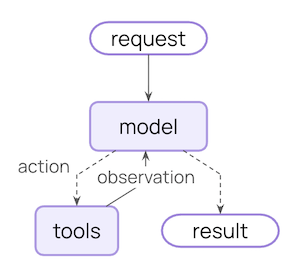
Middleware는 에이전트 내부에서 일어나는 일을 더 세밀하게 제어할 수 있는 방법을 제공합니다.
핵심 에이전트 루프는 모델을 호출하고, 실행할 도구를 선택하게 한 다음, 더 이상 도구를 호출하지 않을 때 종료하는 과정을 포함합니다:
Middleware는 각 단계의 전후에 훅을 노출합니다:
Middleware로 무엇을 할 수 있나요?
모니터링 로깅, 분석 및 디버깅으로 에이전트 동작을 추적하세요
수정 프롬프트, 도구 선택 및 출력 형식을 변환하세요
제어 재시도, 폴백 및 조기 종료 로직을 추가하세요
강제 속도 제한, 가드레일 및 PII 탐지를 적용하세요
create_agentfrom langchain.agents import create_agent from langchain.agents.middleware import SummarizationMiddleware, HumanInTheLoopMiddleware agent = create_agent( model = "openai:gpt-4o" , tools = [ ... ], middleware = [SummarizationMiddleware(), HumanInTheLoopMiddleware()], ) 내장 middleware LangChain은 일반적인 사용 사례를 위한 사전 구축된 middleware를 제공합니다:
토큰 제한에 도달할 때 대화 기록을 자동으로 요약합니다.
다음에 완벽합니다:
컨텍스트 윈도우를 초과하는 장기 실행 대화
광범위한 기록이 있는 다중 턴 대화
전체 대화 컨텍스트 보존이 중요한 애플리케이션
from langchain.agents import create_agent from langchain.agents.middleware import SummarizationMiddleware agent = create_agent( model = "openai:gpt-4o" , tools = [weather_tool, calculator_tool], middleware = [ SummarizationMiddleware( model = "openai:gpt-4o-mini" , max_tokens_before_summary = 4000 , # Trigger summarization at 4000 tokens messages_to_keep = 20 , # Keep last 20 messages after summary summary_prompt = "Custom prompt for summarization..." , # Optional ), ], )
max_tokens_before_summary
요약을 트리거하는 토큰 임계값
커스텀 토큰 카운팅 함수. 기본값은 문자 기반 카운팅입니다.
커스텀 프롬프트 템플릿. 지정하지 않으면 내장 템플릿을 사용합니다.
summary_prefix
string
default: "## Previous conversation summary:"
요약 메시지의 접두사
Human-in-the-loop 도구 호출이 실행되기 전에 사람의 승인, 편집 또는 거부를 위해 에이전트 실행을 일시 중지합니다.
다음에 완벽합니다:
사람의 승인이 필요한 고위험 작업 (데이터베이스 쓰기, 금융 거래)
사람의 감독이 필수인 규정 준수 워크플로우
사람의 피드백이 에이전트를 안내하는 데 사용되는 장기 실행 대화
from langchain.agents import create_agent from langchain.agents.middleware import HumanInTheLoopMiddleware from langgraph.checkpoint.memory import InMemorySaver agent = create_agent( model = "openai:gpt-4o" , tools = [read_email_tool, send_email_tool], checkpointer = InMemorySaver(), middleware = [ HumanInTheLoopMiddleware( interrupt_on = { # Require approval, editing, or rejection for sending emails "send_email_tool" : { "allowed_decisions" : [ "approve" , "edit" , "reject" ], }, # Auto-approve reading emails "read_email_tool" : False , } ), ], )
도구 이름과 승인 구성의 매핑. 값은 True (기본 구성으로 중단), False (자동 승인) 또는 InterruptOnConfig 객체일 수 있습니다.
description_prefix
string
default: "Tool execution requires approval"
작업 요청 설명의 접두사
InterruptOnConfig 옵션:허용된 결정 목록: "approve", "edit" 또는 "reject"
커스텀 설명을 위한 정적 문자열 또는 호출 가능한 함수
Anthropic 프롬프트 캐싱 Anthropic 모델로 반복적인 프롬프트 접두사를 캐싱하여 비용을 절감하세요.
