

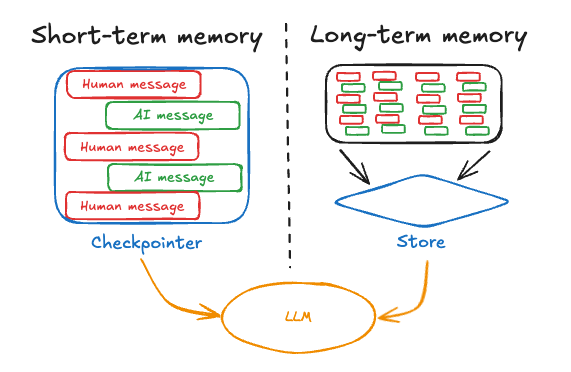
- 단기 메모리, 또는 thread 범위 메모리는 세션 내에서 메시지 기록을 유지하여 진행 중인 대화를 추적합니다. LangGraph는 단기 메모리를 에이전트의 state의 일부로 관리합니다. State는 checkpointer를 사용하여 데이터베이스에 저장되므로 thread는 언제든지 재개될 수 있습니다. 단기 메모리는 graph가 호출되거나 단계가 완료될 때 업데이트되며, State는 각 단계의 시작 시 읽힙니다.
- 장기 메모리는 세션 간에 사용자별 또는 애플리케이션 수준 데이터를 저장하며 대화 thread 간에 공유됩니다. 언제든지 그리고 모든 thread에서 회상될 수 있습니다. 메모리는 단일 thread ID 내에서만이 아니라 모든 사용자 정의 namespace로 범위가 지정됩니다. LangGraph는 장기 메모리를 저장하고 회상할 수 있도록 stores (참조 문서)를 제공합니다.
단기 메모리
단기 메모리는 애플리케이션이 단일 thread 또는 대화 내에서 이전 상호작용을 기억할 수 있게 해줍니다. Thread는 이메일이 단일 대화에서 메시지를 그룹화하는 방식과 유사하게 세션에서 여러 상호작용을 구성합니다. LangGraph는 단기 메모리를 thread 범위 checkpoint를 통해 저장되는 에이전트 state의 일부로 관리합니다. 이 state는 일반적으로 업로드된 파일, 검색된 문서 또는 생성된 아티팩트와 같은 다른 상태 데이터와 함께 대화 기록을 포함할 수 있습니다. 이를 graph의 state에 저장함으로써, 봇은 서로 다른 thread 간의 분리를 유지하면서 주어진 대화에 대한 전체 컨텍스트에 액세스할 수 있습니다.단기 메모리 관리
대화 기록은 단기 메모리의 가장 일반적인 형태이며, 긴 대화는 오늘날의 LLM에게 도전 과제를 제시합니다. 전체 기록이 LLM의 context window에 맞지 않을 수 있으며, 이는 복구할 수 없는 오류를 초래합니다. LLM이 전체 context 길이를 지원하더라도, 대부분의 LLM은 여전히 긴 context에서 성능이 저하됩니다. 오래되거나 주제에서 벗어난 콘텐츠에 “산만해지며”, 응답 시간이 느려지고 비용이 증가합니다. Chat model은 개발자가 제공한 지침(system message)과 사용자 입력(human message)을 포함하는 message를 사용하여 context를 받습니다. 채팅 애플리케이션에서 message는 사람의 입력과 모델 응답 사이를 번갈아 가며, 시간이 지남에 따라 점점 길어지는 message 목록이 생성됩니다. context window가 제한되어 있고 토큰이 많은 message 목록은 비용이 많이 들 수 있기 때문에, 많은 애플리케이션은 오래된 정보를 수동으로 제거하거나 잊어버리는 기술을 사용하는 것이 유익할 수 있습니다.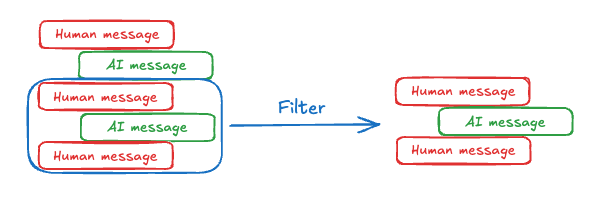 message 관리를 위한 일반적인 기술에 대한 자세한 내용은 메모리 추가 및 관리 가이드를 참조하세요.
message 관리를 위한 일반적인 기술에 대한 자세한 내용은 메모리 추가 및 관리 가이드를 참조하세요.
