색 알고리즘을 개선함에 따라 변경될 수 있으므로 점수 자체에 의존하지 않는 것이 좋습니다. 점수의 의미는 시간이 지남에 따라 변경될 수 있습니다. 점수는 단순히 playground에서 출력을 테스트할 때 편의를 위해 사용됩니다.
애플리케이션에 few shot 검색 추가하기
이전 다이어그램의Get Code Snippet 버튼을 클릭하면 다양한 언어로 작성된 LangSmith SDK의 코드 스니펫이 있는 화면으로 이동합니다.
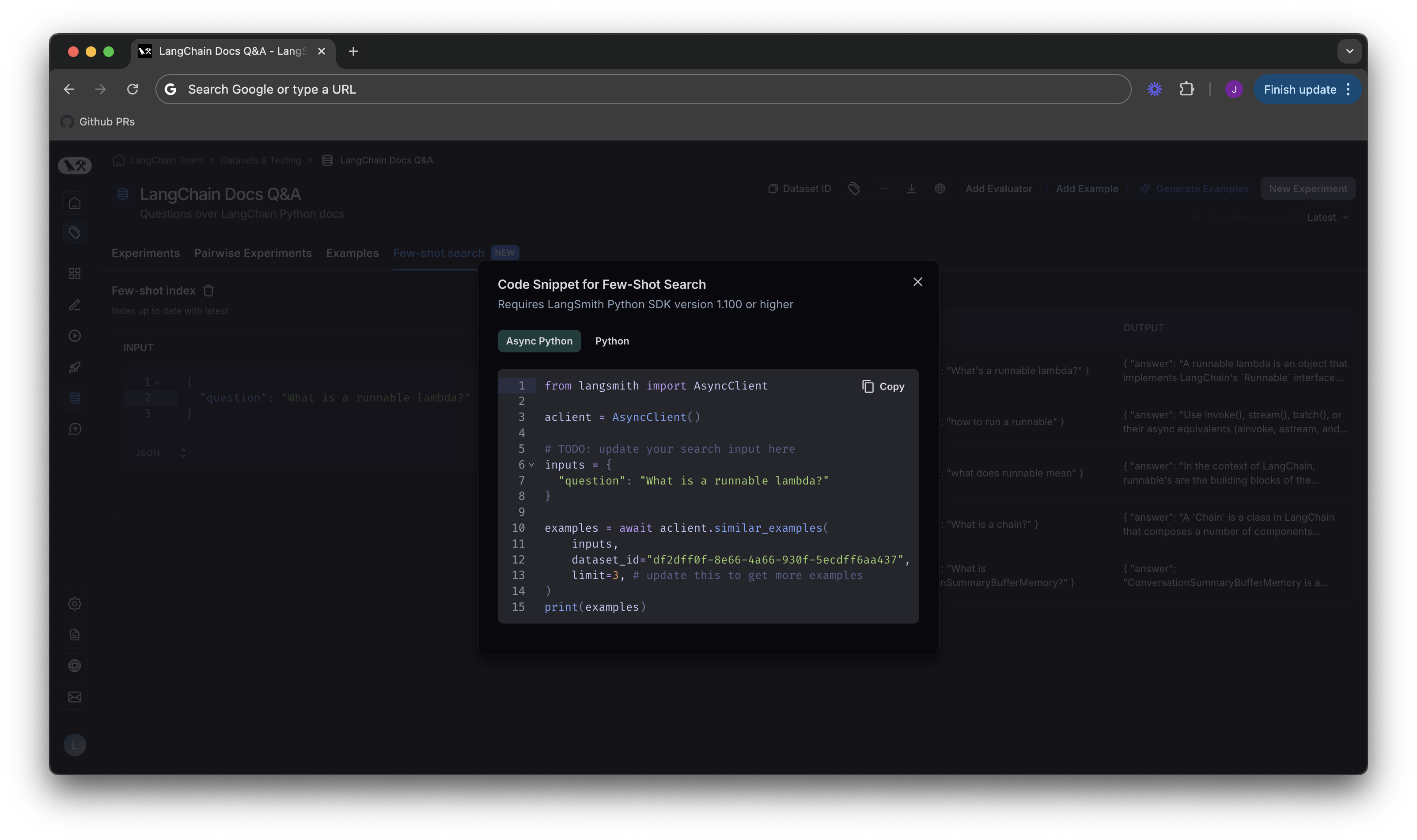 LangChain python 애플리케이션에서 few shot 검색을 사용하는 코드 샘플은 LangChain 문서의 how-to 가이드를 참조하세요.
LangChain python 애플리케이션에서 few shot 검색을 사용하는 코드 샘플은 LangChain 문서의 how-to 가이드를 참조하세요.
코드 스니펫
python SDK는 버전 >= 1.101, typescript SDK는 버전 >= 1.43을 사용하고 있는지 확인하세요
Connect these docs programmatically to Claude, VSCode, and more via MCP for real-time answers.