다음에 완벽합니다:
길고 반복되는 시스템 프롬프트가 있는 애플리케이션
호출 간에 동일한 컨텍스트를 재사용하는 에이전트
대량 배포의 API 비용 절감
from langchain_anthropic import ChatAnthropic from langchain_anthropic.middleware import AnthropicPromptCachingMiddleware from langchain.agents import create_agent LONG_PROMPT = """ Please be a helpful assistant. <Lots more context ...> """ agent = create_agent( model = ChatAnthropic( model = "claude-sonnet-4-latest" ), system_prompt = LONG_PROMPT , middleware = [AnthropicPromptCachingMiddleware( ttl = "5m" )], ) # cache store agent.invoke({ "messages" : [HumanMessage( "Hi, my name is Bob" )]}) # cache hit, system prompt is cached agent.invoke({ "messages" : [HumanMessage( "What's my name?" )]})
type
string
default: "ephemeral"
캐시 유형. 현재 "ephemeral"만 지원됩니다.
캐시된 콘텐츠의 유효 시간. 유효한 값: "5m" 또는 "1h"
unsupported_model_behavior
Anthropic이 아닌 모델 사용 시 동작. 옵션: "ignore", "warn" 또는 "raise"
모델 호출 제한 무한 루프나 과도한 비용을 방지하기 위해 모델 호출 수를 제한합니다.
다음에 완벽합니다:
너무 많은 API 호출을 하는 폭주 에이전트 방지
프로덕션 배포에 대한 비용 제어 강제
특정 호출 예산 내에서 에이전트 동작 테스트
from langchain.agents import create_agent from langchain.agents.middleware import ModelCallLimitMiddleware agent = create_agent( model = "openai:gpt-4o" , tools = [ ... ], middleware = [ ModelCallLimitMiddleware( thread_limit = 10 , # Max 10 calls per thread (across runs) run_limit = 5 , # Max 5 calls per run (single invocation) exit_behavior = "end" , # Or "error" to raise exception ), ], )
스레드의 모든 실행에 걸친 최대 모델 호출 수. 기본값은 제한 없음입니다.
단일 호출당 최대 모델 호출 수. 기본값은 제한 없음입니다.
제한에 도달했을 때의 동작. 옵션: "end" (정상 종료) 또는 "error" (예외 발생)
도구 호출 제한 특정 도구 또는 모든 도구에 대한 도구 호출 수를 제한합니다.
다음에 완벽합니다:
비용이 많이 드는 외부 API에 대한 과도한 호출 방지
웹 검색 또는 데이터베이스 쿼리 제한
특정 도구 사용에 대한 속도 제한 강제
from langchain.agents import create_agent from langchain.agents.middleware import ToolCallLimitMiddleware # Limit all tool calls global_limiter = ToolCallLimitMiddleware( thread_limit = 20 , run_limit = 10 ) # Limit specific tool search_limiter = ToolCallLimitMiddleware( tool_name = "search" , thread_limit = 5 , run_limit = 3 , ) agent = create_agent( model = "openai:gpt-4o" , tools = [ ... ], middleware = [global_limiter, search_limiter], )
제한할 특정 도구. 제공하지 않으면 모든 도구에 제한이 적용됩니다.
스레드의 모든 실행에 걸친 최대 도구 호출 수. 기본값은 제한 없음입니다.
단일 호출당 최대 도구 호출 수. 기본값은 제한 없음입니다.
제한에 도달했을 때의 동작. 옵션: "end" (정상 종료) 또는 "error" (예외 발생)
모델 폴백 기본 모델이 실패할 때 대체 모델로 자동 폴백합니다.