장기 메모리
LangGraph의 장기 메모리는 시스템이 서로 다른 대화나 세션 간에 정보를 유지할 수 있게 해줍니다. thread 범위인 단기 메모리와 달리, 장기 메모리는 사용자 정의 “namespace” 내에 저장됩니다. 장기 메모리는 만능 솔루션이 없는 복잡한 과제입니다. 그러나 다음 질문들은 다양한 기술을 탐색하는 데 도움이 되는 프레임워크를 제공합니다:- 메모리의 유형은 무엇인가요? 인간은 사실(의미 메모리), 경험(일화 메모리), 규칙(절차 메모리)을 기억하기 위해 메모리를 사용합니다. AI 에이전트도 같은 방식으로 메모리를 사용할 수 있습니다. 예를 들어, AI 에이전트는 작업을 수행하기 위해 사용자에 대한 특정 사실을 기억하기 위해 메모리를 사용할 수 있습니다.
- 언제 메모리를 업데이트하고 싶으신가요? 메모리는 에이전트의 애플리케이션 로직의 일부로 업데이트될 수 있습니다(예: “hot path에서”). 이 경우 에이전트는 일반적으로 사용자에게 응답하기 전에 사실을 기억하기로 결정합니다. 또는 메모리는 백그라운드 작업(백그라운드에서 비동기적으로 실행되고 메모리를 생성하는 로직)으로 업데이트될 수 있습니다. 아래 섹션에서 이러한 접근 방식 간의 트레이드오프를 설명합니다.
메모리 유형
다양한 애플리케이션은 다양한 유형의 메모리를 필요로 합니다. 비유가 완벽하지는 않지만, 인간 메모리 유형을 살펴보는 것은 통찰력을 제공할 수 있습니다. 일부 연구(예: CoALA 논문)는 이러한 인간 메모리 유형을 AI 에이전트에서 사용되는 것과 매핑하기도 했습니다.| 메모리 유형 | 저장되는 것 | 인간의 예 | 에이전트의 예 |
|---|---|---|---|
| 의미 | 사실 | 학교에서 배운 것들 | 사용자에 대한 사실 |
| 일화 | 경험 | 내가 한 일들 | 과거 에이전트 행동 |
| 절차 | 지침 | 본능 또는 운동 기술 | 에이전트 system prompt |
의미 메모리
의미 메모리는 인간과 AI 에이전트 모두에서 특정 사실과 개념의 보유를 포함합니다. 인간의 경우, 학교에서 배운 정보와 개념 및 그 관계에 대한 이해를 포함할 수 있습니다. AI 에이전트의 경우, 의미 메모리는 과거 상호작용에서 사실이나 개념을 기억하여 애플리케이션을 개인화하는 데 자주 사용됩니다.의미 메모리는 “의미 검색(semantic search)“과 다릅니다. 의미 검색은 “의미”(일반적으로 embedding으로)를 사용하여 유사한 콘텐츠를 찾는 기술입니다. 의미 메모리는 심리학의 용어로 사실과 지식을 저장하는 것을 의미하는 반면, 의미 검색은 정확한 일치가 아닌 의미를 기반으로 정보를 검색하는 방법입니다.
Profile
