

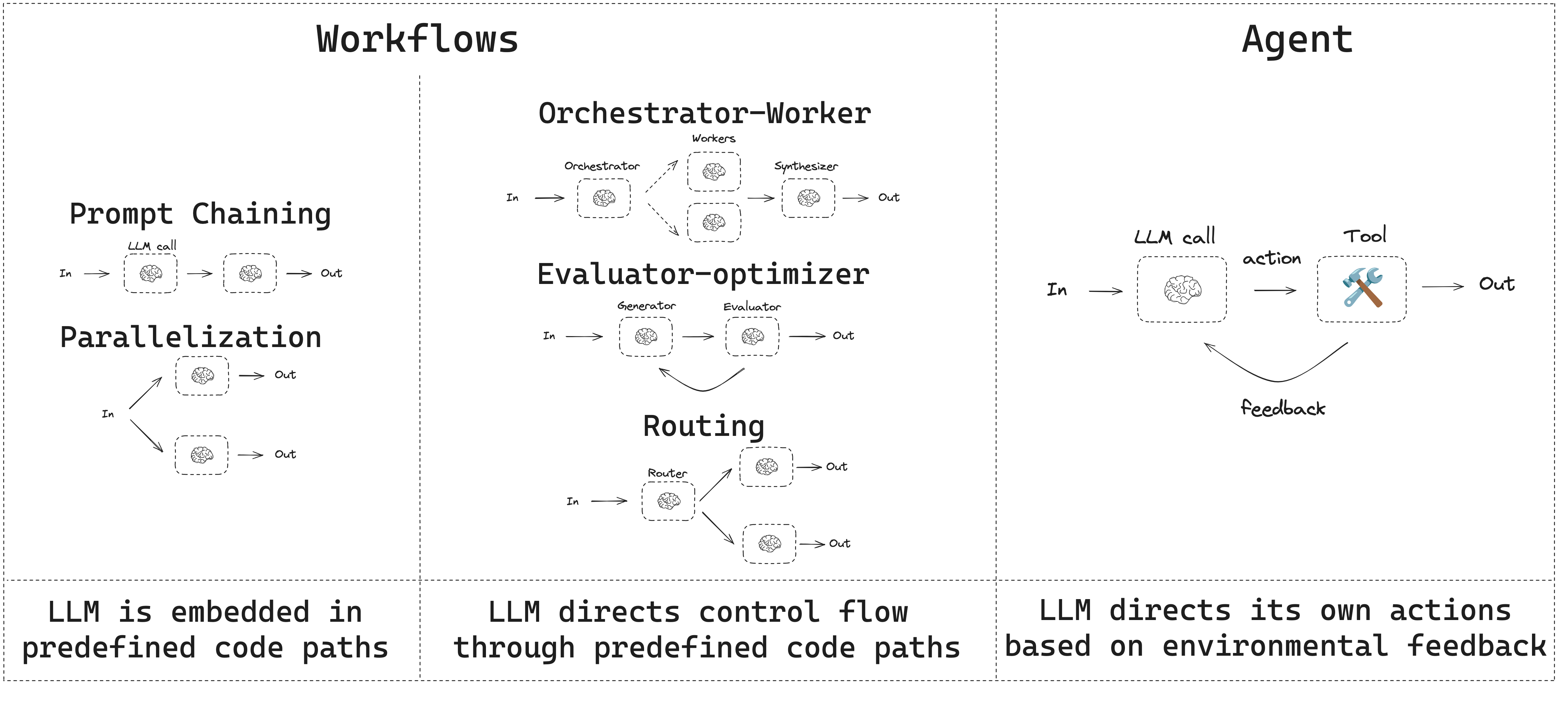
- Workflow는 미리 정의된 코드 경로를 가지며 특정 순서로 작동하도록 설계되었습니다.
- Agent는 동적이며 자체 프로세스와 도구 사용을 정의합니다.