다음에 완벽합니다:
모델 중단을 처리하는 탄력적인 에이전트 구축
더 저렴한 모델로 폴백하여 비용 최적화
OpenAI, Anthropic 등에 걸친 제공자 중복성
from langchain.agents import create_agent from langchain.agents.middleware import ModelFallbackMiddleware agent = create_agent( model = "openai:gpt-4o" , # Primary model tools = [ ... ], middleware = [ ModelFallbackMiddleware( "openai:gpt-4o-mini" , # Try first on error "anthropic:claude-3-5-sonnet-20241022" , # Then this ), ], )
first_model
string | BaseChatModel
required
기본 모델이 실패할 때 시도할 첫 번째 폴백 모델. 모델 문자열 (예: "openai:gpt-4o-mini") 또는 BaseChatModel 인스턴스일 수 있습니다.
이전 모델이 실패할 경우 순서대로 시도할 추가 폴백 모델
PII 탐지 대화에서 개인 식별 정보를 탐지하고 처리합니다.
다음에 완벽합니다:
규정 준수 요구 사항이 있는 의료 및 금융 애플리케이션
로그를 정제해야 하는 고객 서비스 에이전트
민감한 사용자 데이터를 처리하는 모든 애플리케이션
from langchain.agents import create_agent from langchain.agents.middleware import PIIMiddleware agent = create_agent( model = "openai:gpt-4o" , tools = [ ... ], middleware = [ # Redact emails in user input PIIMiddleware( "email" , strategy = "redact" , apply_to_input = True ), # Mask credit cards (show last 4 digits) PIIMiddleware( "credit_card" , strategy = "mask" , apply_to_input = True ), # Custom PII type with regex PIIMiddleware( "api_key" , detector = r "sk- [ a-zA-Z0-9 ] {32} " , strategy = "block" , # Raise error if detected ), ], )
탐지할 PII 유형. 내장 유형 (email, credit_card, ip, mac_address, url) 또는 커스텀 유형 이름일 수 있습니다.
탐지된 PII를 처리하는 방법. 옵션:
"block" - 탐지 시 예외 발생"redact" - [REDACTED_TYPE]으로 대체"mask" - 부분 마스킹 (예: ****-****-****-1234)"hash" - 결정론적 해시로 대체 커스텀 탐지기 함수 또는 정규식 패턴. 제공하지 않으면 PII 유형에 대한 내장 탐지기를 사용합니다.
복잡한 다단계 작업을 위한 할 일 목록 관리 기능을 추가합니다.
이 middleware는 에이전트에 write_todos 도구와 효과적인 작업 계획을 안내하는 시스템 프롬프트를 자동으로 제공합니다.
from langchain.agents import create_agent from langchain.agents.middleware import TodoListMiddleware from langchain.messages import HumanMessage agent = create_agent( model = "openai:gpt-4o" , tools = [ ... ], middleware = [TodoListMiddleware()], ) result = agent.invoke({ "messages" : [HumanMessage( "Help me refactor my codebase" )]}) print (result[ "todos" ]) # Array of todo items with status tracking
할 일 사용을 안내하는 커스텀 시스템 프롬프트. 지정하지 않으면 내장 프롬프트를 사용합니다.
write_todos 도구에 대한 커스텀 설명. 지정하지 않으면 내장 설명을 사용합니다.
LLM 도구 선택기 LLM을 사용하여 메인 모델을 호출하기 전에 관련 도구를 지능적으로 선택합니다.
다음에 완벽합니다:
많은 도구(10개 이상)가 있지만 쿼리당 대부분이 관련 없는 에이전트
관련 없는 도구를 필터링하여 토큰 사용량 감소
모델 집중도 및 정확도 향상
from langchain.agents import create_agent from langchain.agents.middleware import LLMToolSelectorMiddleware agent = create_agent( model = "openai:gpt-4o" , tools = [tool1, tool2, tool3, tool4, tool5, ... ], # Many tools middleware = [ LLMToolSelectorMiddleware( model = "openai:gpt-4o-mini" , # Use cheaper model for selection max_tools = 3 , # Limit to 3 most relevant tools always_include = [ "search" ], # Always include certain tools ), ], )
도구 선택을 위한 모델. 모델 문자열 또는 BaseChatModel 인스턴스일 수 있습니다. 기본값은 에이전트의 메인 모델입니다.