의미 메모리는 다양한 방식으로 관리될 수 있습니다. 예를 들어, 메모리는 사용자, 조직 또는 기타 엔티티(에이전트 자체 포함)에 대한 범위가 명확하고 구체적인 정보의 단일하고 지속적으로 업데이트되는 “profile”일 수 있습니다. profile은 일반적으로 도메인을 나타내기 위해 선택한 다양한 key-value 쌍이 있는 JSON 문서입니다. profile을 기억할 때, 매번 profile을 업데이트하고 있는지 확인해야 합니다. 결과적으로, 이전 profile을 전달하고 모델에게 새 profile을 생성하도록 요청하거나 (또는 이전 profile에 적용할 JSON patch를) 원할 것입니다. 이는 profile이 커질수록 오류가 발생하기 쉬워질 수 있으며, profile을 여러 문서로 분할하거나 메모리 스키마가 유효하게 유지되도록 문서를 생성할 때 strict 디코딩을 사용하는 것이 도움이 될 수 있습니다.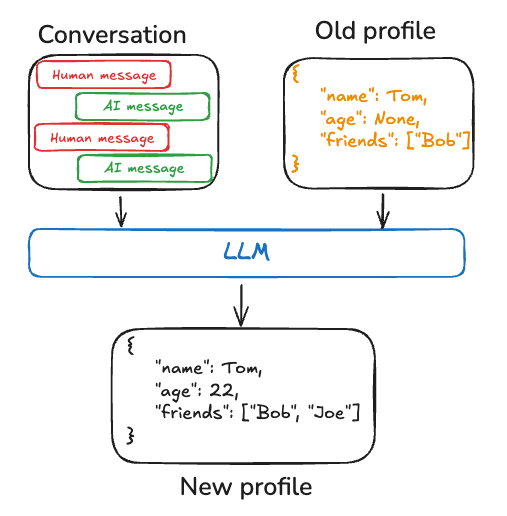
Collection
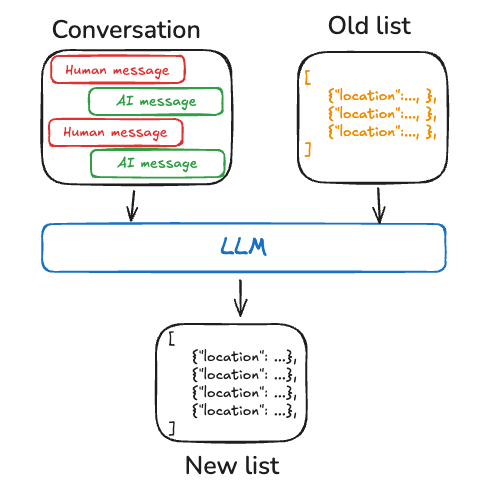
또는 메모리는 시간이 지남에 따라 지속적으로 업데이트되고 확장되는 문서 컬렉션일 수 있습니다. 각 개별 메모리는 더 좁은 범위로 지정될 수 있고 생성하기가 더 쉬우므로, 시간이 지남에 따라 정보를 잃을 가능성이 적습니다. LLM이 새로운 정보를 기존 profile과 조정하는 것보다 새로운 정보에 대한 새로운 객체를 생성하는 것이 더 쉽습니다. 결과적으로, 문서 컬렉션은 다운스트림에서 더 높은 recall로 이어지는 경향이 있습니다. 그러나 이는 메모리 업데이트에 일부 복잡성을 이동시킵니다. 이제 모델은 목록의 기존 항목을 _삭제_하거나 _업데이트_해야 하며, 이는 까다로울 수 있습니다. 또한 일부 모델은 과도하게 삽입하는 것을 기본으로 하고 다른 모델은 과도하게 업데이트하는 것을 기본으로 할 수 있습니다. 이를 관리하는 한 가지 방법은 Trustcall 패키지를 참조하고, 동작을 조정하는 데 도움이 되도록 평가(LangSmith와 같은 도구 사용)를 고려하세요. 문서 컬렉션으로 작업하는 것은 목록에 대한 메모리 검색에도 복잡성을 이동시킵니다.Store는 현재 의미 검색과 콘텐츠별 필터링을 모두 지원합니다.
마지막으로, 메모리 컬렉션을 사용하면 모델에 포괄적인 context를 제공하는 것이 어려울 수 있습니다. 개별 메모리가 특정 스키마를 따를 수 있지만, 이 구조는 메모리 간의 전체 context나 관계를 포착하지 못할 수 있습니다. 결과적으로, 이러한 메모리를 사용하여 응답을 생성할 때, 모델은 통합된 profile 접근 방식에서 더 쉽게 사용할 수 있는 중요한 context 정보가 부족할 수 있습니다.
 메모리 관리 접근 방식에 관계없이, 핵심은 에이전트가 의미 메모리를 사용하여 응답을 근거로 삼는다는 것이며, 이는 종종 더 개인화되고 관련성 있는 상호작용으로 이어집니다.
메모리 관리 접근 방식에 관계없이, 핵심은 에이전트가 의미 메모리를 사용하여 응답을 근거로 삼는다는 것이며, 이는 종종 더 개인화되고 관련성 있는 상호작용으로 이어집니다.