 LangGraph는 agent와 workflow를 구축할 때 persistence, streaming, 디버깅 지원 및 deployment를 포함한 여러 이점을 제공합니다.
LangGraph는 agent와 workflow를 구축할 때 persistence, streaming, 디버깅 지원 및 deployment를 포함한 여러 이점을 제공합니다.
Setup
workflow 또는 agent를 구축하려면 structured output과 tool calling을 지원하는 모든 chat model을 사용할 수 있습니다. 다음 예제는 Anthropic을 사용합니다:- dependency 설치:
- LLM 초기화:
LLM과 augmentation
Workflow와 agentic 시스템은 LLM과 이에 추가하는 다양한 augmentation을 기반으로 합니다. Tool calling, structured output, short term memory는 LLM을 필요에 맞게 조정하기 위한 몇 가지 옵션입니다.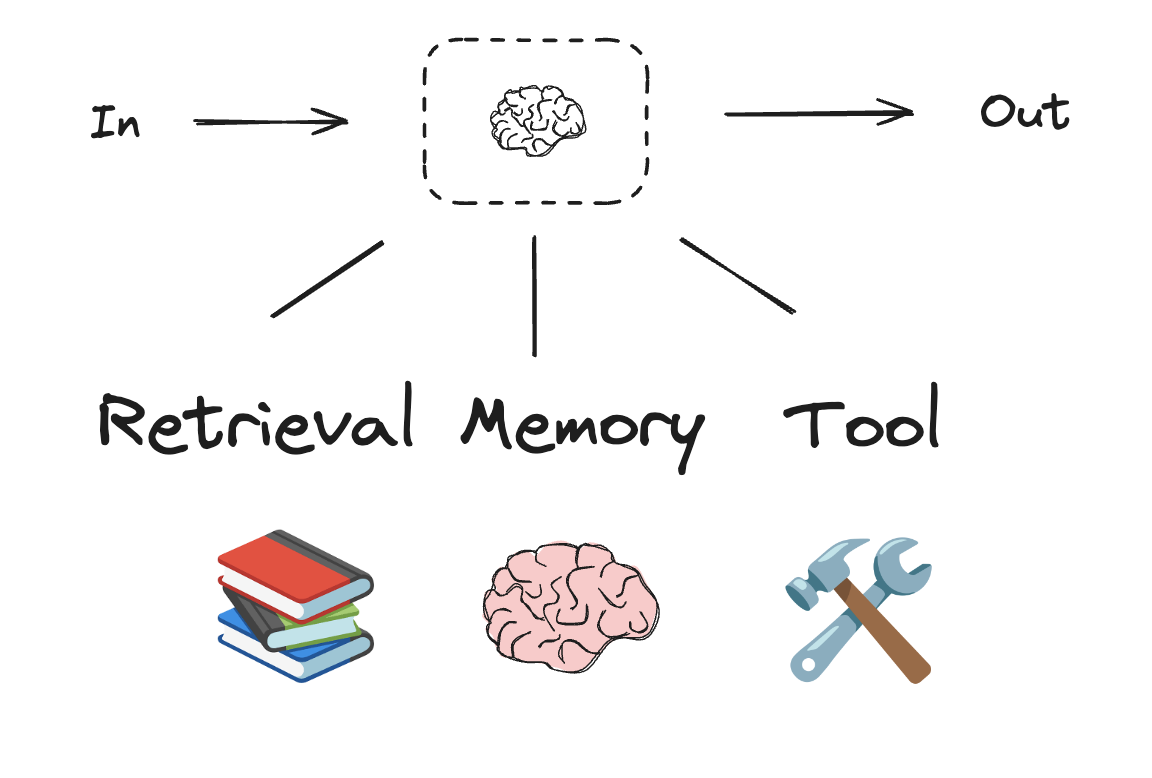
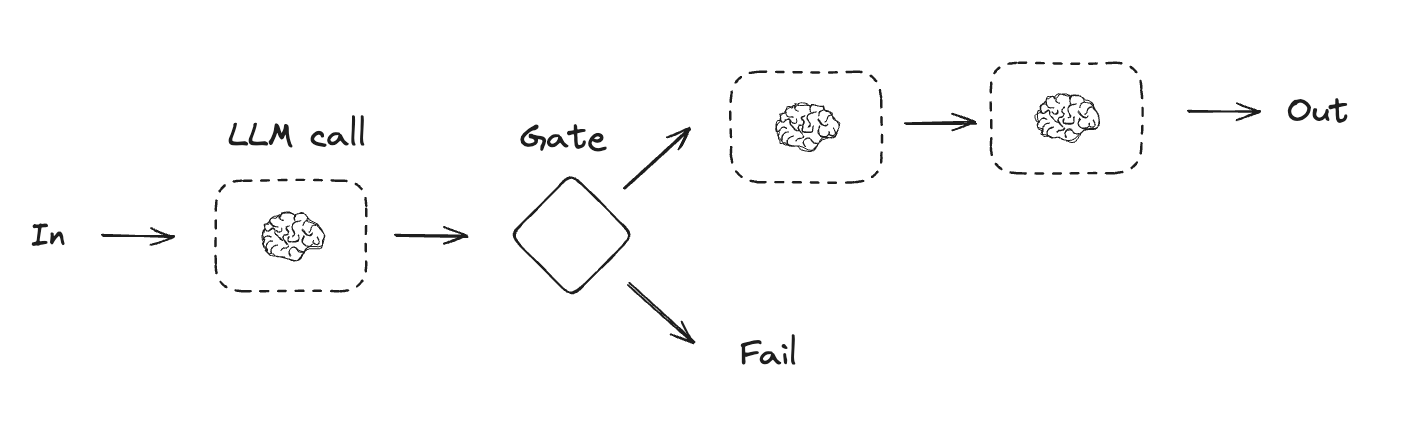
Prompt chaining
Prompt chaining은 각 LLM 호출이 이전 호출의 출력을 처리하는 방식입니다. 이는 더 작고 검증 가능한 단계로 나눌 수 있는 명확하게 정의된 작업을 수행하는 데 자주 사용됩니다. 몇 가지 예는 다음과 같습니다:- 문서를 다른 언어로 번역
- 생성된 콘텐츠의 일관성 검증
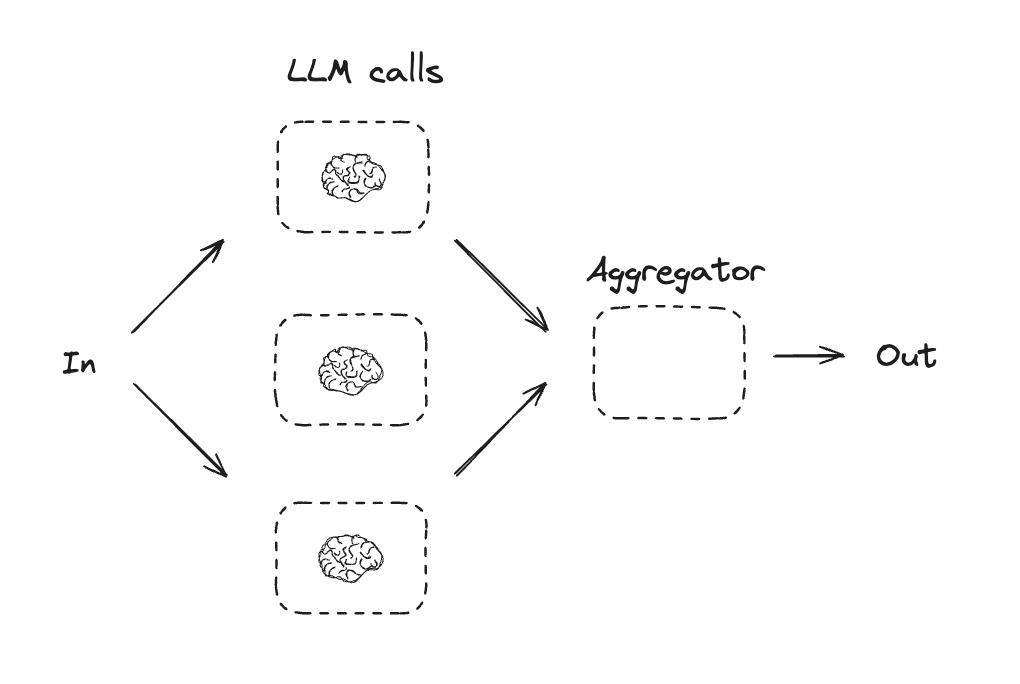
Parallelization
Parallelization에서는 LLM이 작업을 동시에 수행합니다. 