선택 모델에 대한 지침. 지정하지 않으면 내장 프롬프트를 사용합니다.
선택할 최대 도구 수. 기본값은 제한 없음입니다.
도구 재시도 구성 가능한 지수 백오프로 실패한 도구 호출을 자동으로 재시도합니다.
다음에 완벽합니다:
외부 API 호출의 일시적 실패 처리
네트워크 종속 도구의 안정성 향상
일시적 오류를 우아하게 처리하는 탄력적인 에이전트 구축
from langchain.agents import create_agent from langchain.agents.middleware import ToolRetryMiddleware agent = create_agent( model = "openai:gpt-4o" , tools = [search_tool, database_tool], middleware = [ ToolRetryMiddleware( max_retries = 3 , # Retry up to 3 times backoff_factor = 2.0 , # Exponential backoff multiplier initial_delay = 1.0 , # Start with 1 second delay max_delay = 60.0 , # Cap delays at 60 seconds jitter = True , # Add random jitter to avoid thundering herd ), ], )
초기 호출 후 최대 재시도 횟수 (기본값으로 총 3회 시도)
재시도 로직을 적용할 도구 또는 도구 이름의 선택적 목록. None이면 모든 도구에 적용됩니다.
retry_on
tuple[type[Exception], ...] | callable
default: "(Exception,)"
재시도할 예외 유형의 튜플 또는 예외를 받아 재시도해야 하면 True를 반환하는 호출 가능 객체입니다.
on_failure
string | callable
default: "return_message"
모든 재시도가 소진되었을 때의 동작. 옵션:
"return_message" - 오류 세부 정보가 포함된 ToolMessage 반환 (LLM이 실패를 처리하도록 허용)"raise" - 예외 재발생 (에이전트 실행 중지)커스텀 호출 가능 - 예외를 받아 ToolMessage 콘텐츠에 대한 문자열을 반환하는 함수
지수 백오프의 승수. 각 재시도는 initial_delay * (backoff_factor ** retry_number) 초를 대기합니다. 일정한 지연을 위해 0.0으로 설정하세요.
재시도 간 최대 지연 시간(초) (지수 백오프 증가 제한)
thundering herd를 피하기 위해 지연에 무작위 지터(±25%)를 추가할지 여부
LLM 도구 에뮬레이터 테스트 목적으로 LLM을 사용하여 도구 실행을 에뮬레이트하고, 실제 도구 호출을 AI 생성 응답으로 대체합니다.
다음에 완벽합니다:
실제 도구를 실행하지 않고 에이전트 동작 테스트
외부 도구를 사용할 수 없거나 비용이 많이 들 때 에이전트 개발
실제 도구를 구현하기 전에 에이전트 워크플로우 프로토타이핑
from langchain.agents import create_agent from langchain.agents.middleware import LLMToolEmulator agent = create_agent( model = "openai:gpt-4o" , tools = [get_weather, search_database, send_email], middleware = [ # Emulate all tools by default LLMToolEmulator(), # Or emulate specific tools # LLMToolEmulator(tools=["get_weather", "search_database"]), # Or use a custom model for emulation # LLMToolEmulator(model="anthropic:claude-3-5-sonnet-latest"), ], )
에뮬레이트할 도구 이름(str) 또는 BaseTool 인스턴스 목록. None (기본값)이면 모든 도구가 에뮬레이트됩니다. 빈 목록이면 도구가 에뮬레이트되지 않습니다.
model
string | BaseChatModel
default: "anthropic:claude-3-5-sonnet-latest"
에뮬레이트된 도구 응답 생성에 사용할 모델. 모델 식별자 문자열 또는 BaseChatModel 인스턴스일 수 있습니다.