일화 메모리
일화 메모리는 인간과 AI 에이전트 모두에서 과거 사건이나 행동을 회상하는 것을 포함합니다. CoALA 논문은 이를 잘 설명합니다: 사실은 의미 메모리에 기록될 수 있는 반면, 경험은 일화 메모리에 기록될 수 있습니다. AI 에이전트의 경우, 일화 메모리는 에이전트가 작업을 수행하는 방법을 기억하는 데 자주 사용됩니다. 실제로, 일화 메모리는 종종 few-shot 예제 prompting을 통해 구현되며, 에이전트는 과거 시퀀스로부터 학습하여 작업을 올바르게 수행합니다. 때로는 “말하는” 것보다 “보여주는” 것이 더 쉽고 LLM은 예제로부터 잘 학습합니다. Few-shot 학습을 통해 의도된 동작을 설명하기 위해 입력-출력 예제로 prompt를 업데이트하여 LLM을 “프로그래밍”할 수 있습니다. few-shot 예제를 생성하기 위해 다양한 모범 사례를 사용할 수 있지만, 종종 과제는 사용자 입력을 기반으로 가장 관련성 있는 예제를 선택하는 데 있습니다. 메모리 store는 데이터를 few-shot 예제로 저장하는 한 가지 방법일 뿐입니다. 더 많은 개발자 참여를 원하거나 few-shot을 평가 하네스와 더 밀접하게 연결하려면 LangSmith Dataset을 사용하여 데이터를 저장할 수도 있습니다. 그런 다음 동적 few-shot 예제 선택기를 즉시 사용하여 동일한 목표를 달성할 수 있습니다. LangSmith는 데이터셋을 인덱싱하고 키워드 유사성을 기반으로 사용자 입력과 가장 관련성 있는 few-shot 예제를 검색할 수 있게 해줍니다(키워드 기반 유사성을 위한 BM25 유사 알고리즘 사용). LangSmith에서 동적 few-shot 예제 선택의 사용 예는 이 how-to 비디오를 참조하세요. 또한 tool calling 성능을 향상시키기 위한 few-shot prompting을 보여주는 이 블로그 포스트와 LLM을 인간 선호도에 맞추기 위해 few-shot 예제를 사용하는 이 블로그 포스트를 참조하세요.절차 메모리
절차 메모리는 인간과 AI 에이전트 모두에서 작업을 수행하는 데 사용되는 규칙을 기억하는 것을 포함합니다. 인간의 경우, 절차 메모리는 기본적인 운동 기술과 균형을 통해 자전거를 타는 것과 같은 작업을 수행하는 방법에 대한 내재화된 지식과 같습니다. 반면에 일화 메모리는 보조 바퀴 없이 자전거를 성공적으로 탄 첫 경험이나 경치 좋은 길을 따라 한 기억에 남는 자전거 타기와 같은 특정 경험을 회상하는 것을 포함합니다. AI 에이전트의 경우, 절차 메모리는 에이전트의 기능을 집합적으로 결정하는 모델 가중치, 에이전트 코드 및 에이전트의 prompt의 조합입니다. 실제로, 에이전트가 모델 가중치를 수정하거나 코드를 다시 작성하는 것은 상당히 드뭅니다. 그러나 에이전트가 자신의 prompt를 수정하는 것은 더 일반적입니다. 에이전트의 지침을 개선하는 효과적인 접근 방식 중 하나는 “Reflection” 또는 메타 prompting입니다. 이는 에이전트에게 현재 지침(예: system prompt)과 최근 대화 또는 명시적인 사용자 피드백을 함께 prompting하는 것을 포함합니다. 그런 다음 에이전트는 이 입력을 기반으로 자신의 지침을 개선합니다. 이 방법은 지침을 미리 지정하기 어려운 작업에 특히 유용하며, 에이전트가 상호작용으로부터 학습하고 적응할 수 있게 해줍니다. 예를 들어, 우리는 외부 피드백과 prompt 재작성을 사용하여 Twitter용 고품질 논문 요약을 생성하는 Tweet 생성기를 구축했습니다. 이 경우, 특정 요약 prompt를 사전에 지정하기는 어려웠지만, 사용자가 생성된 Tweet을 비평하고 요약 프로세스를 개선하는 방법에 대한 피드백을 제공하는 것은 상당히 쉬웠습니다. 아래 의사 코드는 LangGraph 메모리 store를 사용하여 이를 구현하는 방법을 보여줍니다. store를 사용하여 prompt를 저장하고,update_instructions node가 현재 prompt(및 state["messages"]에 캡처된 사용자와의 대화에서 피드백)를 가져오고, prompt를 업데이트하고, 새 prompt를 store에 다시 저장합니다. 그런 다음 call_model이 store에서 업데이트된 prompt를 가져와 응답을 생성하는 데 사용합니다.