이는 여러 독립적인 하위 작업을 동시에 실행하거나, 동일한 작업을 여러 번 실행하여 다른 출력을 확인하는 방식으로 수행됩니다. Parallelization은 일반적으로 다음과 같은 용도로 사용됩니다:- 하위 작업을 분할하고 병렬로 실행하여 속도 향상
- 작업을 여러 번 실행하여 다른 출력을 확인하고 신뢰도 향상
- 문서에서 키워드를 처리하는 하나의 하위 작업과 형식 오류를 확인하는 두 번째 하위 작업을 실행
- 인용 수, 사용된 출처 수, 출처의 품질과 같은 다양한 기준에 따라 문서의 정확성을 평가하는 작업을 여러 번 실행
Routing
Routing workflow는 입력을 처리한 다음 컨텍스트별 작업으로 전달합니다. 이를 통해 복잡한 작업에 대한 특화된 흐름을 정의할 수 있습니다. 예를 들어, 제품 관련 질문에 답변하도록 구축된 workflow는 먼저 질문 유형을 처리한 다음 가격, 환불, 반품 등에 대한 특정 프로세스로 요청을 라우팅할 수 있습니다.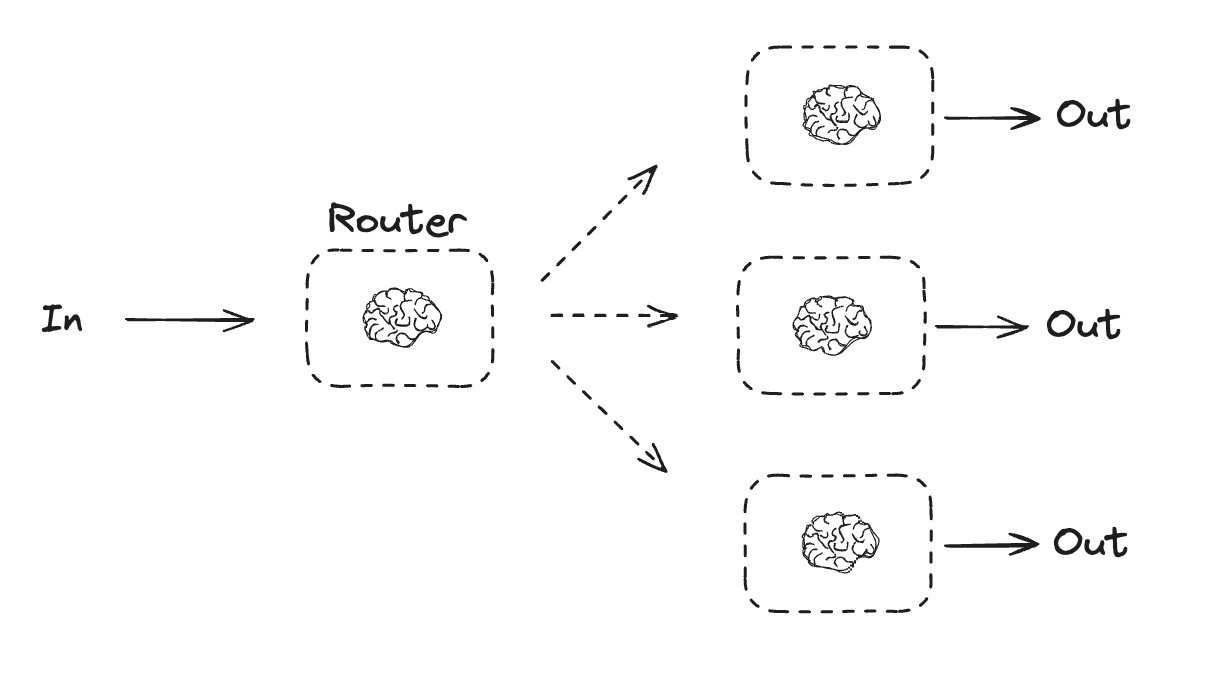