컨텍스트 편집 도구 사용을 트리밍, 요약 또는 지워서 대화 컨텍스트를 관리합니다.
다음에 완벽합니다:
주기적인 컨텍스트 정리가 필요한 긴 대화
컨텍스트에서 실패한 도구 시도 제거
커스텀 컨텍스트 관리 전략
from langchain.agents import create_agent from langchain.agents.middleware import ContextEditingMiddleware, ClearToolUsesEdit agent = create_agent( model = "openai:gpt-4o" , tools = [ ... ], middleware = [ ContextEditingMiddleware( edits = [ ClearToolUsesEdit( max_tokens = 1000 ), # Clear old tool uses ], ), ], )
edits
list[ContextEdit]
default: "[ClearToolUsesEdit()]"
적용할 ContextEdit 전략 목록
token_count_method
string
default: "approximate"
토큰 카운팅 방법. 옵션: "approximate" 또는 "model"
ClearToolUsesEditplaceholder
string
default: "[cleared]"
지워진 출력에 대한 플레이스홀더 텍스트
커스텀 middleware 에이전트 실행 흐름의 특정 지점에서 실행되는 훅을 구현하여 커스텀 middleware를 구축하세요.
두 가지 방법으로 middleware를 만들 수 있습니다:
데코레이터 기반 - 단일 훅 middleware를 위한 빠르고 간단한 방법클래스 기반 - 여러 훅이 있는 복잡한 middleware를 위한 더 강력한 방법
데코레이터 기반 middleware 단일 훅만 필요한 간단한 middleware의 경우, 데코레이터가 기능을 추가하는 가장 빠른 방법을 제공합니다:
from langchain.agents.middleware import before_model, after_model, wrap_model_call from langchain.agents.middleware import AgentState, ModelRequest, ModelResponse, dynamic_prompt from langchain.messages import AIMessage from langchain.agents import create_agent from langgraph.runtime import Runtime from typing import Any, Callable # Node-style: logging before model calls @before_model def log_before_model ( state : AgentState, runtime : Runtime) -> dict[ str , Any] | None : print ( f "About to call model with { len (state[ 'messages' ]) } messages" ) return None # Node-style: validation after model calls @after_model ( can_jump_to = [ "end" ]) def validate_output ( state : AgentState, runtime : Runtime) -> dict[ str , Any] | None : last_message = state[ "messages" ][ - 1 ] if "BLOCKED" in last_message.content: return { "messages" : [AIMessage( "I cannot respond to that request." )], "jump_to" : "end" } return None # Wrap-style: retry logic @wrap_model_call def retry_model ( request : ModelRequest, handler : Callable[[ModelRequest], ModelResponse], ) -> ModelResponse: for attempt in range ( 3 ): try : return handler(request) except Exception as e: if attempt == 2 : raise print ( f "Retry { attempt + 1 } /3 after error: { e } " ) # Wrap-style: dynamic prompts @dynamic_prompt def personalized_prompt ( request : ModelRequest) -> str : user_id = request.runtime.context.get( "user_id" , "guest" ) return f "You are a helpful assistant for user { user_id } . Be concise and friendly." # Use decorators in agent agent = create_agent( model = "openai:gpt-4o" , middleware = [log_before_model, validate_output, retry_model, personalized_prompt], tools = [ ... ], ) 사용 가능한 데코레이터 Node 스타일 (특정 실행 지점에서 실행):Wrap 스타일 (실행을 가로채고 제어):편의 데코레이터 :데코레이터를 사용할 때
데코레이터 사용 시 • 단일 훅이 필요할 때
클래스 사용 시 • 여러 훅이 필요할 때
클래스 기반 middleware 두 가지 훅 스타일
Node 스타일 훅 특정 실행 지점에서 순차적으로 실행됩니다. 로깅, 검증 및 상태 업데이트에 사용하세요.
Wrap 스타일 훅 핸들러 호출에 대한 완전한 제어로 실행을 가로챕니다. 재시도, 캐싱 및 변환에 사용하세요.
