

- PII 유출 방지
- 프롬프트 인젝션 공격 감지 및 차단
- 부적절하거나 유해한 콘텐츠 차단
- 비즈니스 규칙 및 규정 준수 요구사항 시행
- 출력 품질 및 정확성 검증
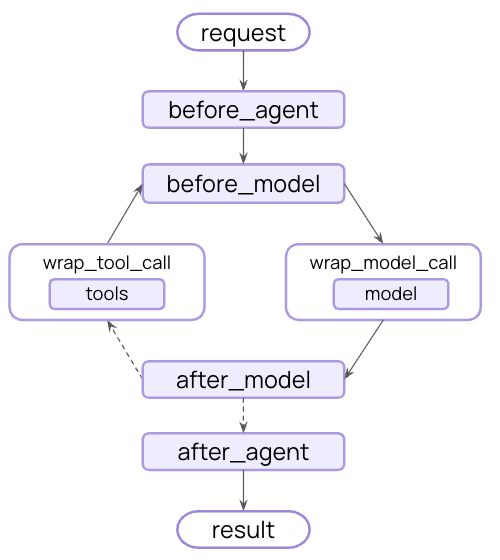
결정론적 guardrails
정규식 패턴, 키워드 매칭 또는 명시적 검사와 같은 규칙 기반 로직을 사용합니다. 빠르고 예측 가능하며 비용 효율적이지만, 미묘한 위반을 놓칠 수 있습니다.
모델 기반 guardrails
LLM 또는 classifier를 사용하여 의미론적 이해로 콘텐츠를 평가합니다. 규칙이 놓치는 미묘한 문제를 포착하지만, 더 느리고 비용이 많이 듭니다.
내장 guardrails
PII 감지
LangChain은 대화에서 개인 식별 정보(PII)를 감지하고 처리하기 위한 내장 middleware를 제공합니다. 이 middleware는 이메일, 신용카드, IP 주소 등과 같은 일반적인 PII 유형을 감지할 수 있습니다. PII 감지 middleware는 규정 준수 요구사항이 있는 의료 및 금융 애플리케이션, 로그를 정제해야 하는 고객 서비스 에이전트, 그리고 일반적으로 민감한 사용자 데이터를 처리하는 모든 애플리케이션에 유용합니다. PII middleware는 감지된 PII를 처리하기 위한 여러 전략을 지원합니다:| 전략 | 설명 | 예시 |
|---|---|---|
redact | [REDACTED_TYPE]으로 대체 | [REDACTED_EMAIL] |
mask | 부분적으로 가림 (예: 마지막 4자리) | ****-****-****-1234 |
hash | 결정론적 해시로 대체 | a8f5f167... |
block | 감지 시 예외 발생 | Error thrown |
내장 PII 유형 및 구성
내장 PII 유형 및 구성
내장 PII 유형:
email- 이메일 주소credit_card- 신용카드 번호 (Luhn 검증)ip- IP 주소mac_address- MAC 주소url- URL
| Parameter | 설명 | 기본값 |
|---|---|---|
pii_type | 감지할 PII 유형 (내장 또는 커스텀) | Required |
strategy | 감지된 PII 처리 방법 ("block", "redact", "mask", "hash") | "redact" |
detector | 커스텀 detector function 또는 regex 패턴 | None (내장 사용) |
apply_to_input | model 호출 전 사용자 메시지 검사 | True |
apply_to_output | model 호출 후 AI 메시지 검사 | False |
apply_to_tool_results | 실행 후 tool 결과 메시지 검사 | False |
Human-in-the-loop
LangChain은 민감한 작업을 실행하기 전에 사람의 승인을 요구하는 내장 middleware를 제공합니다. 이는 중요한 의사결정을 위한 가장 효과적인 guardrails 중 하나입니다. Human-in-the-loop middleware는 금융 거래 및 이체, 프로덕션 데이터 삭제 또는 수정, 외부 당사자에게 통신 전송, 그리고 비즈니스에 중대한 영향을 미치는 모든 작업과 같은 경우에 유용합니다.승인 워크플로우 구현에 대한 자세한 내용은 human-in-the-loop 문서를 참조하세요.
커스텀 guardrails
더 정교한 guardrails를 위해 에이전트 실행 전후에 실행되는 커스텀 middleware를 만들 수 있습니다. 이를 통해 검증 로직, 콘텐츠 필터링 및 안전성 검사를 완전히 제어할 수 있습니다.Before agent guardrails
“before agent” hook을 사용하여 각 호출 시작 시 한 번 요청을 검증합니다. 이는 인증, 속도 제한 또는 처리가 시작되기 전에 부적절한 요청을 차단하는 것과 같은 세션 수준 검사에 유용합니다.After agent guardrails
“after agent” hook을 사용하여 사용자에게 반환하기 전에 최종 출력을 한 번 검증합니다. 이는 모델 기반 안전성 검사, 품질 검증 또는 완전한 에이전트 응답에 대한 최종 규정 준수 스캔에 유용합니다.여러 guardrails 결합
middleware 배열에 추가하여 여러 guardrails를 쌓을 수 있습니다. 순서대로 실행되어 계층화된 보호를 구축할 수 있습니다:추가 리소스
- Middleware 문서 - 커스텀 middleware 완전 가이드
- Middleware API reference - 커스텀 middleware 완전 가이드
- Human-in-the-loop - 민감한 작업에 대한 사람의 검토 추가
- 에이전트 테스트 - 안전성 메커니즘 테스트 전략
Connect these docs programmatically to Claude, VSCode, and more via MCP for real-time answers.