Orchestrator-worker
Orchestrator-worker 구성에서 orchestrator는:- 작업을 하위 작업으로 분해
- 하위 작업을 worker에게 위임
- worker 출력을 최종 결과로 합성
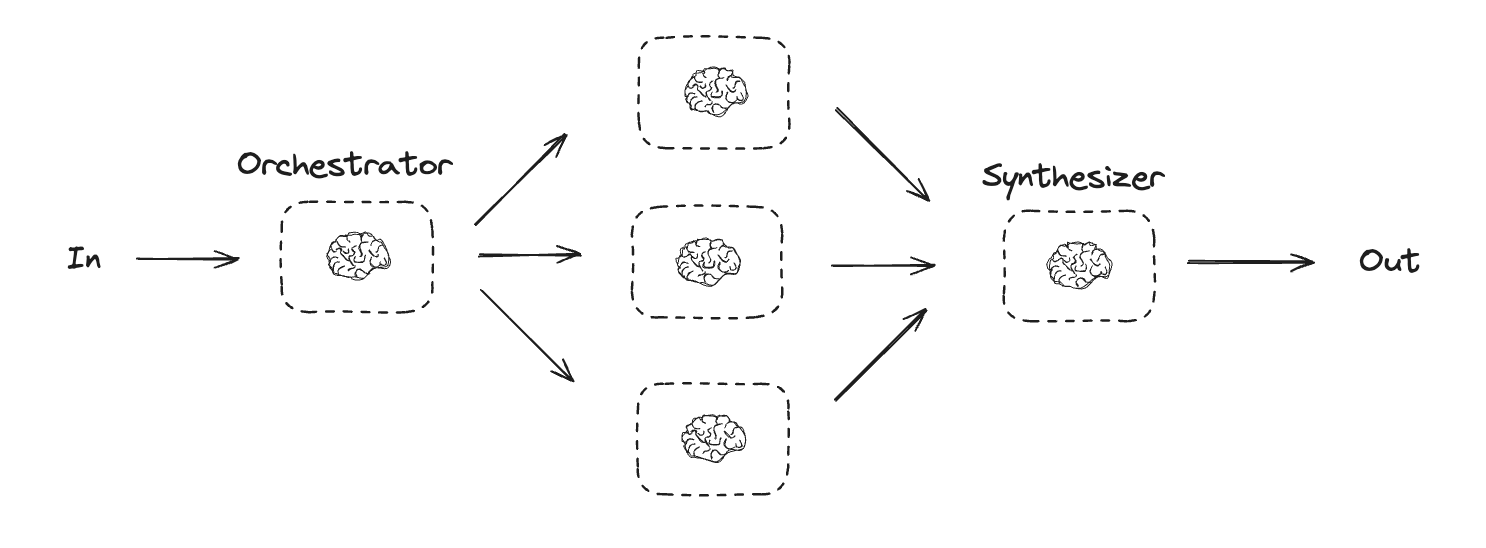 Orchestrator-worker workflow는 더 많은 유연성을 제공하며, parallelization처럼 하위 작업을 미리 정의할 수 없는 경우에 자주 사용됩니다. 이는 코드를 작성하거나 여러 파일에 걸쳐 콘텐츠를 업데이트해야 하는 workflow에서 일반적입니다. 예를 들어, 알 수 없는 수의 문서에서 여러 Python 라이브러리에 대한 설치 지침을 업데이트해야 하는 workflow는 이 패턴을 사용할 수 있습니다.