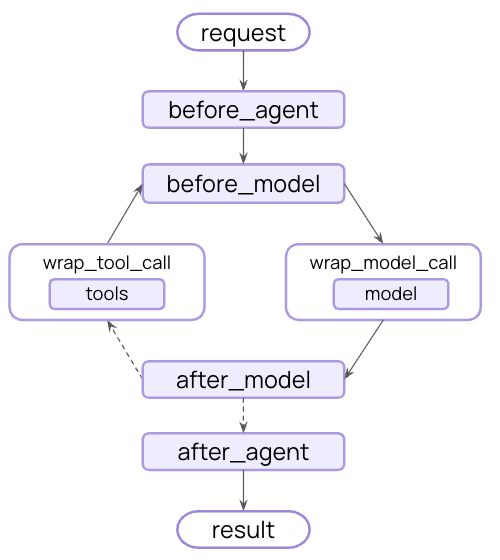
Node 스타일 훅 실행 흐름의 특정 지점에서 실행됩니다:
before_agent - 에이전트 시작 전 (호출당 한 번)before_model - 각 모델 호출 전after_model - 각 모델 응답 후after_agent - 에이전트 완료 후 (호출당 최대 한 번)
예제: 로깅 middleware from langchain.agents.middleware import AgentMiddleware, AgentState from langgraph.runtime import Runtime from typing import Any class LoggingMiddleware ( AgentMiddleware ): def before_model ( self , state : AgentState, runtime : Runtime) -> dict[ str , Any] | None : print ( f "About to call model with { len (state[ 'messages' ]) } messages" ) return None def after_model ( self , state : AgentState, runtime : Runtime) -> dict[ str , Any] | None : print ( f "Model returned: { state[ 'messages' ][ - 1 ].content } " ) return None 예제: 대화 길이 제한 from langchain.agents.middleware import AgentMiddleware, AgentState from langchain.messages import AIMessage from langgraph.runtime import Runtime from typing import Any class MessageLimitMiddleware ( AgentMiddleware ): def __init__ ( self , max_messages : int = 50 ): super (). __init__ () self .max_messages = max_messages def before_model ( self , state : AgentState, runtime : Runtime) -> dict[ str , Any] | None : if len (state[ "messages" ]) == self .max_messages: return { "messages" : [AIMessage( "Conversation limit reached." )], "jump_to" : "end" } return None Wrap 스타일 훅 실행을 가로채고 핸들러가 호출되는 시점을 제어합니다:
wrap_model_call - 각 모델 호출 주위wrap_tool_call - 각 도구 호출 주위
핸들러를 0번 (단락), 1번 (정상 흐름) 또는 여러 번 (재시도 로직) 호출할지 결정합니다.
예제: 모델 재시도 middleware from langchain.agents.middleware import AgentMiddleware, ModelRequest, ModelResponse from typing import Callable class RetryMiddleware ( AgentMiddleware ): def __init__ ( self , max_retries : int = 3 ): super (). __init__ () self .max_retries = max_retries def wrap_model_call ( self , request : ModelRequest, handler : Callable[[ModelRequest], ModelResponse], ) -> ModelResponse: for attempt in range ( self .max_retries): try : return handler(request) except Exception as e: if attempt == self .max_retries - 1 : raise print ( f "Retry { attempt + 1 } / { self .max_retries } after error: { e } " ) 예제: 동적 모델 선택 from langchain.agents.middleware import AgentMiddleware, ModelRequest, ModelResponse from langchain.chat_models import init_chat_model from typing import Callable class DynamicModelMiddleware ( AgentMiddleware ): def wrap_model_call ( self , request : ModelRequest, handler : Callable[[ModelRequest], ModelResponse], ) -> ModelResponse: # Use different model based on conversation length if len (request.messages) > 10 : request.model = init_chat_model( "openai:gpt-4o" ) else : request.model = init_chat_model( "openai:gpt-4o-mini" ) return handler(request) 예제: 도구 호출 모니터링 from langchain.tools.tool_node import ToolCallRequest from langchain.agents.middleware import AgentMiddleware from langchain_core.messages import ToolMessage from langgraph.types import Command from typing import Callable class ToolMonitoringMiddleware ( AgentMiddleware ): def wrap_tool_call ( self , request : ToolCallRequest, handler : Callable[[ToolCallRequest], ToolMessage | Command], ) -> ToolMessage | Command: print ( f "Executing tool: { request.tool_call[ 'name' ] } " ) print ( f "Arguments: { request.tool_call[ 'args' ] } " ) try : result = handler(request) print ( f "Tool completed successfully" ) return result except Exception as e: print ( f "Tool failed: { e } " ) raise 커스텀 상태 스키마 Middleware는 커스텀 속성으로 에이전트의 상태를 확장할 수 있습니다. 커스텀 상태 유형을 정의하고 state_schema로 설정하세요:
from langchain.agents.middleware import AgentState, AgentMiddleware from typing_extensions import NotRequired from typing import Any class CustomState ( AgentState ): model_call_count: NotRequired[ int ] user_id: NotRequired[ str ] class CallCounterMiddleware (AgentMiddleware[CustomState]): state_schema = CustomState def before_model ( self , state : CustomState, runtime ) -> dict[ str , Any] | None : # Access custom state properties count = state.get( "model_call_count" , 0 ) if count > 10 : return { "jump_to" : "end" } return None def after_model ( self , state : CustomState, runtime ) -> dict[ str , Any] | None : # Update custom state return { "model_call_count" : state.get( "model_call_count" , 0 ) + 1 } agent = create_agent( model = "openai:gpt-4o" , middleware = [CallCounterMiddleware()], tools = [ ... ], ) # Invoke with custom state result = agent.invoke({ "messages" : [HumanMessage( "Hello" )], "model_call_count" : 0 , "user_id" : "user-123" , }) 실행 순서 여러 middleware를 사용할 때 실행 순서를 이해하는 것이 중요합니다:
agent = create_agent( model = "openai:gpt-4o" , middleware = [middleware1, middleware2, middleware3], tools = [ ... ], )
Before 훅은 순서대로 실행됩니다:
middleware1.before_agent()middleware2.before_agent()middleware3.before_agent() 에이전트 루프 시작
middleware1.before_model()middleware2.before_model()middleware3.before_model() Wrap 훅은 함수 호출처럼 중첩됩니다:
middleware1.wrap_model_call() → middleware2.wrap_model_call() → middleware3.wrap_model_call() → model After 훅은 역순으로 실행됩니다:
middleware3.after_model()middleware2.after_model()middleware1.after_model() 에이전트 루프 종료
middleware3.after_agent()middleware2.after_agent()middleware1.after_agent() 주요 규칙:
before_* 훅: 처음부터 마지막까지after_* 훅: 마지막부터 처음까지 (역순)wrap_* 훅: 중첩 (첫 번째 middleware가 다른 모든 것을 감쌈)
에이전트 점프 middleware에서 조기 종료하려면 jump_to가 포함된 딕셔너리를 반환하세요:
class EarlyExitMiddleware ( AgentMiddleware ): def before_model ( self , state : AgentState, runtime ) -> dict[ str , Any] | None : # Check some condition if should_exit(state): return { "messages" : [AIMessage( "Exiting early due to condition." )], "jump_to" : "end" } return None 사용 가능한 점프 대상:
"end": 에이전트 실행의 끝으로 점프"tools": tools 노드로 점프"model": model 노드로 점프 (또는 첫 번째 before_model 훅)
중요: before_model 또는 after_model에서 점프할 때, "model"로 점프하면 모든 before_model middleware가 다시 실행됩니다.점프를 활성화하려면 @hook_config(can_jump_to=[...])로 훅을 데코레이트하세요:
from langchain.agents.middleware import AgentMiddleware, hook_config from typing import Any class ConditionalMiddleware ( AgentMiddleware ): @hook_config ( can_jump_to = [ "end" , "tools" ]) def after_model ( self , state : AgentState, runtime ) -> dict[ str , Any] | None : if some_condition(state): return { "jump_to" : "end" } return None 모범 사례
Middleware를 집중적으로 유지 - 각각 한 가지를 잘 수행해야 합니다
오류를 우아하게 처리 - middleware 오류가 에이전트를 충돌시키지 않도록 하세요
적절한 훅 유형 사용 :
순차적 로직을 위한 Node 스타일 (로깅, 검증)
제어 흐름을 위한 Wrap 스타일 (재시도, 폴백, 캐싱)
커스텀 상태 속성을 명확하게 문서화하세요
통합하기 전에 middleware를 독립적으로 단위 테스트하세요
실행 순서 고려 - 중요한 middleware를 목록의 첫 번째에 배치하세요
가능하면 내장 middleware 사용, 바퀴를 재발명하지 마세요 :)
동적으로 도구 선택하기 런타임에 관련 도구를 선택하여 성능과 정확도를 향상시킵니다.