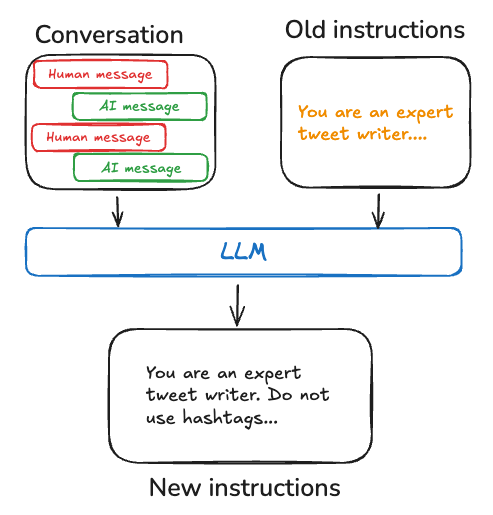
메모리 작성
에이전트가 메모리를 작성하는 두 가지 주요 방법이 있습니다: “hot path에서”와 “백그라운드에서”.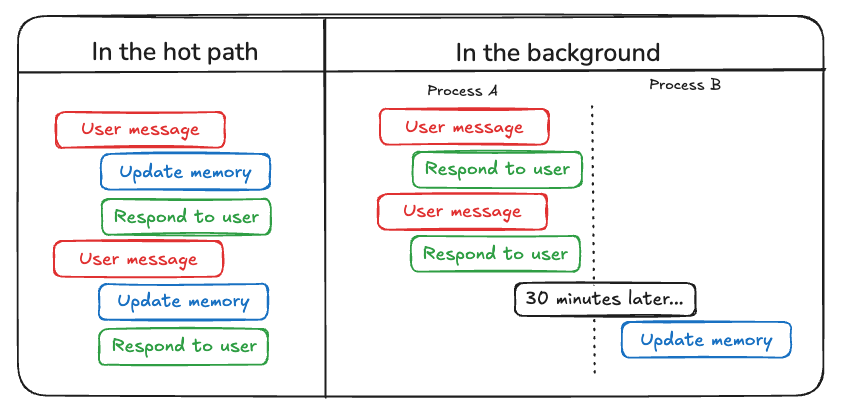
Hot path에서
런타임 중에 메모리를 생성하는 것은 장점과 과제를 모두 제공합니다. 긍정적인 측면에서, 이 접근 방식은 실시간 업데이트를 허용하여 새로운 메모리를 후속 상호작용에서 즉시 사용할 수 있게 합니다. 또한 투명성을 가능하게 하여, 메모리가 생성되고 저장될 때 사용자에게 알릴 수 있습니다. 그러나 이 방법은 과제도 제시합니다. 에이전트가 메모리에 커밋할 내용을 결정하기 위해 새로운 tool이 필요한 경우 복잡성이 증가할 수 있습니다. 또한 메모리에 저장할 내용에 대해 추론하는 프로세스가 에이전트 지연 시간에 영향을 미칠 수 있습니다. 마지막으로, 에이전트는 메모리 생성과 다른 책임 사이에서 멀티태스킹을 해야 하므로, 생성되는 메모리의 양과 품질에 영향을 미칠 수 있습니다. 예를 들어, ChatGPT는 save_memories tool을 사용하여 메모리를 콘텐츠 문자열로 upsert하며, 각 사용자 메시지마다 이 tool을 사용할지 여부와 방법을 결정합니다. 참조 구현으로 memory-agent 템플릿을 참조하세요.백그라운드에서
별도의 백그라운드 작업으로 메모리를 생성하는 것은 여러 가지 장점을 제공합니다. 주 애플리케이션의 지연 시간을 제거하고, 애플리케이션 로직을 메모리 관리와 분리하며, 에이전트가 더 집중된 작업 완료를 할 수 있게 합니다. 이 접근 방식은 또한 중복 작업을 피하기 위해 메모리 생성 시기를 조정하는 유연성을 제공합니다. 그러나 이 방법에는 고유한 과제가 있습니다. 메모리 작성 빈도를 결정하는 것이 중요해지며, 업데이트가 드물면 다른 thread가 새로운 context 없이 남을 수 있습니다. 메모리 형성을 트리거할 시기를 결정하는 것도 중요합니다. 일반적인 전략에는 설정된 기간 후 스케줄링(새 이벤트가 발생하면 재스케줄링), cron 스케줄 사용 또는 사용자나 애플리케이션 로직에 의한 수동 트리거 허용이 포함됩니다. 참조 구현으로 memory-service 템플릿을 참조하세요.메모리 저장
LangGraph는 장기 메모리를 store에 JSON 문서로 저장합니다. 각 메모리는 사용자 정의namespace(폴더와 유사) 및 고유한 key(파일 이름과 유사) 아래에 구성됩니다. Namespace는 종종 사용자 또는 조직 ID 또는 정보를 구성하기 쉽게 만드는 기타 레이블을 포함합니다. 이 구조는 메모리의 계층적 구성을 가능하게 합니다. 그런 다음 콘텐츠 필터를 통해 namespace 간 검색이 지원됩니다.
Connect these docs programmatically to Claude, VSCode, and more via MCP for real-time answers.