Orchestrator-worker workflow는 더 많은 유연성을 제공하며, parallelization처럼 하위 작업을 미리 정의할 수 없는 경우에 자주 사용됩니다. 이는 코드를 작성하거나 여러 파일에 걸쳐 콘텐츠를 업데이트해야 하는 workflow에서 일반적입니다. 예를 들어, 알 수 없는 수의 문서에서 여러 Python 라이브러리에 대한 설치 지침을 업데이트해야 하는 workflow는 이 패턴을 사용할 수 있습니다.
LangGraph에서 worker 생성하기
Orchestrator-worker workflow는 일반적이며 LangGraph는 이를 기본적으로 지원합니다.Send API를 사용하면 worker node를 동적으로 생성하고 특정 입력을 전송할 수 있습니다. 각 worker는 자체 state를 가지며, 모든 worker 출력은 orchestrator graph에서 액세스할 수 있는 공유 state key에 기록됩니다. 이를 통해 orchestrator는 모든 worker 출력에 액세스하고 이를 최종 출력으로 합성할 수 있습니다. 아래 예제는 section 목록을 반복하고 Send API를 사용하여 각 worker에게 section을 전송합니다.
Evaluator-optimizer
Evaluator-optimizer workflow에서는 하나의 LLM 호출이 응답을 생성하고 다른 호출이 해당 응답을 평가합니다. evaluator 또는 human-in-the-loop가 응답에 개선이 필요하다고 판단하면 피드백이 제공되고 응답이 재생성됩니다. 이 루프는 허용 가능한 응답이 생성될 때까지 계속됩니다. Evaluator-optimizer workflow는 작업에 대한 특정 성공 기준이 있지만 해당 기준을 충족하기 위해 반복이 필요한 경우에 일반적으로 사용됩니다. 예를 들어, 두 언어 간에 텍스트를 번역할 때 항상 완벽하게 일치하는 것은 아닙니다. 두 언어에서 동일한 의미를 가진 번역을 생성하려면 몇 번의 반복이 필요할 수 있습니다.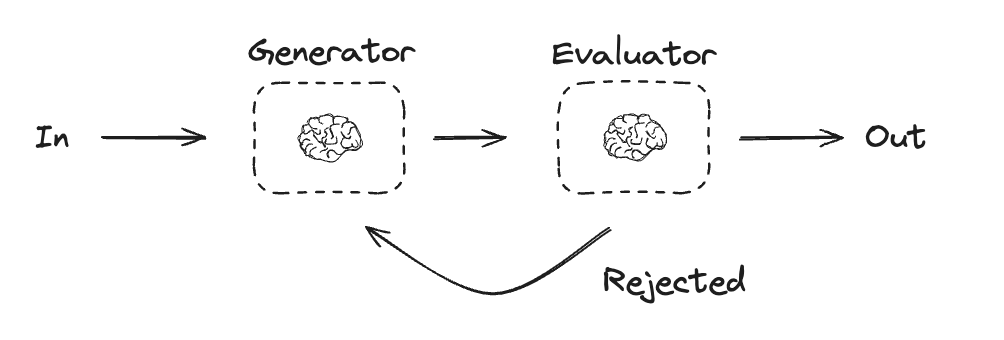
Agent
Agent는 일반적으로 tool을 사용하여 작업을 수행하는 LLM으로 구현됩니다. 연속적인 피드백 루프에서 작동하며, 문제와 솔루션을 예측할 수 없는 상황에서 사용됩니다. Agent는 workflow보다 더 많은 자율성을 가지며, 사용하는 도구와 문제 해결 방법에 대한 결정을 내릴 수 있습니다. 사용 가능한 도구 세트와 agent의 동작 방식에 대한 가이드라인을 여전히 정의할 수 있습니다.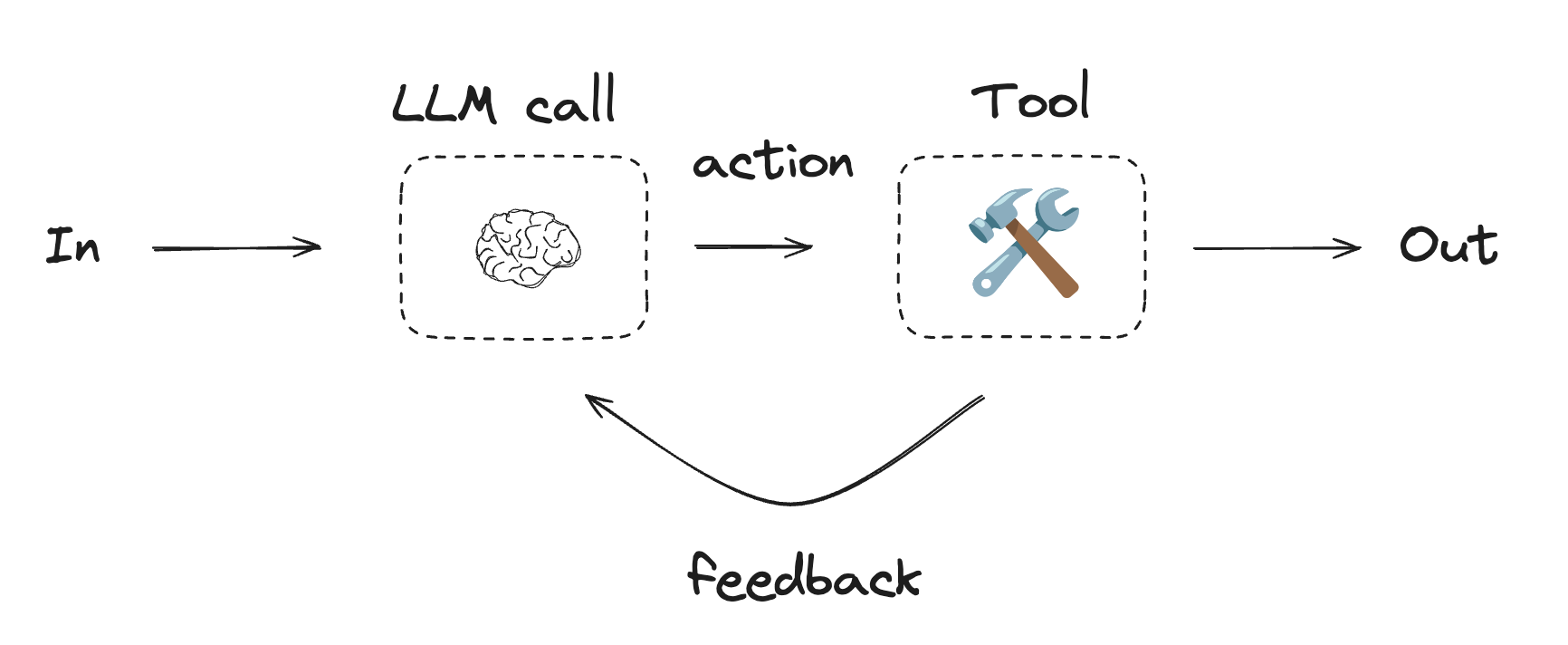
Agent를 시작하려면 quickstart를 참조하거나 LangChain에서 작동 방식에 대해 자세히 읽어보세요.
Using tools
Connect these docs programmatically to Claude, VSCode, and more via MCP for real-time answers.