이점:
더 짧은 프롬프트 - 관련 도구만 노출하여 복잡성 감소더 나은 정확도 - 모델이 더 적은 옵션에서 올바르게 선택권한 제어 - 사용자 액세스에 따라 도구를 동적으로 필터링 from langchain.agents import create_agent from langchain.agents.middleware import AgentMiddleware, ModelRequest from typing import Callable class ToolSelectorMiddleware ( AgentMiddleware ): def wrap_model_call ( self , request : ModelRequest, handler : Callable[[ModelRequest], ModelResponse], ) -> ModelResponse: """Middleware to select relevant tools based on state/context.""" # Select a small, relevant subset of tools based on state/context relevant_tools = select_relevant_tools(request.state, request.runtime) request.tools = relevant_tools return handler(request) agent = create_agent( model = "openai:gpt-4o" , tools = all_tools, # All available tools need to be registered upfront # Middleware can be used to select a smaller subset that's relevant for the given run. middleware = [ToolSelectorMiddleware()], ) Show 확장 예제: GitHub vs GitLab 도구 선택
from dataclasses import dataclass from typing import Literal, Callable from langchain.agents import create_agent from langchain.agents.middleware import AgentMiddleware, ModelRequest, ModelResponse from langchain_core.tools import tool @tool def github_create_issue ( repo : str , title : str ) -> dict : """Create an issue in a GitHub repository.""" return { "url" : f "https://github.com/ { repo } /issues/1" , "title" : title} @tool def gitlab_create_issue ( project : str , title : str ) -> dict : """Create an issue in a GitLab project.""" return { "url" : f "https://gitlab.com/ { project } /-/issues/1" , "title" : title} all_tools = [github_create_issue, gitlab_create_issue] @dataclass class Context : provider: Literal[ "github" , "gitlab" ] class ToolSelectorMiddleware ( AgentMiddleware ): def wrap_model_call ( self , request : ModelRequest, handler : Callable[[ModelRequest], ModelResponse], ) -> ModelResponse: """Select tools based on the VCS provider.""" provider = request.runtime.context.provider if provider == "gitlab" : selected_tools = [t for t in request.tools if t.name == "gitlab_create_issue" ] else : selected_tools = [t for t in request.tools if t.name == "github_create_issue" ] request.tools = selected_tools return handler(request) agent = create_agent( model = "openai:gpt-4o" , tools = all_tools, middleware = [ToolSelectorMiddleware()], context_schema = Context, ) # Invoke with GitHub context agent.invoke( { "messages" : [{ "role" : "user" , "content" : "Open an issue titled 'Bug: where are the cats' in the repository `its-a-cats-game`" }] }, context = Context( provider = "github" ), ) 주요 사항:
모든 도구를 미리 등록
Middleware가 요청당 관련 하위 집합 선택
구성 요구 사항에 context_schema 사용
추가 리소스